Cuando la respuesta a incidentes está dirigida por personas técnicas, el programa corre el riesgo de atascarse en detalles tácticos y pierde la necesidad de una estrategia clara. El plan de respuesta a incidentes se basa en una estrategia de detección, contención y erradicación de intrusiones e infecciones antes del impacto en datos confidenciales y/u operaciones comerciales.
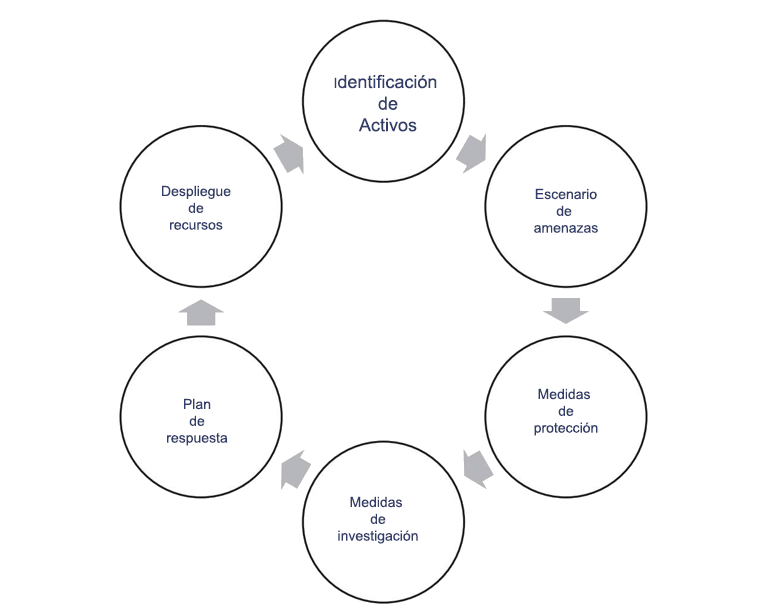
En la imagen anterior, se muestran dos formas de expresar este concepto. Las estrategias se construyen en torno a los activos de interés, pensando en los riesgos y escenarios de ataque que probablemente ocurran. En el análisis se incluyen capacidades fundamentales de protección y prevención, no solo medidas de detección y respuesta. Estas medidas se basan en casos de uso y se derivan de los escenarios de ataque identificados, para desplegar recursos y construir los objetivos estratégicos del plan de respuesta a incidentes.
El análisis y la revisión continuos se llevan a cabo a través de ejercicios de práctica y revisión de los eventos actuales. Las nuevas amenazas o inteligencia sobre los procesos, tácticas y técnicas (PPT) e indicadores de compromiso (IOC) de un atacante empujan al equipo a analizar estos datos en términos de activos afectados. El equipo debe comprender si las capacidades de protección, detección y respuesta son adecuadas. De lo contrario, los procesos alternativos o de compensación deben llenar el vacío.
Las tácticas, que vienen en forma de libros de jugadas (pensar en el ajedrez y sus diferentes estrategias de apertura), libros de ejecución o listas de verificación, describen las acciones específicas esperadas para un tipo de evento o incidente. Los libros de jugadas para ransomware, malware, acceso no autorizado, robo de datos y varios otros escenarios designan acciones específicas requeridas para cumplir con los objetivos del programa.
Cambiando la cultura
Para lograr el objetivo de crear un programa eficaz de respuesta a incidentes, pueden ser necesarios cambios en la forma en que la dirección, la tecnología de la información y el personal de ciberseguridad de la forma de cómo piensan sobre la respuesta a incidentes. Las pruebas anuales y la remediación como enfoque para la preparación de la respuesta se consideran suficientes. Este enfoque es utilizado por la mayoría de las entidades hoy en día.
Los auditores y reguladores también aceptan este enfoque al evaluar entidades. Los auditores de ciberseguridad consideran que esto es suficiente y rara vez cuestionan a los auditados sobre esta noción.
La dirección debe adoptar la respuesta a incidentes como un programa vital para los objetivos de la organización y apoyarlo con los recursos y el compromiso necesarios.
Con demasiada frecuencia, el CEO no considera la ciberseguridad como algo más que una función de costo o un mal necesario. A pesar de una mayor responsabilidad y escrutinio frente a las infracciones y la respuesta a las infracciones, poco parece cambiar.
Para combatir estos desafíos, la gestión eficaz del cambio organizacional es necesario.
Conclusiones
La respuesta efectiva a incidentes define cómo las personas externas, los medios, los reguladores, los clientes y el público ven la competencia del equipo de seguridad cibernética y la entidad. Cuando los programas de respuesta a incidentes fallan, es por varias razones, principalmente por falta de:
Liderazgo
Preparación
Ejecución
El liderazgo es la necesidad número uno y el impulsor de una respuesta exitosa a incidentes.
Los líderes deben asegurarse de que las personas adecuadas formen parte del equipo de respuesta, crear una cultura centrada en los comportamientos necesarios que conducen al éxito y mantener la calma frente a una tormenta. Los líderes no pueden perder el control de las emociones, permitir que los miembros del equipo actúen fuera de su rol en el equipo y desviarse del plan de respuesta a incidentes.
Debe haber una práctica constante, que va desde ejercicios de mesa completos hasta escenarios más pequeños utilizando libros de jugadas específicos. El objetivo es desarrollar la memoria muscular, ayudar a los miembros del equipo a sentirse cómodos con sus roles e infundir confianza en su capacidad para responder adecuadamente.
La migración de los enfoques tradicionales a la respuesta a incidentes, que se centra en ejercicios de simulación anuales, requiere un cambio en la forma en que la organización piensa sobre la preparación y respuesta a incidentes. Cambiar de manera efectiva los comportamientos hacia la respuesta a incidentes en todos los miembros de la entidad es el factor de éxito más importante para la respuesta a incidentes. respuesta.
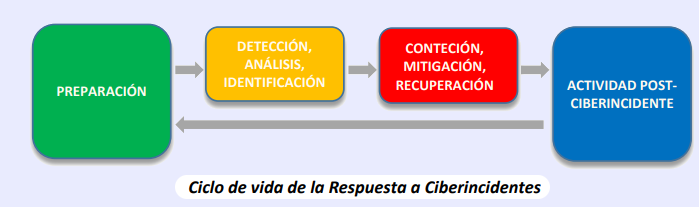
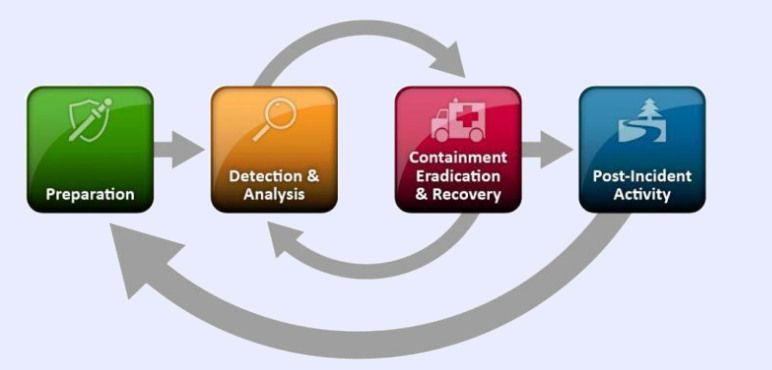
La gestión de ciberincidentes consta de varias fases. La fase inicial contempla la creación y formación de un Equipo de Respuesta a Ciberincidentes (ERC), y la utilización de las herramientas y recursos necesarios.
Durante esta fase de PREPARACIÓN, el organismo público, atendiendo a lo dispuesto en los Anexos I y II del ENS, y previo el correspondiente análisis de riesgos, habrá identificado y desplegado un determinado conjunto de medidas de seguridad.
La adecuada implantación de las antedichas medidas ayudará a detectar las posibles brechas de seguridad de los Sistemas de Información de la organización y su análisis, en la fase de DETECCIÓN, ANÁLISIS E IDENTIFICACIÓN, desencadenando los procesos de notificación a los que hubiere lugar.
La DETECCIÓN de la amenaza, una vez que ha penetrado en el organismo, puede ser realizada por el propio organismo y/o por las sondas desplegadas por el CCN-CERT, que generarán el correspondiente aviso.
La organización, en la fase de CONTENCIÓN, MITIGACIÓN Y RECUPERACIÓN del ciberincidente –y atendiendo a su peligrosidad- deberá intentar, en primera instancia, mitigar su impacto, procediendo después a su eliminación de los sistemas afectados y tratando finalmente de recuperar el sistema al modo de funcionamiento normal. Durante esta fase será necesario, cíclicamente, persistir en el análisis de la amenaza, de cuyos resultados se desprenderán, paulatinamente, nuevos mecanismos de contención y erradicación.
Tras el incidente, en la fase de ACTIVIDAD POST-CIBERINCIDENTE, los responsables del organismo emitirán un Informe del Ciberincidente que detallará su causa originaria y su coste (especialmente, en términos de compromiso de información o de impacto en los servicios prestados) y las medidas que la organización debe tomar para prevenir futuros ciberincidentes de naturaleza similar.
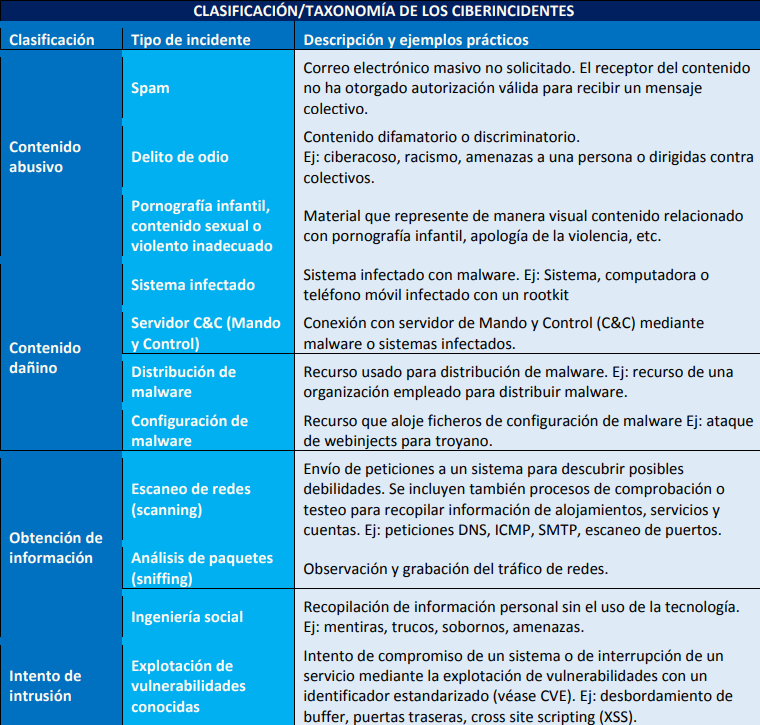
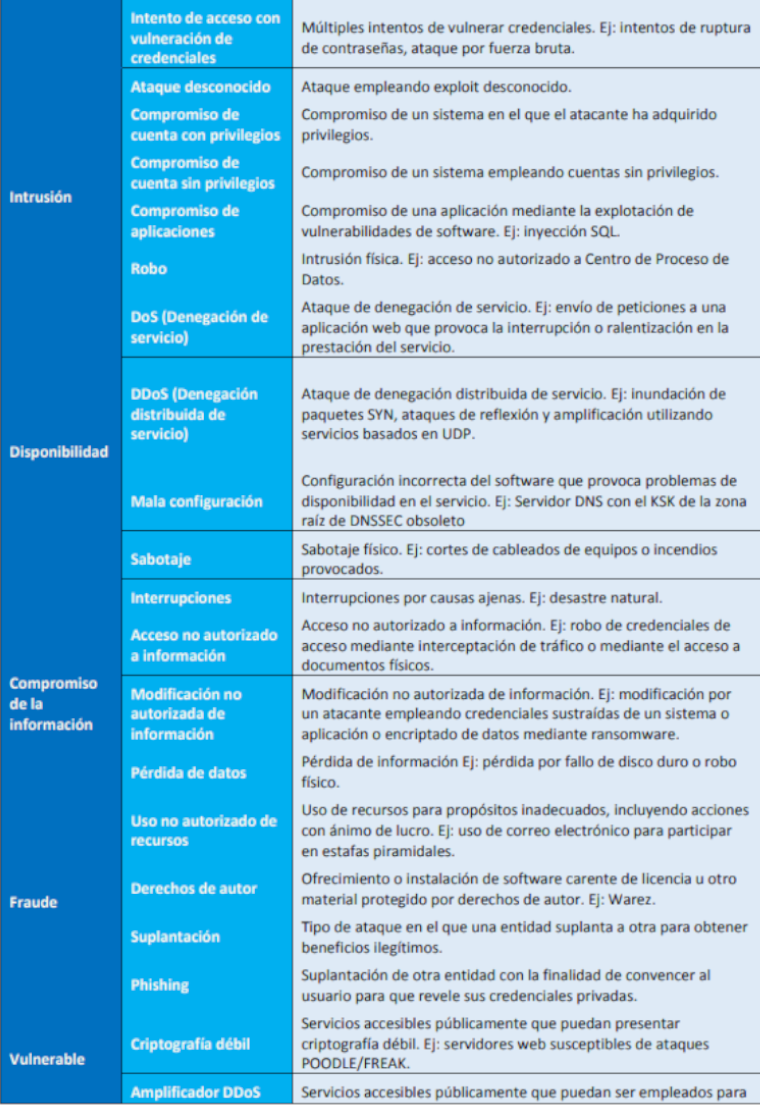
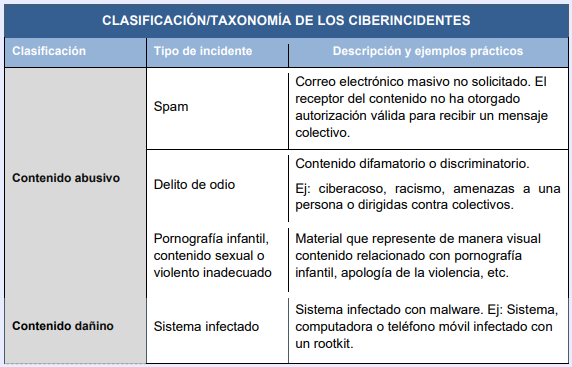
Puesto que no todos los ciberincidentes poseen las mismas características ni la misma peligrosidad, es necesario disponer de una taxonomía de los ciberincidentes, lo que ayudará posteriormente a su análisis, contención y erradicación.
Los factores que podemos considerar a la hora de establecer criterios de clasificación son, entre otros:
Tipo de amenaza: código dañino, intrusiones, fraude, etc.
Origen de la amenaza: Interna o externa.
La categoría de seguridad de los sistemas afectados.
El perfil de losusuarios afectados, su posición en la estructura organizativa de la entidad y, en su consecuencia, sus privilegios de acceso a información sensible o confidencial.
El número y tipología de los sistemas afectados.
El impacto que el incidente puede tener en la organización, desde los puntos de vista de la protección de la información, la prestación de los servicios, la conformidad legal y/o la imagen pública.
Los requerimientos legales y regulatorios.
La combinación de uno o varios de estos factores es determinante a la hora de tomar la decisión de crear un ciberincidente o determinar su peligrosidad y prioridad de actuación.
La tabla siguiente muestra una clasificación de los ciberincidentes:
LA DETECCIÓN DE LOS CIBERINCIDENTES
No es fácil en todos los casos determinar con precisión si se ha producido o no un ciberincidente y, si es así, identificar su tipo y evaluar a priori su peligrosidad.
Básicamente, los indicios de que nos encontramos ante un ciberincidente pueden provenir de dos tipos de fuentes: los precursores y los indicadores. Un precursor es un indicio de que puede ocurrir un incidente en el futuro. Un indicador es un indicio de que un incidente puede haber ocurrido o puede estar ocurriendo ahora.
Algunos ejemplos de precursores son:
Las entradas de log del servidor Web, con los resultados de un escáner de vulnerabilidades.
El anuncio de un nuevo exploit, dirigido a una atacar una vulnerabilidad que podría estar presente en los sistemas de la organización.
Amenazas explícitas provenientes de grupos o entidades concretos, anunciado ataques a organizaciones objetivo.
Los indicadores son muy comunes, tales como:
El sensor de intrusión de una red emitiendo una alerta cuando ha habido un intento de desbordamiento de búfer contra de un servidor de base de datos.
Las alertas generadas por software antivirus.
La presencia de un nombre de archivo con caracteres inusuales.
Un registro de log sobre un cambio no previsto en la configuración de un host.
Los logs de una aplicación, advirtiendo de reiterados intentos fallidos de login desde un sistema externo desconocido la detección de un número importante de correos electrónicos rebotados con contenido sospechoso desviación inusual del tráfico de la red interna.
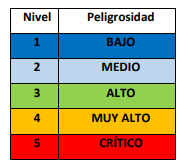
PELIGROSIDAD DE LOS CIBERINCIDENTES
Además de tipificar los ciberincidentes dentro de un determinado grupo o tipo, la gestión de los mismos (asignación de prioridades y recursos, etc.) exige determinar la peligrosidad potencial que el ciberincidente posee. Para ello, es necesario fijar ciertos “criterios” de Determinación de la Peligrosidad con los que comparar las evidencias que se disponen del ciberincidente, en sus estadios iniciales.
El cuadro siguiente muestra el Nivel de Peligrosidad de los Ciberincidentes, atendiendo a la repercusión que la materialización de la amenaza de que se trate podría tener en los sistemas de información de las entidades del ámbito de aplicación del ENS:
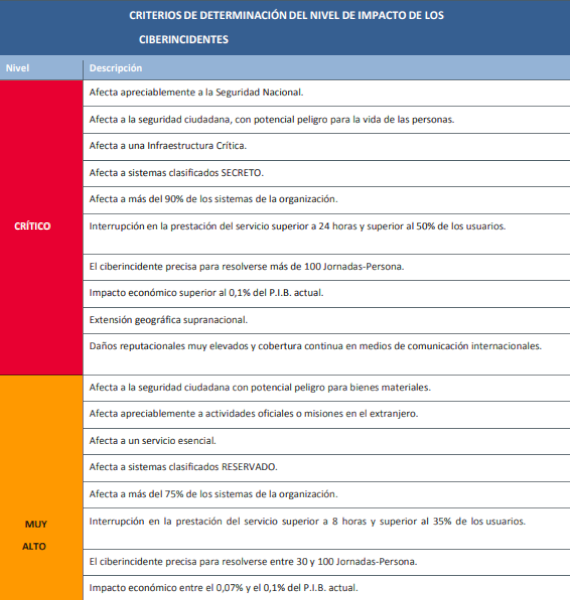
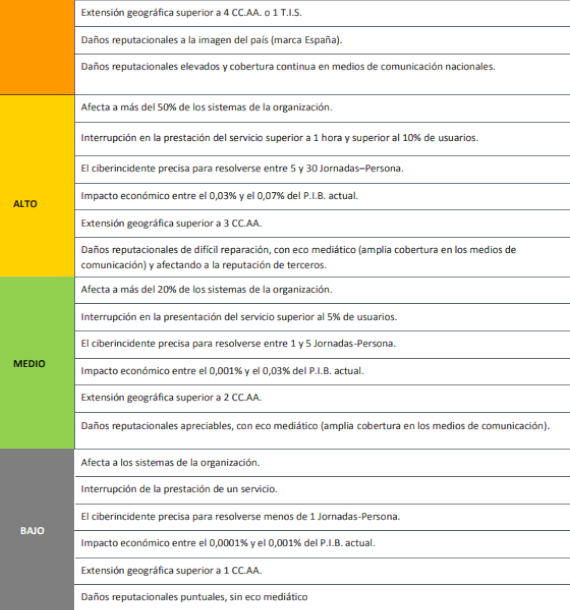
NIVEL DE IMPACTO DEL CIBERINCIDENTE EN LA ORGANIZACIÓN
El ENS señala que el impacto de un ciberincidente en un organismo público se determina evaluando las consecuencias que tal ciberincidente ha tenido en las funciones de la organización, en sus activos o en los individuos afectados.
El cuadro siguiente muestra cómo debe determinar el organismo afectado el Nivel de Impacto Potencial de los Ciberincidentes en la organización:
Los programas de respuesta a incidentes requieren priorización dentro de la seguridad ciberseguridad general el programa y la dirección deben ver la respuesta a incidentes como una función fundamental de la organización. Esto significa hacer más que escribir un plan de respuesta a incidentes y realizar un ejercicio de simulación una vez al año. Operar como una parte de un sistema, lo cual significa que la respuesta a incidentes se somete a revisiones y mejoras continuas de manera regular. El plan debe ser fluido, y cada evento, incidente e incumplimiento al que se responde es una oportunidad para analizar qué salió bien y qué oportunidades de mejora existen. Las pruebas frecuentes del programa y sus procesos producen una retroalimentación beneficiosa. Una hoja de ruta que describe la trayectoria del programa de respuesta a incidentes, desde el desarrollo inicial hasta el programa más maduro respaldado por procesos efectivos, impulsa los proyectos y acciones anuales.
La revisión de su análisis de riesgos, la documentación de otras infracciones y la referencia a recursos como el ciclo de vida de ataques de Mandiant facilitan la generación de escenarios de práctica. No se habla de práctica de alta tecnología. El equipo elige un escenario y luego recorre el proceso de análisis, clasificación y respuesta. Al final de cada recorrido, el equipo identifica lo que funciona y lo que no, y agrega las piezas que faltan en los libros de estrategias de respuesta.
En el peor de los casos, un liderazgo deficiente hace que eventos menos significativos creen más daño de lo esperado.
Sin dinero, un programa de respuesta a incidentes no puede funcionar. El programa requiere las mejores capacidades posibles de detección y respuesta que el presupuesto pueda sostener. Las capacidades incluyen componentes técnicos y personas para establecer y mantener procesos clave. La prevención de pérdida de datos (DLP), la detección y respuesta de punto final (EDR) y la capacidad de capturar paquetes completos, encabezados de flujo, encabezados y tráfico de flujo neto son ejemplos de capacidades tecnológicas.
Entidades de todos los tamaños utilizan a terceros para realizar investigaciones forenses. Estas entidades aportan sus propias herramientas al entorno. Cuanta más evidencia esté disponible para que la analice el equipo forense, mejor. El último elemento de financiación es el tiempo. Los participantes del programa necesitan tiempo para practicar lo siguiente:
Los técnicos deben ensayar las respuestas a los distintos tipos de incidentes y realizar mejoras en los libros de jugadas.
Los líderes deben ensayar escenarios y evaluar la toma de decisiones.
El equipo ejecutivo debe ensayar cómo recibe información, evalúa el escenario y toma decisiones.
La práctica lleva tiempo. Lograr los resultados deseados requiere un compromiso de tiempo significativo. Se necesitan muchas sesiones de práctica para inculcar la capacidad de responder adecuadamente sin pensar demasiado. Un ejercicio teórico anual o semestral no es suficiente. El objetivo es garantizar que las tácticas del plan de respuesta estén arraigadas en el equipo, de modo que ciertas acciones se vuelvan automáticas. Sin práctica enfocada a la respuesta de incidentes el programa no crece ni se perfecciona.
La respuesta a incidentes es la práctica de investigar y corregir campañas de ataque activas en una organización.
Cuando ocurre un ataque cibernético, pueden tener lugar múltiples actividades simultáneamente, y esto puede ser agitado cuando no hay coordinación o procedimientos adecuados de manejo de incidentes. Incluso hasta peligroso.
Sin embargo, prepararse con anticipación y establecer un plan y políticas de respuesta a incidentes claros y fáciles de entender permite que los equipos de seguridad trabajen en armonía. Esto les permite concentrarse en las tareas críticas que limitan el daño potencial a sus sistemas de TI, datos y reputación, además de evitar interrupciones comerciales innecesarias.
Y, sobre todo, lo más importante, cada equipo sabe qué tiene que hacer y cómo hacerlo.
Por tal motivo, tampoco está demás planificar simulacros, donde poner a prueba los protocolos frente a un incidente de seguridad.
Lo primero: Preparar un plan de respuesta a incidentes
Un plan de respuesta a incidentes documenta los pasos a seguir en caso de un ataque o cualquier otro problema de seguridad. Digamos que es el mapa, que debe seguir los responsables de los equipos de seguridad, cuando todo es un caos y la organización está en shock.
Digamos que el peor escenario que podría darse, se dio. Si bien los pasos reales pueden variar según el entorno, un proceso típico, basándonos en un marco de referencia como el de SANS (SysAdmin, Auditoría, Red y Seguridad), incluirá los siguientes pasos: preparación, identificación, contención, eliminación, recuperación, notificación del incidente y revisión de incidentes.
Flujo del proceso de respuesta a incidentes (basado en la plantilla NIST) Imagen NIST
La preparación incluye el desarrollo de un plan con información relevante y los procedimientos reales que seguirá el equipo de respuesta a incidentes informáticos (CIRT) para abordar el incidente.
Éstos incluyen:
Definir los equipos e individuos específicos que son responsables de cada paso del proceso de respuesta a incidentes.
Definir lo que constituye un incidente, incluido lo que justifica qué tipo de respuesta.
Datos y sistemas críticos que requieren más protección y resguardo.
Una forma de preservar los estados afectados de los sistemas afectados con fines forenses.
Procedimientos para determinar cuándo y a quién notificar sobre un problema de seguridad. Cuando ocurre un incidente, puede ser necesario informar a los usuarios afectados, clientes, personal policial, etc. pero esto diferirá de una industria y un caso a otro.
Un plan de respuesta a incidentes debe ser fácil de entender e implementar, así como alinearse con otros planes y políticas de la organización. Sin embargo, la estrategia y el enfoque pueden diferir entre diferentes industrias, equipos, amenazas y daños potenciales. Las pruebas y actualizaciones periódicas garantizan que el plan sea válido y eficaz.
Pasos a seguir un equipo de respuesta a incidentes
Una vez que hay un incidente de seguridad, los equipos deben actuar de manera rápida y eficiente para contenerlo y evitar que se propague a los sistemas limpios. Las siguientes son las mejores prácticas para abordar problemas de seguridad. Sin embargo, estos pueden diferir según el entorno y la estructura de una organización.
El equipo de respuesta a incidentes informáticos
Dentro del caos, es importante asegurarse de que el equipo “multidisciplinario de CIRT”, interno o externo, cuente con las personas adecuadas con las habilidades y la experiencia adecuadas. Y la única forma de cumplir con esto es definiendo las competencias y equipos antes del incidente.
Otra cosa no menos importante es seleccionar un líder de equipo que será la persona focal para dar dirección y asegurarse de que la respuesta vaya de acuerdo con el plan y los plazos. El líder también trabajará de la mano con la dirección y especialmente cuando haya decisiones importantes que tomar en cuanto a las operaciones. Por lo que las características del líder deberán de ser muy concretas con la habilidad de hablar hacia la dirección con un lenguaje menos técnico pero que represente la situación actual. Una persona segura, que trasmita confianza y seguridad.
Identificación del incidente y establecer el tipo y origen del ataque.
Por lo general, todas las empresas tienen previamente identificado y clasificado una serie de incidentes, con sus respectivas respuestas. Por lo que los incidentes menores, serán identificados, que no van a requerir la actuación del CSIRT.
Aquí hay una muestra de cómo podría ser una tabla con una clasificación de los ciberincidentes. En algunas empresas, añaden una columna más para indicar los equipos y tipo de respuesta que requiere cada clasificación.
Una vez tenemos nuestra tabla realizada, estaremos preparados para ante cualquier signo de amenaza, el equipo de RI sabrá como actuar con rapidez para verificar si realmente se trata de un problema de seguridad, ya sea interno o externo, al mismo tiempo que se asegura de contenerlo lo más rápido posible. Las formas típicas de determinar cuándo hay un problema incluyen, entre otras:
Alertas de herramientas de monitoreo de seguridad, mal funcionamiento dentro de los sistemas, comportamientos inusuales, modificaciones de archivos inesperadas o inusuales, copias o descargas, etc.
Informes de usuarios, administradores de sistemas o redes, personal de seguridad o socios o clientes externos externos.
Registros de auditoría con signos de comportamiento inusual del usuario o del sistema, como múltiples intentos fallidos de inicio de sesión, descargas de archivos grandes, uso elevado de memoria y otras anomalías.
Evaluar y analizar el impacto del ataque
El daño que causa un ataque varía según su tipo, la eficacia de la solución de seguridad y la velocidad a la que responde el equipo. La mayoría de las veces, no es posible ver el alcance del daño hasta después de resolver por completo el problema. El análisis debe averiguar el tipo de ataque, su impacto y los servicios que podría haber afectado.
Se considera una buena práctica buscar cualquier rastro que pueda haber dejado el atacante y recopilar la información que ayudará a determinar la línea de tiempo de las actividades. En esta línea es bueno que, durante la planificación del equipo de respuesta a incidente, se verifique que la organización cuenta con sistemas de monitorización que en caso de incidente, puedan dar información que ayude a esclareces el suceso. Por ejemplo un recolector de logs siempre es bienvenido ante un incidente. Tener logs de toda la red implica analizar todos los componentes de los sistemas afectados, captando información relevantes para un análisis forense y determinar qué pudo haber sucedido en cada etapa.
Según la extensión del ataque y los hallazgos, puede ser necesario escalar la incidencia al equipo forense.
Contención, eliminación de amenazas y recuperación
La fase de contención incluye bloquear la propagación del ataque y restaurar los sistemas al estado de operación inicial. Idealmente, el equipo CIRT debería identificar la amenaza y la causa raíz, eliminar todas las amenazas bloqueando o desconectando los sistemas comprometidos, limpiando el malware o virus, bloqueando a los usuarios maliciosos y restaurando los servicios.
También deben establecer y abordar las vulnerabilidades que los atacantes explotaron para evitar futuras ocurrencias de las mismas. Una contención típica implica medidas a corto y largo plazo, así como una copia de seguridad del estado actual.
Antes de restaurar una copia de seguridad limpia o limpiar los sistemas, es importante mantener una copia del estado de los sistemas afectados. Esto es necesario para preservar el estado actual, que puede ser útil cuando se trata de análisis forense. Una vez respaldada, el siguiente paso es la restauración de los servicios interrumpidos. Los equipos pueden lograr esto en dos fases:
Verificar los sistemas y los componentes de la red para comprobar que todos funcionen correctamente
Volver a verificar todos los componentes que estaban infectados o comprometidos y luego limpiados o restaurados para asegurarse de que ahora estén seguros, limpios y operativos.
Notificación y denuncia
El equipo de respuesta a incidencias realiza el análisis, responde e informa. Necesitan explorar la causa raíz del incidente, documentar sus hallazgos sobre el impacto, cómo resolvieron el problema, la estrategia de recuperación mientras pasan la información relevante a la administración, otros equipos, usuarios y proveedores externos.
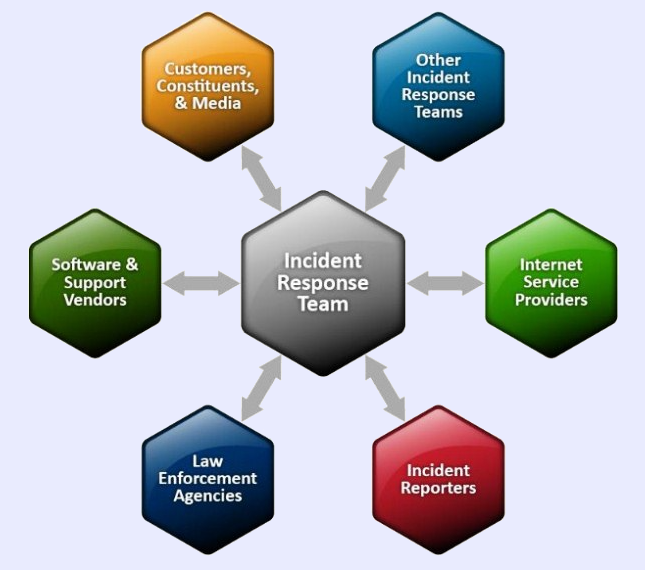
Comunicaciones con agencias y proveedores externos
Si el incidente afecta a datos sensibles o de carácter personal, recordar que notificar a las autoridades (AEPD) o la que corresponda en un plazo inferior a las 72 horas una vez detectado el incidente, además de otras autoridades legales. Por lo que el equipo debe iniciar este proceso, además de contar con un equipo de comunicación, para atender los medios de prensa, clientes, para comunicar de forma coordinada y responsable los detalles del incidente. Por este motivo es necesario seguir los procedimientos establecidos en su política de TI.
Por lo general, un ataque da como resultado el robo, el uso indebido, la corrupción u otra actividad no autorizada de datos sensibles como información confidencial, personal, privada y comercial. Por este motivo, es fundamental informar a los afectados para que puedan tomar precauciones y proteger sus datos críticos, como información financiera, personal y otra información confidencial.
Por ejemplo, si un atacante logra acceder a las cuentas de los usuarios, los equipos de seguridad deben notificarles y pedirles que cambien sus contraseñas. Y abrir una investigación para determinar la gravedad del incidente.
Realizar una revisión posterior al incidente
La resolución de un incidente también ofrece lecciones aprendidas, y los equipos pueden analizar su solución de seguridad y abordar los vínculos débiles para prevenir un incidente similar en el futuro. Algunas de las mejoras incluyen la implementación de mejores soluciones de seguridad y monitoreo para amenazas internas y externas, informando al personal y a los usuarios sobre amenazas de seguridad como phishing, spam, malware y otras que deben evitar.
Otras medidas de protección son ejecutar las herramientas de seguridad más recientes y efectivas, parchear los servidores, abordar todas las vulnerabilidades en las computadoras cliente y servidor, etc.
Estudio de caso de respuesta a incidentes del NIC Asia Bank de Nepal
Una capacidad de detección o una respuesta inadecuadas pueden provocar daños y pérdidas excesivos. Un ejemplo es el caso del NIC Asia Bank de Nepal, que perdió y recuperó algo de dinero después de un compromiso del proceso comercial en 2017.Los atacantes pusieron en peligro el SWIFT y transfirieron fondos fraudulentamente del banco a varias cuentas en el Reino Unido, Japón, Singapur y los EE. UU. .
Afortunadamente, las autoridades detectaron las transacciones ilegales pero solo lograron recuperar una fracción del dinero robado. Si hubiera habido un mejor sistema de alerta, los equipos de seguridad habrían detectado el incidente en una etapa anterior, tal vez antes de que los atacantes tuvieran éxito en el compromiso del proceso comercial.
Dado que se trataba de un problema de seguridad complejo que involucraba a otros países, el banco tuvo que informar a las autoridades policiales y de investigación. Además, el alcance estaba más allá del equipo interno de respuesta a incidentes del banco y, por lo tanto, la presencia de equipos externos, el banco central y otros.
Una investigación forense realizada por equipos externos de su banco central estableció que el incidente pudo haber sido por negligencia interna que expuso sistemas críticos.
Según un informe, los entonces seis operadores habían utilizado la computadora del sistema SWIFT dedicada para otras tareas no relacionadas. Esto puede haber expuesto el sistema SWIFT, lo que permitió a los atacantes ponerlo en peligro. Después del incidente, el banco transfirió a los seis empleados a otros departamentos menos sensibles.
Lecciones aprendidas: El banco debería haber implementado un sistema de vigilancia y alerta además de crear una conciencia de seguridad adecuada entre los empleados y hacer cumplir políticas estrictas.
Conclusión
Una respuesta a incidentes bien planificada, un buen equipo y las herramientas y prácticas de seguridad relevantes brindan a su organización la capacidad de actuar con rapidez y abordar una amplia gama de problemas de seguridad. Esto reduce los daños, las interrupciones del servicio, robo de datos, pérdida de reputación y posibles responsabilidades.
Citando wikipedia: “La ingeniería inversa es el proceso llevado a cabo con el objetivo de obtener información o un diseño a partir de un producto, con el fin de determinar cuáles son sus componentes y de qué manera interactúan entre sí y cuál fue el proceso de fabricación.”
¿Qué utilidades tiene el reversing?
Si bien uno de los usos más conocidos es la detección de vulnerabilidades y el análisis de malware en el ámbito de la seguridad informática, también existen otros motivos del uso del reversing.
Las más comunes son las siguientes:
Descifrar algoritmos criptográficos
Agregar funcionalidades
Análisis de malware
Testing del software
Detección de vulnerabilidades
¿Por dónde empezar?
Es importante conocer los fundamentos y para ello hay que remontarse a la base. Si bien podemos empezar por técnicas de forma directa y aplicar ciertas “metodologías” a la hora de realizar reversing, es necesario tener una buena base, ya que sin la misma nos costará mucho avanzar y pensar de forma creativa a la hora de intentar resolver las problemáticas que nos puedan aparecer cuando aplicamos ingeniería inversa.
Existe mucha información al respecto relativa al reversing, por lo que aquí nos enfocaremos en explicar toda esta información de forma resumida y comprensible para todo el mundo. Se hablará desde compiladores, estructuras de los propios ejecutables, programación a bajo nivel (ASM, C, etc), arquitecturas de hardware entre otras.
En 1954 se empezó a desarrollar un lenguaje que permitía escribir fórmulas matemáticas de manera traducible por un ordenador; lo llamaron FORTRAN (FORmulae TRANslator). Fue el primer lenguaje de alto nivel y se introdujo en 1957 para el uso de la computadora IBM modelo 704.
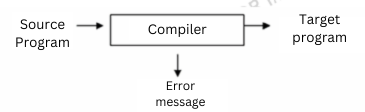
Surgió así por primera vez el concepto de un traductor como un programa que traducía un lenguaje a otro lenguaje. En el caso particular de que el lenguaje que se ha de traducir es de alto nivel y el lenguaje traducido, de bajo nivel, se emplea el término compilador. La tarea de hacer un compilador no fue fácil. El primer compilador de FORTRAN tardó 18 años en desarrollarse. Esto deja de manifiesto la cantidad de investigación que se necesitó realizar para poder llegar a un producto final, un compilador completo, por sencillo que fuera su lenguaje. Toda esta investigación aportó la gran parte de teoría, técnicas y herramientas utilizadas hoy en día en los campos de lenguajes y autómatas. Los compiladores permiten escribir código fuente en lenguajes de alto nivel, es decir, en lenguajes no dependientes de la arquitectura del ordenador en el que se ejecute, así como que el lenguaje sea fácilmente interpretable por un ser humano, lejos de ser una lista de comandos secuenciales, como venía siendo el lenguaje ensamblador u otros lenguajes de bajo nivel.
Los lenguajes de alto nivel han permitido un desarrollo exponencial de software que se adapta a las necesidades de los usuarios y funcionan sin prácticamente cambios en diferentes arquitecturas y tipos de ordenadores. Esta ventaja, junto con otras, como la reutilización de código y disciplinas como la ingeniería de software, nos han llevado a los complejos programas informáticos con entornos visuales de escritorio, así como efectos gráficos y videojuegos en 3D en tiempo real, el desarrollo de complejos sistemas de comunicaciones que llevaron a la creación y utilización en masa de Internet o la capacidad de llevar a cabo software con finalidades matemáticas, médicas o de otros sectores y que nos permiten realizar grandes obras de ingeniería, bioingeniería, química o análisis y diagnósticos médicos, así como muchas otras utilidades del software.
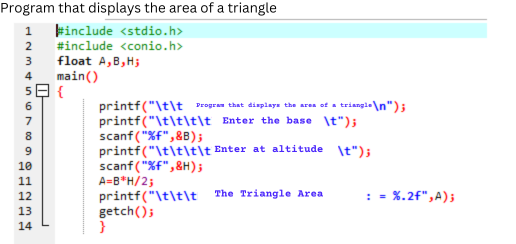
Programa fuente
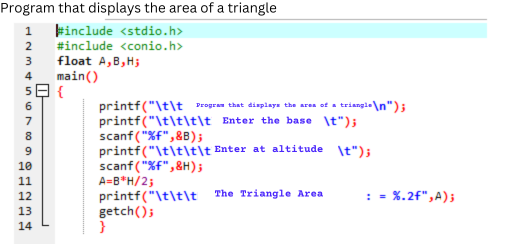
Este código escrito en un lenguaje de alto nivel, en concreto, C++, calcula el área de un triángulo de forma muy sencilla, solicita una serie de argumentos introducido por el usuario por línea de comandos y luego muestra un mensaje con el resultado, o salir con un mensaje de error si no hubiera argumento.
Como se puede observar en la figura, este código de alto nivel permite no solo la utilización de variables con nombre a la libre elección del programador, sino el empleo de comentarios sobre el código, así como la indentación del texto. Estas características facilitan la lectura a las personas, aunque no tenga ninguna trascendencia respecto al código máquina que se ha de generar.
También se puede observar la utilización de estructuras de código, como pueden ser las funciones, que ayudan a la reutilización de código y a su abstracción, pudiendo construir código centrándose en lo particular, para ir resolviendo problemas más generales, además de poder realizar invocaciones recursivas sin necesidad de llevar el control de manera explícita.
Estas facilidades y la proximidad del código fuente al lenguaje natural permiten al desarrollador centrarse en “el qué” debe hacer el software en lugar de en “el cómo” debe implementarlo para que funcione en una máquina con una arquitectura u ordenador en concreto.
Programa objeto / Código ensamblador
Una vez que el compilador ha desarrollado todas las etapas y conseguido generar un código objeto correcto y operativo, se convierte en un código objeto, por lo general, código ensamblador. El lenguaje ensamblador es la representación más cercana al código máquina. La siguiente captura muestra el código ensamblador, que compone el programa objeto, de un programa similar al visto anteriormente del cálculo de un área.
Mnemónico
En informática, un mnemónico o nemónico es una palabra que sustituye a un código de operación (lenguaje de máquina), con lo cual resulta más fácil la programación, es de aquí de donde se aplica el concepto de lenguaje ensamblador.
Un ejemplo común de mnemónico es la instrucción MOV (mover), que le indica al microprocesador que debe asignar datos de un lugar a otro. El microprocesador no entiende palabras, sino números binarios, por lo que es necesaria la traducción del término mnemónico a código objeto.
En muchas ocasiones se puede tomar a nivel de usuario como las teclas de acceso rápido que vemos en las ventanas, por ejemplo en un navegador encontramos el menú típico que dice Archivo, Editar, Ver, entre otras opciones, el mnemónico sería el valor de la letra que esta subrayada, así si presionamos la tecla alt y luego por ejemplo la A, se nos abrirá el menú de archivo, es por esta razón que se puede decir que la A en el menú resulta la tecla mnemónica de Archivo, o la tecla de acceso rápido a la opción Archivo.
El lenguaje Mnemónico también es utilizado en la programación de controladores lógicos programables (PLC), haciendo más rápida y eficiente la construcción de programas de alta complejidad.
Instrucción
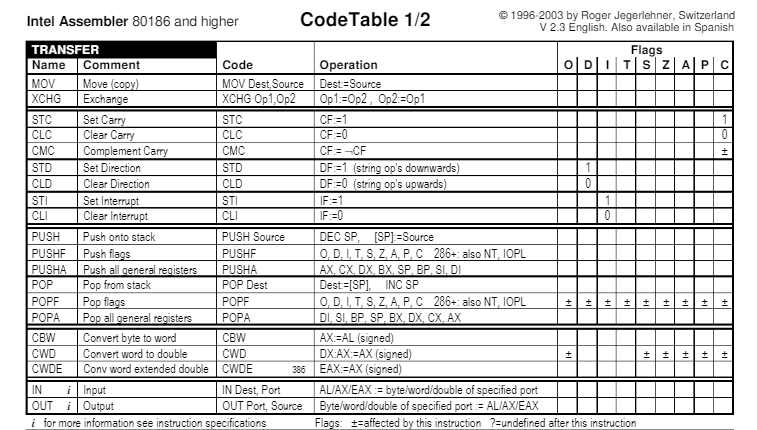
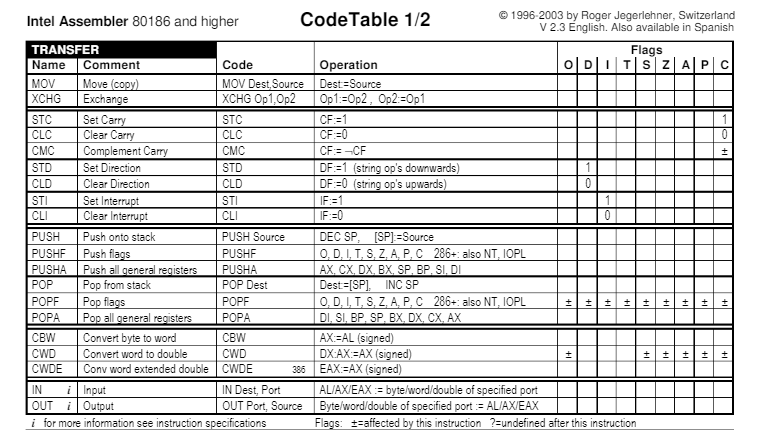
Como se puede apreciar, existen varias diferencias en cuanto a los mnemónicos y operandos, tal y como se puede ver en la siguiente instrucción expresada en ambas sintaxis:
Hay varios tipos de instrucciones, en este caso dejamos la tabla de esamblador de Intel para procesadores 80186 o superiores. Pero también lo hay para procesadores AT&T, entre otros.
Etiquetas
Además de las instrucciones, se puede observar cómo hay etiquetas dentro del código a modo de localizaciones, que se utilizan para las bifurcaciones de código necesario:
Estas etiquetas son traducidas por direcciones de memoria relativas en la fase de construcción del binario final.
Como se puede apreciar en esta captura, podemos ver claramente no solo las etiquetas sino la estructura de un lenguaje ensamblador.
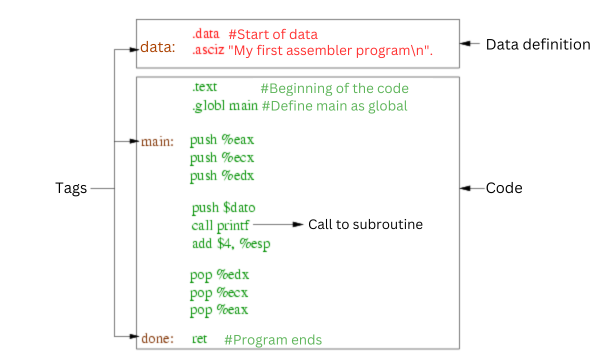
Un programa consta de varias partes diferenciadas. La palabra .data es una directiva y comunica al ensamblador que a continuación se define un conjunto de datos. El programa tan sólo tiene un único dato que se representa como una secuencia de caracteres. La línea .asciz, también una directiva, seguida del string entre comillas es la que instruye al ensamblador para crear una zona de memoria con datos, y almacenar en ella el string que se muestra terminado por un byte con valor cero. Nótese que el efecto de la directiva .asciz no se traduce en código sino que son órdenes para que el ensamblador haga una tarea, en este caso almacenar un string en memoria.
Antes de la directiva .asciz se incluye la palabra dato seguida por dos puntos. Esta es la forma de definir una etiqueta que luego se utilizará en el código para acceder a estos datos.
La línea siguiente contiene la directiva .text que denota el comienzo de la sección de código. Nótese que todas las directivas tienen como primer carácter un punto. La línea con la directiva .globl main comunica al ensamblador que la etiqueta con nombre main será globalmente accesible desde otro programa.
A continuación, se encuentran las instrucciones en ensamblador propiamente dichas. Se pueden ver las instrucciones push parar almacenar un operando en una zona específica de memoria que se denomina la pila.
Al comienzo del código se define la etiqueta main. Esta etiqueta identifica la posición en por la que el procesador va a empezar a ejecutar. Hacia el final del código se puede ver una segunda etiqueta con nombre done.
Una vez creado el fichero de texto con el editor y guardado con el contenido de la figura superior y con nombre miprograma.s, se ejecuta el compilador. Para ello primero es preciso arrancar una ventana con el intérprete de comandos y estando situados en el mismo directorio en el que se encuentra el fichero miprograma.s ejecutar el comando:
gcc -o miprograma miprograma.s
También tienes un emulador en javascript en esta web assembler-simulator donde poder probar código.
Una vez que el código objeto ha sido generado, entran en juego otras herramientas fuera del alcance del compilador, como son el ensamblador y el enlazador de códigos objeto. El ensamblador genera código binario partiendo del programa en lenguaje ensamblador. Es decir, traduce los mnemónicos en los códigos binarios correspondientes. Por otro lado, el enlazador de códigos objeto se encarga de obtener los códigos objeto requeridos por el código objeto en cuestión de las librerías disponibles. Una vez que tiene todas las piezas necesarias, genera un fichero final ejecutable o en forma de librería del sistema.
Conceptos básicos sobre reconstrucción de código
En el tema anterior profundizamos en el proceso de compilación, que convierte el código fuente, escrito en un lenguaje estructurado de alto nivel y fácilmente comprensible por una persona, en código objeto escrito en lenguaje máquina, para la arquitectura escogida y directamente ejecutable.
Ahora conocemos los conceptos básicos sobre diseño, análisis e implementación de lenguajes, así como los detalles sobre las fases por las que pasa un compilador, las técnicas utilizadas para generar y optimizar el código objeto y, en definitiva, todo lo relacionado con el proceso de compilación que genera código objeto partiendo de código fuente.
Ya sabemos cómo el compilador convierte el código fuente a código intermedio, utilizando este finalmente para traducirlo a código máquina de manera directa, tal como se puede apreciar en la siguiente imagen.
Proceso inverso
Tal como hemos visto antes, si podemos realizarlo en un sentido, también podríamos de alguna forma hacer el proceso inverso, pudiendo generar código fuente a partir del código objeto en lenguaje máquina.
Esta labor sí es posible en gran medida, aunque se deben tener en cuenta algunas las limitaciones. En este tema, vamos a referirnos como “Reconstrucción de código” al proceso inverso al que hemos estado estudiando en el tema anterior. Es decir, al proceso de obtener el código fuente a partir del código objeto. Debido a las limitaciones mencionadas, no será posible obtener comentarios, ni nombre de variables, tal y como las describió el desarrollador, puede que ni tan siquiera con el tipo ni el tamaño exacto con el que este lo hizo.
No obstante, sí se va a poder obtener una estructura de código que cumple con bastante exactitud con el comportamiento del programa fuente. Para ello, es necesario conocer las estructuras que el compilador maneja, y con las que traduce el código fuente a código objeto. De esta forma, podremos identificar estas estructuras en el código objeto y ser traducidas a código fuente. Esta traducción depende de:
Arquitectura (INTEL, ARM, x86,etc)
Optimizaciones que pueda sufrir el código
Resumiendo
Si bien ya hemos visto lo fundamental para comprender el mundo de los compiladores, lo que nos resultaba útil para comprender como se construyen los binarios que queremos analizar; ahora es el momento de empezar a comprender las estructuras de datos que nos podemos encontrar a la hora de reconstruir el código fuente partiendo del desemsamblado.
Haciendo un poco de memoria respecto a las fases de compilación, podemos observar en las últimas fases de “Generación de código intermedio”, “Optimización” y “Generación de código” que la idea de reconstrucción del código sería volver al proceso del “código intermedio”.
Debemos tener claro que existen limitaciones cuando volvemos del código final al código intermedio, como la perdida de comentarios del programador, nombres reales de las variables, tipo de variables, el tamaño, etc.
Para poder identificar todas estas estructuras de datos y comprender el código, trataremos aquí como identificarlas manualmente, dependiendo de la arquitectura del código (x86, x86_64, arm, …) y las optimizaciones aplicadas por el compilador.
Cuando tengamos identificadas las estructuras de datos, podremos darles nombres a las mismas mediante nuestro software de ingeniería inversa (radare2, IDA, papel y lápiz? ) para así poder reversear sin volvernos locos y dejar invertir más esfuerzo mental en algo que no merece la pena por no apuntarlo o nombrar las cosas, pudiendo dejar ese esfuerzo en pensar las estructuras mentalmente y al vuelo, en tratar otras cosas más relevantes del reversing, como la lógica de programación del propio código a analizar.
Las estructuras de datos que vamos a analizar serán las típicas del lenguaje de programación C.
versing?
Citando wikipedia: “La ingeniería inversa es el proceso llevado a cabo con el objetivo de obtener información o un diseño a partir de un producto, con el fin de determinar cuáles son sus componentes y de qué manera interactúan entre sí y cuál fue el proceso de fabricación.”
¿Qué utilidades tiene el reversing?
Si bien uno de los usos más conocidos es la detección de vulnerabilidades y el análisis de malware en el ámbito de la seguridad informática, también existen otros motivos del uso del reversing.
Las más comunes son las siguientes:
Descifrar algoritmos criptográficos
Agregar funcionalidades
Análisis de malware
Testing del software
Detección de vulnerabilidades
¿Por dónde empezar?
Es importante conocer los fundamentos y para ello hay remontarse a la base. Si bien podemos empezar por técnicas de forma directa y aplicar ciertas “metodologías” a la hora de realizar reversing, es necesario tener una buena base, ya que sin la misma nos costará mucho avanzar y pensar de forma creativa a la hora de intentar resolver las problemáticas que nos puedan aparecer cuando aplicamos ingeniería inversa.
Existe mucha información al respecto relativa al reversing, por lo que aquí nos enfocaremos en explicar toda esta información de forma resumida y comprensible para todo el mundo. Se hablará desde compiladores, estructuras de los propios ejecutables, programación a bajo nivel (ASM, C, etc), arquitecturas de hardware entre otras.
En 1954 se empezó a desarrollar un lenguaje que permitía escribir fórmulas matemáticas de manera traducible por un ordenador; lo llamaron FORTRAN (FORmulae TRANslator). Fue el primer lenguaje de alto nivel y se introdujo en 1957 para el uso de la computadora IBM modelo 704.
Surgió así por primera vez el concepto de un traductor como un programa que traducía un lenguaje a otro lenguaje. En el caso particular de que el lenguaje que se ha de traducir es de alto nivel y el lenguaje traducido, de bajo nivel, se emplea el término compilador. La tarea de hacer un compilador no fue fácil. El primer compilador de FORTRAN tardó 18 años en desarrollarse. Esto deja de manifiesto la cantidad de investigación que se necesitó realizar para poder llegar a un producto final, un compilador completo, por sencillo que fuera su lenguaje. Toda esta investigación aportó la gran parte de teoría, técnicas y herramientas utilizadas hoy en día en los campos de lenguajes y autómatas. Los compiladores permiten escribir código fuente en lenguajes de alto nivel, es decir, en lenguajes no dependientes de la arquitectura del ordenador en el que se ejecute, así como que el lenguaje sea fácilmente interpretable por un ser humano, lejos de ser una lista de comandos secuenciales, como venía siendo el lenguaje ensamblador u otros lenguajes de bajo nivel.
Los lenguajes de alto nivel han permitido un desarrollo exponencial de software que se adapta a las necesidades de los usuarios y funcionan sin prácticamente cambios en diferentes arquitecturas y tipos de ordenadores. Esta ventaja, junto con otras, como la reutilización de código y disciplinas como la ingeniería de software, nos han llevado a los complejos programas informáticos con entornos visuales de escritorio, así como efectos gráficos y videojuegos en 3D en tiempo real, el desarrollo de complejos sistemas de comunicaciones que llevaron a la creación y utilización en masa de Internet o la capacidad de llevar a cabo software con finalidades matemáticas, médicas o de otros sectores y que nos permiten realizar grandes obras de ingeniería, bioingeniería, química o análisis y diagnósticos médicos, así como muchas otras utilidades del software.
Programa fuente
Este código escrito en un lenguaje de alto nivel, en concreto, C++, calcula el área de un triángulo de forma muy sencilla, solicita una serie de argumentos introducido por el usuario por línea de comandos y luego muestra un mensaje con el resultado, o salir con un mensaje de error si no hubiera argumento.
Como se puede observar en la figura, este código de alto nivel permite no solo la utilización de variables con nombre a la libre elección del programador, sino el empleo de comentarios sobre el código, así como la indentación del texto. Estas características facilitan la lectura a las personas, aunque no tenga ninguna trascendencia respecto al código máquina que se ha de generar.
También se puede observar la utilización de estructuras de código, como pueden ser las funciones, que ayudan a la reutilización de código y a su abstracción, pudiendo construir código centrándose en lo particular, para ir resolviendo problemas más generales, además de poder realizar invocaciones recursivas sin necesidad de llevar el control de manera explícita.
Estas facilidades y la proximidad del código fuente al lenguaje natural permiten al desarrollador centrarse en “el qué” debe hacer el software en lugar de en “el cómo” debe implementarlo para que funcione en una máquina con una arquitectura u ordenador en concreto.
Programa objeto / Código ensamblador
Una vez que el compilador ha desarrollado todas las etapas y conseguido generar un código objeto correcto y operativo, se convierte en un código objeto, por lo general, código ensamblador. El lenguaje ensamblador es la representación más cercana al código máquina. La siguiente captura muestra el código ensamblador, que compone el programa objeto, de un programa similar al visto anteriormente del cálculo de un área.
Mnemónico
En informática, un mnemónico o nemónico es una palabra que sustituye a un código de operación (lenguaje de máquina), con lo cual resulta más fácil la programación, es de aquí de donde se aplica el concepto de lenguaje ensamblador.
Un ejemplo común de mnemónico es la instrucción MOV (mover), que le indica al microprocesador que debe asignar datos de un lugar a otro. El microprocesador no entiende palabras, sino números binarios, por lo que es necesaria la traducción del término mnemónico a código objeto.
En muchas ocasiones se puede tomar a nivel de usuario como las teclas de acceso rápido que vemos en las ventanas, por ejemplo en un navegador encontramos el menú típico que dice Archivo, Editar, Ver, entre otras opciones, el mnemónico sería el valor de la letra que esta subrayada, así si presionamos la tecla alt y luego por ejemplo la A, se nos abrirá el menú de archivo, es por esta razón que se puede decir que la A en el menú resulta la tecla mnemónica de Archivo, o la tecla de acceso rápido a la opción Archivo.
El lenguaje Mnemónico también es utilizado en la programación de controladores lógicos programables (PLC), haciendo más rápida y eficiente la construcción de programas de alta complejidad.
Instrucción
Como se puede apreciar, existen varias diferencias en cuanto a los mnemónicos y operandos, tal y como se puede ver en la siguiente instrucción expresada en ambas sintaxis:
Hay varios tipos de instrucciones, en este caso dejamos la tabla de esamblador de Intel para procesadores 80186 o superiores. Pero también lo hay para procesadores AT&T, entre otros.
Etiquetas
Además de las instrucciones, se puede observar cómo hay etiquetas dentro del código a modo de localizaciones, que se utilizan para las bifurcaciones de código necesario:
Estas etiquetas son traducidas por direcciones de memoria relativas en la fase de construcción del binario final.
Como se puede apreciar en esta captura, podemos ver claramente no solo las etiquetas sino la estructura de un lenguaje ensamblador.
Un programa consta de varias partes diferenciadas. La palabra .data es una directiva y comunica al ensamblador que a continuación se define un conjunto de datos. El programa tan sólo tiene un único dato que se representa como una secuencia de caracteres. La línea .asciz, también una directiva, seguida del string entre comillas es la que instruye al ensamblador para crear una zona de memoria con datos, y almacenar en ella el string que se muestra terminado por un byte con valor cero. Nótese que el efecto de la directiva .asciz no se traduce en código sino que son órdenes para que el ensamblador haga una tarea, en este caso almacenar un string en memoria.
Antes de la directiva .asciz se incluye la palabra dato seguida por dos puntos. Esta es la forma de definir una etiqueta que luego se utilizará en el código para acceder a estos datos.
La línea siguiente contiene la directiva .text que denota el comienzo de la sección de código. Nótese que todas las directivas tienen como primer carácter un punto. La línea con la directiva .globl main comunica al ensamblador que la etiqueta con nombre main será globalmente accesible desde otro programa.
A continuación, se encuentran las instrucciones en ensamblador propiamente dichas. Se pueden ver las instrucciones push parar almacenar un operando en una zona específica de memoria que se denomina la pila.
Al comienzo del código se define la etiqueta main. Esta etiqueta identifica la posición en por la que el procesador va a empezar a ejecutar. Hacia el final del código se puede ver una segunda etiqueta con nombre done.
Una vez creado el fichero de texto con el editor y guardado con el contenido de la figura superior y con nombre miprograma.s, se ejecuta el compilador. Para ello primero es preciso arrancar una ventana con el intérprete de comandos y estando situados en el mismo directorio en el que se encuentra el fichero miprograma.s ejecutar el comando:
gcc -o miprograma miprograma.s
También tienes un emulador en javascript en esta web assembler-simulator donde poder probar código.
Programa binario ejecutable
Una vez que el código objeto ha sido generado, entran en juego otras herramientas fuera del alcance del compilador, como son el ensamblador y el enlazador de códigos objeto. El ensamblador genera código binario partiendo del programa en lenguaje ensamblador. Es decir, traduce los mnemónicos en los códigos binarios correspondientes. Por otro lado, el enlazador de códigos objeto se encarga de obtener los códigos objeto requeridos por el código objeto en cuestión de las librerías disponibles. Una vez que tiene todas las piezas necesarias, genera un fichero final ejecutable o en forma de librería del sistema.
Conceptos básicos sobre reconstrucción de código En el tema anterior profundizamos en el proceso de compilación, que convierte el código fuente, escrito en un lenguaje estructurado de alto nivel y fácilmente comprensible por una persona, en código objeto escrito en lenguaje máquina, para la arquitectura escogida y directamente ejecutable.
Ahora conocemos los conceptos básicos sobre diseño, análisis e implementación de lenguajes, así como los detalles sobre las fases por las que pasa un compilador, las técnicas utilizadas para generar y optimizar el código objeto y, en definitiva, todo lo relacionado con el proceso de compilación que genera código objeto partiendo de código fuente.
Ya sabemos cómo el compilador convierte el código fuente a código intermedio, utilizando este finalmente para traducirlo a código máquina de manera directa, tal como se puede apreciar en la siguiente imagen.
Proceso inverso
Tal como hemos visto antes, si podemos realizarlo en un sentido, también podríamos de alguna forma hacer el proceso inverso, pudiendo generar código fuente a partir del código objeto en lenguaje máquina.
Esta labor sí es posible en gran medida, aunque se deben tener en cuenta algunas las limitaciones. En este tema, vamos a referirnos como “Reconstrucción de código” al proceso inverso al que hemos estado estudiando en el tema anterior. Es decir, al proceso de obtener el código fuente a partir del código objeto. Debido a las limitaciones mencionadas, no será posible obtener comentarios, ni nombre de variables, tal y como las describió el desarrollador, puede que ni tan siquiera con el tipo ni el tamaño exacto con el que este lo hizo.
No obstante, sí se va a poder obtener una estructura de código que cumple con bastante exactitud con el comportamiento del programa fuente. Para ello, es necesario conocer las estructuras que el compilador maneja, y con las que traduce el código fuente a código objeto. De esta forma, podremos identificar estas estructuras en el código objeto y ser traducidas a código fuente. Esta traducción depende de:
Arquitectura (INTEL, ARM, x86,etc)
Optimizciones que pueda sufrir el código
Resumiendo
Si bien ya hemos visto lo fundamental para comprender el mundo de los compiladores, lo que nos resultaba útil para comprender como se construyen los binarios que queremos analizar; ahora es el momento de empezar a comprender las estructuras de datos que nos podemos encontrar a la hora de reconstruir el código fuente partiendo del desemsamblado.
Haciendo un poco de memoria respecto a las fases de compilación, podemos observar en las últimas fases de “Generación de código intermedio”, “Optimización” y “Generación de código” que la idea de reconstrucción del código sería volver al proceso del “código intermedio”.
Debemos tener claro que existen limitaciones cuando volvemos del código final al código intermedio, como la perdida de comentarios del programador, nombres reales de las variables, tipo de variables, el tamaño, etc.
Para poder identificar todas estas estructuras de datos y comprender el código, trataremos aquí como identificarlas manualmente, dependiendo de la arquitectura del código (x86, x86_64, arm, …) y las optimizaciones aplicadas por el compilador.
Cuando tengamos identificadas las estructuras de datos, podremos darles nombres a las mismas mediante nuestro software de ingeniería inversa (radare2, IDA, papel y lápiz? ) para así poder reversear sin volvermos locos y dejar invertir más esfuerzo mental en algo que no merece la pena por no apuntarlo o nombrar las cosas, pudiendo dejar ese esfuerzo en pensar las estructuras mentalmente y al vuelo, en tratar otras cosas más relevantes del reversing, como la lógica de programación del propio código a analizar.
Las estructuras de datos que vamos a analizar serán las típicas del lenguaje de programación C.
Variables
Como seguro que sabemos, las variables sirgen para almacenar valores de nuestra aplicación y existen varios tipos. Los tipos son clasificados en base a un tamaño (ancho de bits) y unos valores mínimos y máximos (en base al signo) ayudan a definir con más exactitud el valor numérico hasta donde abarcan.
Vamos a tratar los tipos de variables en C en arquitecturas de 32bits, excluyendo floats y double.
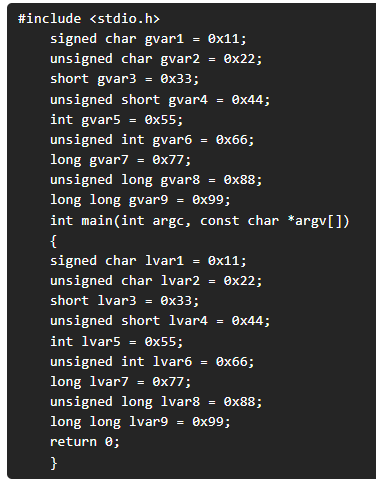
Si construimos una aplicación realizada en código c donde sólo realizamos la definición de variables globales y locales, podemos ver un ejemplo de cómo se sitúan en el binario.
Código aplicación “test”
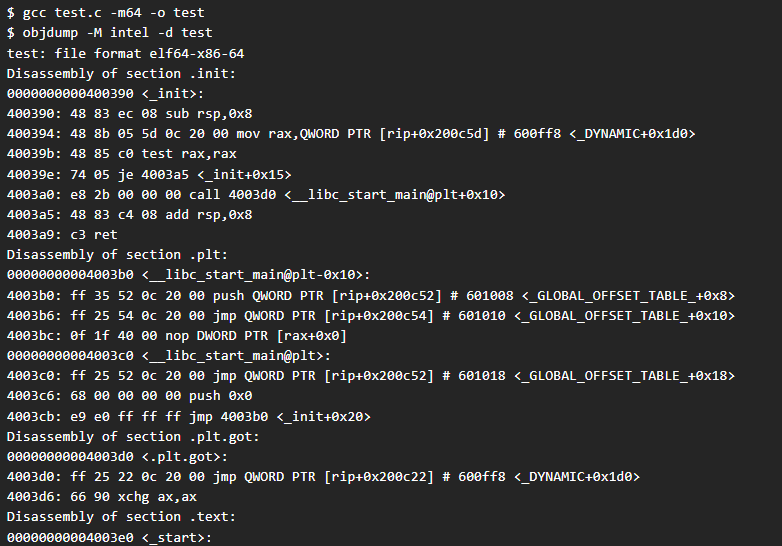
Si compilamos el fichero en 64 bits y analizamos el desemsamblado del mismo en sintaxis Intel nos encontraremos con lo siguiente:
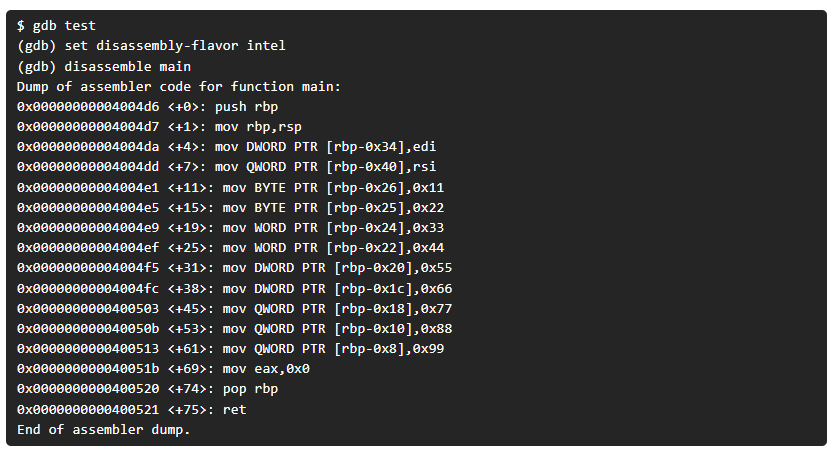
Si analizamos el binario de 64 bits con gdb en la función main se nos mostrará lo siguiente:
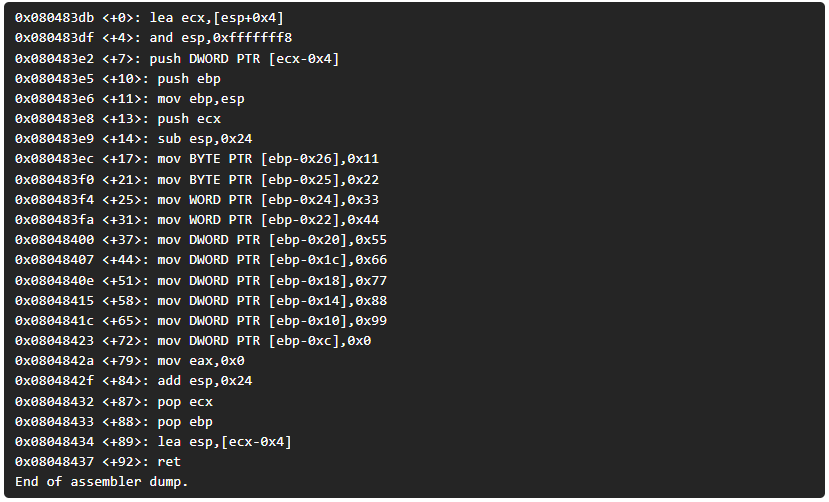
Si lo recompilamos en 32bits (si usas ubuntu/debian probablemente necesites el paquete “libc6-dev-i386”) y tiramos de gdb desde la función main se mostrará lo siguiente:
(gdb) disassemble main
Dump of assembler code for function main:
Ahora, si observamos detenidamente sólo hemos mostrado las variables de tipo local, las cuales hemos tenido que encontrar la entrada main mediante la instrucción de gdb “disassemble main”, ¿pero qué hay de las variables de tipo global?
Para ello vamos a decirle a gdb que nos muestre o “examine” el contenido de la memoria en una dirección dada usando el formato especificado. Esa dirección dada será la dirección de memoria de la variable gvar1 mediante el uso del carácter “&” (AND) y que muestre en contenido en hexadecimal agrupado en una longitud de byte, mostrando un total de 32 bytes.
(gdb) set disassembly-flavor intel
Ahora mostraremos estas variables en hexadecimal con una longitud por defecto, normalmente “word” (palabra) y hasta un total de 8, ya que con esto cubriremos el poder mostrar todas las variables globales.
Otra forma curiosa de ver y confirmar el tamaño de las variables globales, sería compilando la aplicación sin ensamblado/linkado, donde podemos ver en el apartado “size” el tamaño de las variables.
gcc -m32 -S test.c -o test
Conclusiones
Esta lección habla sobre el tema de la ingeniería inversa o reversing, que consiste en el proceso de obtener información o un diseño a partir de un producto para determinar cuáles son sus componentes y cómo interactúan entre sí. Se menciona que uno de los usos más conocidos del reversing es la detección de vulnerabilidades y el análisis de malware en el ámbito de la seguridad informática, pero también se mencionan otros usos como descifrar algoritmos criptográficos y agregar funcionalidades. Se recomienda empezar el estudio del reversing conociendo los fundamentos y remontándose a la base. También se menciona que en un curso de reversing se hablará de compiladores, estructuras de ejecutables, programación de bajo nivel, arquitecturas de hardware, sistemas operativos y kernel e incluso técnicas de explotación y metodologías.