Ahora vamos a ver algunas herramientas para el análisis de vulnerabilidades. En la fase de análisis de vulnerabilidades va a consistir en realizar todas las posibles acciones que nos permitan comprometer a nuestro objetivo, los usuarios y/o su información.
Las vulnerabilidades más comunes son las siguientes:
Pérdida del control de acceso (Broken Access Control)
Fallos criptográficos (Cryptographic Failures)
Inyección (Injection)
Diseño Inseguro (Insecure Desing)
Configuración de seguridad defectuosa (Security Misconfiguration)
Componentes vulnerables y obsoletos (Vulnerable and Outdated Components)
Fallos de identificación y autenticación (Identification and Authentication Failures)
Fallos en el software y en la integridad de los datos (Software and Data Integrity Failures)
Fallos en el registro y la supervisión de la seguridad (Security Logging and Monitoring Failures)
Falsificación de Solicitud del Lado del Servidor (Server-side Request Forguery o SSRF)
Algunas de las herramientas más usadas en esta fase son las siguientes:
Nessus
OWASP Zap Proxy
BugBounty Recon
Vega
BurpSuite
nmap
Detección de Vulnerabilidades en Nmap
Cuando se descubre una nueva vulnerabilidad, frecuentemente se desea escanear la red rápidamente para identificar los sistemas vulnerables antes de que los chicos malos lo hagan. Mientras Nmap no es un escaner de vulnerabilidades completo, NSE es lo suficientemente poderoso para manejar cada verificación de vulnerabilidad demandada. Muchos scripts de detección de vulnerabilidades están disponibles y se publicarán más cuando sean escritos.
Se procede a escanear el objetivo de evaluación. La opción “-n” no realiza una resolución al DNS. La opción “-Pn” trata a todos los hosts como en funcionamiento. La opción “-p-” define el escaneo de los 65535 puertos TCP, y la opción –script=vuln define la utilización de todos los Scripts NSE incluidos en la categoría “vuln”.
# nmap -n -Pn 192.168.0.100 -p- --script=vuln
Otra forma de buscar vulnerabilidades en la red sería
Nmap también tiene la capacidad, a través de NSE, de explotar vulnerabilidades en lugar de solo encontrarlas. Esta capacidad de añadir scripts puede ser muy valiosa para algunas personas, especialmente aquellas haciendo pruebas de penetración.
OWASP Zen Attack Proxy ZAP
El proyecto OWASP (Open Web Application Security Project) es un proyecto abierto y sin ánimo de lucro pensado para mejorar la seguridad de las redes, los servidores, equipos y las aplicaciones y servicios con el fin de convertir Internet en un lugar más seguro. Zed Attack Proxy, ZAP, es una de las herramientas libres de este proyecto cuya principal finalidad es monitorizar la seguridad de redes y aplicaciones web en busca de cualquier posible fallo de seguridad, mala configuración e incluso vulnerabilidad aún desconocida que pueda suponer un problema para la red.
ZAP es una herramienta realmente completa, y si eres nuevo en las auditorías, te será bastante compleja de hacer funcionar, pero una vez que sabes cómo funciona, es una de las mejores que puedes tener en tu arsenal de herramientas. En la web oficial de ZAP nos invitan a ver todos los vídeos de su herramienta donde nos enseñarán cómo funciona y de todo lo que es capaz de hacer.
Por último, ZAP tiene una tienda de addons para aumentar las funcionalidades por defecto de la herramienta, estos add-ons han sido desarrollados por la comunidad que hay detrás de este proyecto.
https://www.zaproxy.org
Nessus
Nessus es un programa de escaneo de vulnerabilidades para todos los sistemas operativos, consiste en un demonio nessusd que realiza el escaneo del sistema operativo objetivo, y nessus el cliente que muestra el avance e informa de todo lo que va encontrando en los diferentes escaneos. Nessus se puede ejecutar tanto a nivel de consola por comandos, o también con interfaz gráfica de usuario. Nessus primero empieza realizando un escaneo de puertos, ya que es lo primero que se suele hacer en un pentesting, Nessus hace uso de la potencia de Nmap para ello, aunque también tiene su propio escáner de puertos abiertos.
Esta herramienta permite exportar los resultados del escaneo en diferentes formatos, como texto plano, XML, HTML y LaTeX, además, toda la información se guarda en una base de datos de “conocimiento” para posteriores revisiones. Actualmente Nessus tiene una versión gratuita muy limitada, y posteriormente una versión de pago mucho más completa y con soporte de la empresa que tiene detrás.
Algunas características muy importantes de Nessus son que tiene muy pocos falsos positivos, tiene una gran cobertura de vulnerabilidades y es utilizada ampliamente por toda la industria de la seguridad, por lo que se actualiza casi continuamente para incorporar las últimas tecnologías y fallos de seguridad de las aplicaciones.
Seccubus
Seccubus es una herramienta que utiliza otros escáneres de vulnerabilidades y automatiza la tarea lo máximo posible. Aunque este no es un escáner propiamente dicho como los anteriores, esta aplicación une varios de los escáneres más populares del mercado, como Nessus, OpenVAS, NMap, SSLyze, Medusa, SkipFish, OWASP ZAP y SSLlabs y nos permite automatizar todos los análisis de manera que desde esta única aplicación podamos realizar un análisis lo más profundo posible, además de poder programas análisis a intervalos regulares para asegurarnos de que todos los equipos y las redes están siempre correctamente protegidas y, en caso de que algo vaya mal, recibir avisos en tiempo real.
https://www.seccubus.com
Uniscan
Una de las aplicaciones más conocidas dentro de este tipo de aplicaciones para buscar vulnerabilidades es Uniscan. Las principales características de esta herramienta son que es una de las más sencillas para la búsqueda de vulnerabilidades, pero también una de las más potentes, siendo capaz de buscar fallos de seguridad críticos en los sistemas. Es capaz de localizar fallos desde el acceso a los archivos locales, hasta la ejecución de código remoto, e incluso es capaz de cargar archivos de forma remota a los sistemas vulnerables. También permite realizar un seguimiento de huella digital y listar los servicios, archivos y directorios de cualquier servidor.
Ejemplo de uso
Metasploit
Metasploit es una de las mejores herramientas de código abierto que nos permite localizar y explotar vulnerabilidades de seguridad en sistemas y servicios, esta herramienta es fundamental para realizar pentesting. El proyecto más popular es Metasploit Framework, el cual se encuentra instalado de manera predeterminada en distribuciones Linux como Kali Linux. Gracias a la potencia de Metasploit, podremos realizar pruebas de penetración a servicios, aplicaciones y demás ataques.
Es una de las herramientas que debes tener en tu arsenal de herramientas para realizar pentesting, se complementa con el resto de herramientas que hemos hablado anteriormente. Metasploit tiene una gran comunidad detrás, y se han diseñado herramientas basadas en esta para facilitar enormemente todas las tareas automatizándolas.
Esta herramienta ya la hemos visto, pero básicamente se utilizar con la opción “search exploit” y debemos de poner el servicio o programa que buscamos, por ejemplo nginx.
Searchexploit
Es una herramienta muy potente, y la podemos ejecutar desde la consola cómodamente.
Bueno, si ya has probado todas las opciones que ofrece Google, entonces es hora de conocer GHDB
Para encontrar más ejemplos de Dorks, GHDB es un fantástico recurso. GHDB (Google Hacking DataBase) es un proyecto open-source que recopila una serie de dorks conocidos que pueden revelar aquella información interesante y probablemente confidencial que se encuentra disponible públicamente en internet.
Este proyecto es mantenido por Offensive Security, una organización muy reconocida en el mundo de la ciberseguridad creadores de Kali Linux. Dentro de este proyecto se podrán ver dorks bastante avanzados clasificados en diferentes categorías y que sin duda serán útiles a la hora de realizar investigaciones.
Te invitamos a buscar sitios con intext: “index of” “.sql” te sorprenderá ver los resultados.
Nota: Antes de que te veas tentad@ por oportunidades de acceder a información de otros, recordarte que este material es con fines educativos, un pentester prueba sus artes siempre con autorización del propietario del material al que se accede, de otra forma estás incurriendo en un delito.
El sistema de Crawling de Google, indexa todo tipo de contenido que hay en Internet, hace que saber buscar eficiente y precisamente sea de gran valor. Google dorks permite ayudar a encontrar rápidamente cualquier cosa de Internet y como en muchas otras ocasiones, serán la pericia y el ingenio del hacker los que determinarán una investigación exitosa. Además, hay que tener muy en cuenta que todo lo visto en este laboratorio se puede aplicar también a otros buscadores. La metodología será idéntica y tan solo se encontrarán diferencias en la sintaxis de sus dorks. Por tanto, en una investigación, no hay que subestimar las ganancias que puede traer consultar Bing, Yahoo y DuckDuckGo para continuar avanzando.
Desde un punto de vista defensivo, será interesante practicar el egosurfing, es decir buscarnos a nosotros mismos (A nivel personal o como organización) y ver que información se está haciendo pública sin desearlo. A partir de ahí, habría que revisar los ajustes de privacidad (Por ejemplo si estamos haciendo público algo a través de Google Drive) , o si se trata de nuestro propio sitio web, editar el archivo robots.txt
Shodan
https://www.shodan.io
Sabemos que Google no es el único motor de búsqueda existente. Existen varias alternativas a este como DuckDuckGo, así también podemos encontrarnos con otros motores que tienen propósitos específicos. Shodan tiene como objetivo el ubicar a todo tipo de dispositivos que estén conectados a Internet, es decir, desde routers, APs, dispositivos IoT hasta cámaras de seguridad. Te mostraremos cómo acceder a este portal y sacarle el máximo provecho mediante consejos esenciales para conseguir mejores resultados de búsqueda.
A Shodan se lo conoce como el motor de búsqueda de los hackers, con el objetivo de realizar tareas de investigación de nuevas vulnerabilidades. No obstante, esta herramienta puede usarse con fines maliciosos a razón de la cantidad de información detallada que se proporciona con cada búsqueda realizada. Auditores, investigadores y toda persona que necesite información sobre dispositivos en general, puede recibir información muy útil en cuestión de minutos.
Cómo empezar a buscar en Shodan
Simplemente, debes entrar a la pestaña «Explore» (Explorar) y verás tres listas: las categorías más populares, las búsquedas específicas más populares y aquellas que se han compartido recientemente. Lo que debes hacer es clic en lo que quieras buscar y obtendrás los resultados en segundos.
Categorías populares: como vemos, las tres categorías que más saltan en las búsquedas son los Sistemas de Control Industrial, las bases de datos y los servidores de videojuegos. En cualquiera de estas y otras categorías, podremos especificar a la hora de buscar cuáles fueron hackeadas, la cantidad de dispositivos por país, por sistema operativo utilizada y mucho más.
Búsquedas más populares: es lo que más se busca en el portal de Shodan todos los días. El dato curioso que podemos percibir, de buenas a primeras, es que dicho portal es utilizado en gran medida para localizar cámaras de seguridad. Así, se puede conseguir acceso al administrador de dichas cámaras para que se pueda visualizar en tiempo real lo que ocurre con ellas y hacer, básicamente, lo que queramos.
Búsquedas compartidas recientemente: son aquellas que se están realizando con más frecuencia de manera reciente.
¿Qué información encontramos con cada búsqueda?
En un vistazo, este portal nos brinda todo lo que necesitamos saber acerca del resultado específico que hemos conseguido. Veamos un ejemplo de búsqueda de organizaciones que cuenten con servidores Apache alrededor del mundo:
Recuerda que con una cuenta de pago puedes filtrar las búsquedas por país y ciudad.
Por ejemplo geolocalizada en Sevilla encontramos más de 7.532 servidores de apache publicados
Uso de filtros de búsqueda
Los filtros de búsqueda nos ayudan muchísimo a tener un control mayor de lo que buscamos y de lo que podremos obtener. Se puede filtrar por país, dirección IP, número de puerto, nombre de host y más. Te mostramos unos casos:
Búsqueda por país. Por ejemplo, España
country:es
Búsqueda por ciudad. Por ejemplo, Madrid
city:madrid
Búsqueda por sistema operativo. Por ejemplo, Windows
os:windows
Búsqueda por número de puerto. Por ejemplo, 25
port:25
¿Shodan representa un peligro para las organizaciones?
Tras ver toda esta información sobre este buscador, pueden surgir preguntas acerca de si este es peligro o no. Y lo cierto es que sí, puede llegar a ser muy peligroso si se utiliza con malas intenciones.
Estamos ante un buscador que puede indexar gran cantidad de dispositivos, como pueden ser:
Muchos modelos de webcams.
Señalización para vías.
Algunos modelos de routers.
Herramientas Firewall.
Circuitos cerrados de televisión.
Sistemas de control a nivel industrial, incluso para centrales nucleares o eléctricas.
Electrodomésticos.
Dispositivos IoT
En muchas ocasiones, los dispositivos se encuentran conectados a internet sin que pensemos en ello como tal, lo que puede conllevar riesgos para la seguridad. Por lo cual es necesario contar con buena protección en nuestros equipos y router. Puesto que lo que más se hackea desde Shodan, son webcams, y permiten sacar fotos o vídeos en los entornos de los usuarios, lo que puede conllevar, información personal y privada.
La enumeración DNS es el proceso de localizar todos los servidores DNS y sus correspondientes registros de una organización.
NSlookup, DNSstuff, ARIN, y Whois pueden ser utilizadas para obtener información que luego puede ser utilizada para realizar la enumeración DNS.
NSlookup y DNSstuff
Una poderosa herramienta con la que debes estar familiarizado es NSlookup. Esta herramienta consulta la información de los registros de los servidores DNS. Está incluido en los Sistemas Operativos Unix, Linux y Windows. Herramientas de hacking, como Sam Spade también incluyen herramientas NSlookup.
Esta búsqueda revela todos los alias para los registros de sevilla.org por ejemplo y la dirección IP de cada uno de sus servidores web, base de datos, entre otros. Incluso puede descubrir todos los nombres sus servidores y las direcciones IP asociadas.
Comprendiendo Lookups, Whois y ARIN
El Whois, evolucionó a partir del sistema operativo Unix, pero ahora se puede encontrar en muchos sistemas operativos, así como en kits de herramientas de hacking de Kali y en Internet. Esta herramienta identifica quien tiene registrado un nombre de dominio utilizados para el correo electrónico o sitios web.
La Corporación de Internet para Nombres y Números Asignados (ICANN) requiere el registro de nombres de dominio para garantizar que sólo una única empresa utiliza un nombre de dominio específico.
La herramienta Whois consulta la base de datos de registro para recuperar la información de contacto de la persona u organización que mantiene un registro de dominio.
Usando Whois
Para utilizar la herramienta Whois para reunir información sobre el registrador o un nombre de dominio:
Introducir la URL de tu empresa objetivo en el campo Enter Domain or IP:
Ahora al dar clic en el botón de WHOIS. Podrás ver los resultados y determina lo siguiente: Dirección registrada Contactos técnicos y DNS Email de contacto Teléfono de contacto Fecha de vencimiento Visita el sitio web de la empresa y revisa si la información de contacto de WHOIS coincide con cualquiera de los nombres de los contactos, direcciones y direcciones de correo electrónico que aparecen en el sitio web. Si es así, puedes utilizar Google o LinkedIn para buscar en los nombres de los empleados o direcciones de correo electrónico. Puedes aprender acerca de la convención de nombres de correo electrónico utilizada por la organización, y si hay alguna información que no debería estar a disposición del público.
ARIN
ARIN es una base de datos que incluye información tal como los propietarios de direcciones IP estáticas. La base de datos de ARIN se puede consultar mediante la herramienta Whois, tal como la que se encuentra en www.arin.net. Ten en cuenta que otras regiones geográficas fuera de América del Norte tienen sus propios registros de Internet, tales como:
RIPE NCC (Europa, Oriente Medio, y partes de Asia Central)
LACNIC (Registro de direcciones de Internet para América Latina y el Caribe)
APNIC (Centro de Información de Red de Asia y el Pacífico).
Las pruebas de penetración son el proceso de evaluar prácticamente las vulnerabilidades de seguridad en las aplicaciones para establecer si los atacantes pueden explotarlas y comprometer los sistemas.
Por lo general, esto ayuda a los investigadores, desarrolladores y profesionales de la seguridad a identificar y abordar las vulnerabilidades que permitirían a los delincuentes atacar o comprometer la aplicación u otros recursos de TI.
En la práctica, las pruebas de penetración implican realizar varias pruebas o evaluaciones de seguridad en servidores, redes, sitios web, aplicaciones web, etc. Si bien esto puede diferir de un sistema y un objetivo de prueba a otro, un proceso típico incluye los siguientes pasos:
Listado de posibles vulnerabilidades y problemas que los atacantes pueden aprovechar.
Priorizar u organizar la lista de vulnerabilidades para determinar la criticidad, el impacto o la gravedad del posible ataque.
Realizar pruebas de penetración desde dentro y fuera de su red o entorno para determinar si puede utilizar la vulnerabilidad específica para acceder a una red, servidor, sitio web, datos u otro recurso de forma ilegítima.
Si puedes acceder al sistema sin autorización, el recurso es inseguro y requiere abordar la vulnerabilidad de seguridad respectiva. Después de solucionar el problema, realiza otra prueba y repite hasta que no haya ningún problema.
La prueba de penetración no es lo mismo que prueba de vulnerabilidad.
Mientras que los equipos utilizan las pruebas de vulnerabilidad para identificar posibles problemas de seguridad, las pruebas de penetración encontrarán y explotarán las fallas, por lo que establecerán si es posible atacar un sistema. Idealmente, las pruebas de penetración deberían detectar las fallas de seguridad críticas y, por lo tanto, brindar la oportunidad de corregirlas antes de que los piratas informáticos las encuentren y exploten.
Existen varias herramientas de prueba de penetración comerciales y gratuitas que puede utilizar para establecer si su sistema es seguro. Para ayudarlo a seleccionar la solución adecuada, a continuación se muestra una lista de las mejores herramientas gratuitas de prueba de penetración que suelen también venir con Kali Linux.
Clasificaremos las herramientas según este esquema en 4 fases:
Clasificación de herramientas según:
Recopilación de información
Análisis de vulnerabilidades
Post Explotación
Explotación
Necesitarás tener tu Kali Linux operativo para poder hacer este laboratorio.
Cuando lo tengas, dale a Siguiente.
Recopilación de información
Se trata de la fase principal del pentest. En esta fase recolectamos toda la información posible de nuestro objetivo, haciendo uso de diversas técnicas, tales como:
Escaneo de dominios/IPs/puertos/versiones/servicios
Dorking
Uso de herramientas automatizadas para obtener información de nuestro objetivo
Obtención de metadatos
Algunas de las herramientas más utilizadas en esta fase son:
Nmap
Dnsmap
Dnsrecon
Recon-ng
La herramienta de nmap es la principal y ya la hemos visto. Es una herramienta de líneas de comandos que permite saber si existen puertos abiertos. Recordar que un puerto en un servicio por el cual se aceptan peticiones. Muchas veces, si logramos conocer el servicio y su versión podemos aprovecharnos de versiones no actualizadas para poder explotarlas. Básicamente es lo que hacen los programas automatizados de búsqueda de vulnerabilidades.
Otra herramienta interesante para probar es Sifter es una poderosa combinación de varias herramientas de prueba de penetración. Comprende una combinación de OSINT y herramientas de recopilación de inteligencia, así como módulos de análisis de vulnerabilidades. El Sifter combina múltiples módulos en un conjunto integral de pruebas de penetración con la capacidad de rápidamente escanear en busca de vulnerabilidades, realice tareas de reconocimiento, enumere hosts locales y remotos, verifique firewalls y más.
Características principales
Sifter consta de 35 herramientas diferentes y la capacidad de escanear sitios web, redes y aplicaciones web.
Utiliza Attack Surface Management (ASM) para mapear la superficie de ataque.
Tiene una herramienta de explotación para explotar éticamente las vulnerabilidades encontradas.
Capacidades avanzadas de recopilación de información
La herramienta funciona en Ubuntu, Linux, Windows, Parrot, Kali Linux y otros.
Una gran cantidad de módulos de prueba de penetración, por lo tanto, altamente escalables y personalizables.
No podríamos hablar de recolección de información, sin mencionar a Google Dorking.
Google Dorking ( También conocido como Google Hacking) es una técnica que consiste en aplicar la búsqueda avanzada de Google para conseguir encontrar en internet aquella información concreta a base de ir filtrando los resultados con operadores (Los conocidos como dorks).
Google Dorking es una técnica de Osint , y es habitualmente empleado por periodistas, investigadores y por supuesto en el ámbito de la ciberseguridad. Dentro del ámbito de la ciberseguridad, es una técnica muy interesante para la fase de Recon, pues, gracias a ella, se podrán enumerar diferentes activos, buscar versiones vulnerables, conocer datos de interés e incluso encontrar fugas de información del objetivo en cuestión.
Por tanto, se emplea en seguridad ofensiva y defensiva. Es una habilidad muy recomendable de entrenar para todos los hackers, ya que, se trata de una técnica muy sencilla pero con resultados muy potentes, “solo” conociendo los dorks y como emplearlos de forma óptima se podrá obtener cualquier información que Google haya indexado con sus robots.
Cabe mencionar que el Dorking, no es algo exclusivo de Google. Otros motores de búsqueda como Bing o DuckDuckGo también funcionan con esta técnica, y además, dado que cada uno tiene diferentes métodos para indexar, los resultados que devuelvan, a dorks equivalentes, pueden variar, lo que aumentará la riqueza de nuestras investigaciones.
¿Qué información se puede encontrar?
Hay que tener en cuenta que Google cuenta con un sistema de crawling muy poderoso, que indexa todo lo que haya en Internet (Incluida información sensible), por ello tener habilidad con Google Dorking permitirá rescatar información de gran valor para investigaciones.
Información sobre personas/organizaciones
Contraseñas
Documentos confidenciales
Versiones de servicios vulnerables
Directorios expuestos
En resumen, los robots de Google indexaran todo lo que se encuentren por Internet y que los ficheros robots.txt no les impidan que indexen.
¿Cómo se utiliza?
Para utilizar Google Dorking tendremos que usar la barra de búsqueda (como siempre) añadiéndole los dorks y palabras clave por las que filtrar. Cuantos más dorks vayan en una búsqueda y más concretos sean, mas refinado será el resultado. Podemos pensarlo como una diana, en la que, una búsqueda simple dará muchas coincidencias y estaremos lejos del objetivo, y será a medida que se van incluyendo más dorks, cuando nos acerquemos más a este.
Operadores
Para poder aplicar con éxito Google Hacking, será necesario comprender perfectamente el funcionamiento de los operadores. Los operadores son comandos que se utilizan para filtrar de diferente modo la información que se encuentra indexada, permitiendo lo que se conoce como búsqueda avanzada.
A continuación se verán algunos de los operadores más utilizados y su propósito. Además es interesante tener en cuenta que el uso de los operadores puede ser combinado para que la búsqueda sea más refinada.
OPERADOR
UTILIDAD
Ejemplo
""
Búsqueda con coincidencia exacta
“sevilla.org”
site:
Busca en el sitio web especificado en concreto
site:sevilla.org
filetype:
Busca resultados que tienen la extensión de archivo especificada (pdf,txt,xlsl,…)
filetype:pdf
ext:
Misma utilidad que filetype
ext:pdf
inurl:
Busca la palabra especificada en una URL
inurl:dorking
intext:
Resultados con páginas en cuyo contenido aparece la palabra especificada
intext:dorking
intitle:
Resultados con páginas en cuyo título aparece la palabra especificada
intitle:dorking
allinurl:
Busca todas las palabras especificadas en una URL
allinurl:Google Dorks
allintext:
Resultados con páginas en cuyo contenido aparecen todas las palabras especificadas
allintext:Google Dorks
allintitle:
Resultados con páginas en cuyo título aparecen todas las palabras especificadas
allintitle:Google Dorks
-
Simbolo de exclusion, se excluirá de los resultados lo que vaya a continuación de el
dorking -Google
*
Se usa como comodín, el asterísco representa que puede ser sustituido por cualquier palabra
site:*.ejemplo.com
cache:
Mostrará la versión en caché de la web en cuestión
cache:sevilla.org
OR
Operador lógico, también se puede representar por |
ext:pdf OR ext:txt
AND
Operador lógico, normalmente se deja el espacio en blanco
Ahora que ya conoces el entorno que suelen utilizar los pentesters, y que conoces alguna de las herramientas que se utilizan como Mestasploit o Nmap, para el reconocimento de puertos, es hora de conocer los frameworks en lo que se basa el pentesting.
Si bien es verdad que el arte del hacking nació como algo espontáneo sin procedimentos, al día de hoy las técnicas del “test de penetración” (pentesting en inglés), están de alguna forma reguladas.
Por lo que es recomendable conocer los principales frameworks sobre los que se fundamentan.
En la lección anterior vimos que las fases del pentester que se componen de una serie de pasos como podemos ver a continuación:
Como se puede ver, cuando estamos frente a una explotación real, solo cambian los últimos dos pasos, el paso 11 en donde se borran los logs y se limpia la evidencian de que hemos accedido y el paso 12 que en lugar de terminar con un reporte. Se asegura la persistencia mediante puertas traseras en los sistemas.
Si bien con la explosión de cibercrimen estamos asistiendo a una nueva modalidad, por ejemplo en los ataques de ransomware, una vez que se ejecutan y explotan las vulnerabilidades y se compromete la mayor cantidad de dispositivos posibles, el paso 12 se modifica por exfiltración de datos en algunos casos y luego cifrado de la información mediante un ransomware.
En este laboratorio haremos un repaso rápido de los principales marcos (framewrosk) en los que se basan los pentesters. En dichos marcos, tomarlos como guías indican paso a paso lo que se debe de hacer, y detallan cada uno de estos 12 pasos en profundidad.
Esta claro que en muchos frameworks encontrarás 12 pasos, en otros 10 y otros lo pueden resumir en 6. Por lo que si buscas información de los pasos para realizar un pentester, te podrá salir información muy diferente, ya que cada uno de esos pasos son extraídos de algún framework en particular.
Los marcos más utilizados
ISSAF
El método ISAAF o Information Systems Security Assessment Framework es aquel en el que el ataque se realiza en base a la información organizada según los criterios de expertos en ciberseguridad.
NIST
Concibe las pruebas de intrusión como un paquete de pruebas de seguridad que se realizan utilizando los mismos métodos y herramientas que emplean los atacantes reales. Se emplean para verificar las vulnerabilidades descubiertas en fases anteriores y sirven para demostrar como las vulnerabilidades pueden ser explotadas iterativamente para ganar privilegios de accesos al sistema.
PTES
El Penetration Testing Execution Standard o PTES es uno de los métodos más empleados a la hora de iniciarse en pentesting. Se basa en el uso de estándares desarrollados por profesionales del sector cualificados y se ha establecido como un modelo a seguir en libros o cursos de aprendizaje.
OSSTMM
El Open Source Security Testing Methodology Manual o Manual de la Metodología Abierta de Testeo de Seguridad es un manual realizado por más de 150 expertos que hace especial hincapié en el desarrollo de un marco de trabajo que permita realizar auditorías de seguridad de forma eficiente.
OWASP SECURITY TESTING
El proyecto Web Security Testing Guide (WSTG) produce el principal recurso de pruebas de ciberseguridad para desarrolladores de aplicaciones web y profesionales de la seguridad. El WSTG es una guía completa para probar la seguridad de las aplicaciones web y los servicios web. Creado por los esfuerzos de colaboración de profesionales de la seguridad cibernética y voluntarios dedicados, el WSTG proporciona un marco de mejores prácticas utilizado por evaluadores de penetración y organizaciones de todo el mundo.
Vamos a verlos un poco más al detalle a cada uno.
ISSAF
ISSAF desarrolla una metodología muy extensa (más de 800 páginas) y detallada sobre cómo realizar una prueba de penetración.
Objetivo:
El objetivo es ofrecer a las PYMES una auditoría técnica de seguridad lo más general posible para que sean conscientes de una gran parte de la superficie de ataque, teniendo acotado el tiempo máximo de realización para que el coste pueda ser asumible para cualquier PYME. Es decir, no se pretende ser exhaustivo en cada una de las fases y en todas las pruebas, sino que se busca recorrer todas las fases incidiendo sólo en las pruebas que mayor porcentaje de vulnerabilidades puedan descubrir.
ISSAF, de OISSG (Open Information System Security Group) ha presentado formalmente su versión “Draft 0.2″. Es uno de los frameworks más interesantes dentro del ámbito de metodología de testeo. Realiza un análisis detallado de todos los posibles aspectos que afectan al testeo de seguridad.
La información contenida dentro de ISSAF, se encuentra organizada alrededor de lo que se ha dado en llamar “Criterios de Evaluación”, cada uno de los cuales ha sido escrito y revisado por expertos en cada una de las áreas de aplicación.
Estos criterios de evaluación a su vez, se componen de los siguientes ítems:
Una descripción del criterio de evaluación.
Puntos y objetivos a cubrir.
Los prerrequisitos para conducir la evaluación.
El proceso mismo de evaluación.
El informe de los resultados esperados.
Las contramedidas y recomendaciones.
Referencias y Documentación Externa.
Para organizar de forma sistemática las labores de testeo, dichos “Criterios de Evaluación”, se han catalogado, desde los aspectos mas generales, como pueden ser los conceptos básicos de la “Administración de Proyectos de Testeo de Seguridad”, hasta técnicas tan puntuales como la ejecución de pruebas de Inyección de Código SQL o como las “Estrategias del Cracking de Contraseñas”.
PTES
The Penetration Testing Execution Standard (PTES) comprende unas guías técnicas para la realización de pruebas de penetración.
Nota: No se ha actualizado desde el 2014.
Consiste en 7 secciones:
INTERACCIONES PREVIAS AL COMPROMISO
El objetivo de una prueba de penetración es identificar el riesgo asociado a un ataque. Esta fase es de vital importancia para delimitar claramente el alcance. Es preciso definir un inicio y un fin de la auditoría.
Al definir el alcance es importante señalar las direcciones que se van a auditar (servidor DNS, servidor de correo, hardware donde se ejecutan las aplicaciones, firewall, …) y que el cliente constate por escrito que son de su propiedad o que, si pertenecen a un tercero, tienen que dar permiso explícitamente esos proveedores. Se proponen una serie de preguntas para que el cliente defina el alcance. El alcance debe estar bien definido en el documento de permiso de la auditoría.
LA RECOGIDA DE INFORMACIÓN
Cuanta más información se recoja en esta fase, mayores vectores de ataque se podrán usar. OSINT (Open Source Intelligence) es una forma de gestionar la recogida de información que implica buscar, seleccionar y adquirir información de fuentes públicas, y analizarla para producir inteligencia que se pueda utilizar.
MODELADO DE AMENAZAS
Se centra en dos elementos: activos y el atacante. Se debe modelar en conjunto con la organización (excepto si es una prueba de penetración de caja negra). Es un entregable del informe final.
ANÁLISIS DE VULNERABILIDADES
Esta fase se divide en 5 apartados.
EXPLOTACIÓN: Esta fase se centra en obtener acceso a un sistema, evitando los sistemas y medidas de protección.
DESPUÉS DE LA EXPLOTACIÓN: El propósito es identificar el valor de la máquina comprometida (según sus datos y el uso de la máquina para comprometer otras máquinas), y mantener el control para un uso posterior.
INFORME: Debe tener dos partes diferenciadas:
RESUMEN EJECUTIVO.
INFORME TÉCNICO.
Recomendamos acceder a su página web, ya que en la sección primera donde enumera el software recomienda una serie de herramientas útiles para cada una de sus 7 secciones.
El Manual de la Metodología Abierta de Comprobación de la Seguridad (OSSTMM, Open Source Security Testing Methodology Manual) es uno de los estándares profesionales más completos y comúnmente utilizados en Auditorías de Seguridad para revisar la Seguridad de los Sistemas desde Internet. Incluye un marco de trabajo que describe las fases que habría que realizar para la ejecución de la auditoría. Se ha logrado gracias a un consenso entre más de 150 expertos internacionales sobre el tema, que colaboran entre sí mediante Internet. Se encuentra en constante evolución.
Actualmente se compone de las siguientes fases:
Sección A -Seguridad de la Información
Revisión de la Inteligencia Competitiva
Revision de Privacidad
Recolección de Documentos
Sección B – Seguridad de los Procesos
Testeo de Solicitud
Testeo de Sugerencia Dirigida
Testeo de las Personas Confiables
Sección C – Seguridad en las tecnologías de Internet
Logística y Controles
Exploración de Red
Identificación de los Servicios del Sistema
Búsqueda de Información Competitiva
Revisión de Privacidad
Obtención de Documentos
Búsqueda y Verificación de Vulnerabilidades
Testeo de Aplicaciones de Internet
Enrutamiento
Testeo de Sistemas Confiados
Testeo de Control de Acceso
Testeo de Sistema de Detección de Intrusos
Testeo de Medidas de Contingencia
Descifrado de Contraseñas
Testeo de Denegación de Servicios
Evaluación de Políticas de Seguridad
Sección D – Seguridad en las Comunicaciones
Testeo de PBX
Testeo del Correo de Voz
Revisión del FAX
Testeo del Modem
Sección E – Seguridad Inalámbrica
Verificación de Radiación Electromagnética (EMR)
Verificación de Redes Inalámbricas [802.11]
Verificación de Redes Bluetooth
Verificación de Dispositivos de Entrada Inalámbricos
Verificación de Dispositivos de Mano Inalámbricos
Verificación de Comunicaciones sin Cable
Verificación de Dispositivos de Vigilancia Inalámbricos
Verificación de Dispositivos de Transacción Inalámbricos
Verficación de RFID
Verificación de Sistemas Infrarrojos
Revisión de Privacidad
Sección F – Seguridad Física
Revisión de Perímetro
Revisión de monitoreo
Evaluación de Controles de Acceso
Revisión de Respuesta de Alarmas
Revisión de Ubicación
Revisión de Entorno
OWASP
OWASP (Open Web Application Security Project) Foundation es una Fundación sin ánimo de lucro que se dedica a mejorar la seguridad del software (OWASP Foundation, s.f.).
Entre sus proyectos destacan:
OWASP Top Ten: La lista de las 10 amenazas más importantes en cuanto seguridad en aplicaciones Web.
Guía de pruebas de seguridad para móviles.
Security Knowledge Framework: Es un conjunto de herramientas para aprender a programar de una forma segura.
Web Security Testing Guide: Es una guía de pruebas exhaustiva para aplicaciones web (OWASP, 2020).
OWASP ZAP: Es un escáner de aplicaciones Web.
OTP
“OWASP Testing Project” (OTP), está muy orientado a realizar pruebas sobre aplicaciones Web y está en el camino de convertirse en uno de los proyectos referencia en su ámbito. OWASP, ha conseguido ser una referencia habitual para cualquier desarrollador en el ámbito de la seguridad. OTP en particular, se encuentra enfocado a responder preguntas tales como: ¿qué?, ¿por qué?, ¿cuándo?, ¿dónde? y ¿cómo? testear una aplicación web. Se cubren los siguientes puntos:
El alcance de que testear.
Principios del testeo.
Explicación de las técnicas de testeo.
Explicación general acerca del framework de testeo de OWASP.
OTP incorpora en su metodología de testeo, aspectos claves relacionados con el “Ciclo de Vida del Desarrollo de Software” a fin de que el “ámbito” del testeo a realizar, comience mucho antes de que la aplicación web se encuentre en producción.
De este modo, y teniendo en cuenta que un programa efectivo de testeo de aplicaciones web, debe incluir como elementos a testear: Personas, Procesos y Tecnologías, OTP delinea en su primer parte conceptos claves a la vez que introduce un framework específicamente diseñado para evaluar la seguridad de aplicaciones web a lo largo de su vida.
PRUEBAS DE SEGURIDAD DE UNA APLICACIÓN WEB
Aquí se desarrolla una metodología detallada en varias etapas:
Recogida de información.
Pruebas de gestión de la configuración y la implementación.
Pruebas de gestión de identidad.
Prueba de autenticación.
Prueba de autorización.
Prueba de gestión de sesiones.
Prueba de validación de entrada.
Manejo de errores.
Criptografía.
Pruebas de lógica empresarial.
Pruebas del lado del cliente.
INFORME
Como todos los informes, debe contener al principio un resumen ejecutivo, y después desarrollar:
Objetivos del proyecto.
Alcance.
Planificación.
Aplicaciones y sistemas objeto de la prueba.
Limitaciones.
Hallazgos
Remediación.
NISST 800-115
Guía Técnica para Evaluaciones y Pruebas de Seguridad de la Información NIST SP 800-115 (Technical Guide to Information Security Testing and Assessment), fue publicada en septiembre del 2008 por el Instituto Nacional de Estándares y Tecnología (NIST) del gobierno de los EE.UU. Describe las pautas sobre como debe realizarse una Evaluación de Seguridad de la Información (ESI) y lo conceptualiza como el proceso de determinar cuan eficazmente una entidad es evaluada frente a objetivos específicos de seguridad. Define como activos y objetos de evaluación los servidores, redes de datos, procedimientos y personas.
Para la realización de la ESI, pueden usarse tres métodos de evaluación:
Pruebas: Es el proceso de poner bajo pruebas uno o más objetos de evaluación bajo condiciones específicas para comparar el comportamiento real y el esperado.
Escrutinio: Es el proceso de comprobar, inspeccionar, revisar, observar, estudiar o analizar uno o mas objetos de evaluación para facilitar su comprensión, aclaración u obtener evidencias.
Entrevista: Es el proceso para la conducción de discusiones e intercambios con grupos de personas con el objetivo de facilitar la comprensión, aclaración o identificar la localización de evidencias asociadas a los objetos de evaluación.
Los resultados obtenidos a través de los métodos de evaluación son utilizados para determinar la efectividad de los controles de seguridad de la entidad.
La NIST SP 800-115 propone un proceso de ESI compuesto por al menos tres fases:
Planificación: Clasificada como una fase crítica para el éxito de la ESI. En ella se debe recopilar información sobre los activos que serán evaluados, las amenazas de interés contra estos activos y los controles de seguridad que pueden ser utilizados para mitigar esas amenazas. Teniendo como principio que una ESI es un proyecto, debe establecerse un plan de gestión que incluya metas y objetivos específicos, alcance, requerimientos, roles y responsabilidades de los equipos, limitaciones, factores de éxito, condicionantes, recursos, planificación de tareas y entregables.
Ejecución: El objetivo principal de esta fase es identificar las vulnerabilidades y comprobarlas según la planificación establecida. Deben aplicarse métodos y técnicas de evaluación apropiados según el objetivo de la ESI.
Post-Ejecución: Centrada en el análisis de las vulnerabilidades encontradas para determinar la raíz de las causas de su presencia, establecer recomendaciones para su mitigación y desarrollar el reporte final.
Pruebas de Intrusión en la NIST SP 800-115
Las pruebas de intrusión son formalizadas como las pruebas de seguridad en la cual, los evaluadores simulan ataques del mundo real en un intento de identificar modos de evadir las características de seguridad de una aplicación, sistema o red de datos.
Se menciona además, que la mayoría de las pruebas de intrusión involucran la búsqueda de explotación combinada de vulnerabilidades en uno o más sistemas, de manera que puedan ser aprovechadas para ganar mayores privilegios de acceso que lo que pudiera haberse alcanzado a través de la explotación de una sola vulnerabilidad.
Según la NIST SP 800-115, las pruebas de intrusión pueden ser utilizadas para determinar:
La manera en que el sistema tolera los patrones de ataques del mundo real.
El nivel de sofisticación que un atacante necesita para comprometer con efectividad el sistema.
Las medidas adicionales que se deben emplear para mitigar las amenazas contra el sistema.
La habilidad de los defensores para detectar los ataques y responder apropiadamente a estos.
Fases de la prueba de intrusión
El proceso de pruebas de intrusión se desarrolla a través de cuatro fases:
Fase de Descubrimiento:
Se realiza el escaneo y recopilación de información de la infraestructura informática de la entidad.
Se realiza el descubrimiento de vulnerabilidades a partir de la información recopilada de servicios, base tecnológica y otras informaciones que permitan realizar búsquedas en bases de datos de vulnerabilidades públicas o propias.
Fase de Ejecución:
En este proceso se realiza la comprobación de las vulnerabilidades previamente descubiertas y es la fase principal del proceso (figura 2). Si un ataque es exitoso, debe aislarse y documentarse cuidadosamente la vulnerabilidad y proponerse medidas para mitigarla. Las actividades internas que se llevan a cabo son:
Ganar privilegios de accesos: Si la información recopilada en la fase anterior es suficiente, durante esta actividad es posible ganar privilegios de acceso al sistema.
Escalada de privilegios:
Si en la actividad anterior solo se pudo ganar privilegios de acceso de bajo nivel (Ej. usuario básico), durante esta actividad, los evaluadores deben tratar de alcanzar el control total de sistema, semejante al que tendrían los administradores de este.
Navegación dentro del sistema:
Con el control del sistema alcanzado en la actividad anterior, los evaluadores deben buscar información adicional que les permita comprender mejor la existencia y métodos para ganar privilegios de acceso en sistemas secundarios. Si se descubren nuevos datos e informaciones, se sumarían estos a los resultados de la fase de Descubrimiento y se planificaría la explotación de las nuevas vulnerabilidades descubiertas.
Instalación de herramientas adicionales:
Durante el proceso de explotación de vulnerabilidades, puede requerirse la instalación de herramientas que permitan recopilar información adicional, ganar otros privilegios de accesos o ambas cosas a la vez.
Fase de Documentación y Reporte:
Se desarrolla en paralelo con el resto de las fases del siguiente modo:
En la fase de Planificación se documenta el Plan de Evaluación o las Reglas de Interacción.
En la fase de Descubrimiento se almacenan los reportes generados por los escaneadores de vulnerabilidades e informaciones útiles obtenidas a través de otros medios.
En la fase de Ejecución se almacenan los reportes generados por las herramientas de explotación de vulnerabilidades.
Al concluir la prueba de intrusión, se genera un reporte con la descripción de las vulnerabilidades encontradas, presenta una puntuación de riesgos y brinda una guía sobre como mitigar las debilidades descubiertas.
En definitiva, la NIST SP 800-115 concibe las pruebas de intrusión como un paquete de pruebas de seguridad que se realizan utilizando los mismos métodos y herramientas que emplean los atacantes reales. Se emplean para verificar las vulnerabilidades descubiertas en fases anteriores y sirven para demostrar como las vulnerabilidades pueden ser explotadas iterativamente para ganar privilegios de accesos al sistema.
Su concepción de la Evaluación de Seguridad de la Información gestionada mediante un proyecto estándar y la redacción de un documento conteniendo las Reglas de Interacción, lo convierten en referente para la construcción del proceso de gestión de las Prueba de Intrusión. Por otra parte, se evidencian limitantes que impiden que pueda ser tomado como base para la ejecución de pruebas de seguridad concretas en aplicaciones informáticas en sentido general y en aplicaciones web de manera específica.
El Metasploit Framework es un proyecto de código abierto que proporciona un recurso público para la investigación de vulnerabilidades y el desarrollo de código que permite a los profesionales de la seguridad la capacidad de infiltrarse en su propia red e identificar riesgos y vulnerabilidades de seguridad. Metasploit fue adquirido por Rapid 7. Sin embargo, la edición comunitaria de Metasploit sigue estando disponible en Kali Linux. Metasploit es, con mucho, la utilidad de penetración más utilizada del mundo.
Es importante que tengas cuidado cuando uses Metasploit porque escanear una red o un entorno que no es tuyo podría considerarse ilegal en algunos casos. En este tutorial de metasploit en Kali Linux, te mostraremos cómo iniciar Metasploit y ejecutar un escaneo básico en Kali Linux. Metasploit se considera una utilidad avanzada y requerirá algo de tiempo para convertirse en un experto, pero una vez familiarizado con la aplicación será un recurso inestimable.
Metasploit y Nmap
Metasploit muy robusto con sus características y flexibilidad. Un uso común para Metasploit es la Explotación de Vulnerabilidades. A continuación vamos a ir a través de los pasos de la revisión de algunos exploits y tratar de explotar una máquina de Windows 7.
Paso 1: Asumiendo que Metasploit está todavía abierto, introduce Hosts -R en la ventana de la terminal. Esto añade los hosts recientemente descubiertos a la base de datos de Metasploit.
Paso 2: Introduce «show exploits», este comando proporcionará una mirada completa a todos los exploits disponibles para Metasploit.
Paso 3: Ahora, intenta reducir la lista con este comando: search name: Windows 7, este comando busca los exploits que incluyen específicamente Windows 7, para el propósito de este ejemplo intentaremos explotar una máquina Windows 7.
Dependiendo de tu entorno, tendrás que cambiar los parámetros de búsqueda para satisfacer tus criterios. Por ejemplo, si tienes Mac u otra máquina Linux, tendrás que cambiar el parámetro de búsqueda para que coincida con ese tipo de máquina.
Paso 4: Para los propósitos de este ejemplo utilizaremos una vulnerabilidad de Apple Itunes descubierta en la lista. Para utilizar el exploit, debemos introducir la ruta completa que aparece en la lista: exploit/windows/browse/apple_itunes_playlist
Paso 5: Si el exploit es exitoso, el prompt del comando cambiará para mostrar el nombre del exploit seguido de > como se muestra en la siguiente captura de pantalla:
Paso 6: Introduce show options para revisar las opciones disponibles para el exploit. Cada exploit, por supuesto, tendrá diferentes opciones.
Network Mapper, más conocido como Nmap para abreviar, es una utilidad gratuita y de código abierto utilizada para el descubrimiento de redes y la exploración de vulnerabilidades. Los profesionales de la seguridad utilizan Nmap para descubrir los dispositivos que se ejecutan en sus entornos. Nmap también puede revelar los servicios, y los puertos que cada host está sirviendo, exponiendo un potencial riesgo de seguridad. En el nivel más básico, considera a Nmap como un ping con esteroides. Cuanto más avanzados sean tus conocimientos técnicos, más utilidad encontrarás en Nmap.
Nmap ofrece la flexibilidad de monitorizar un único host o una vasta red formada por cientos, si no miles, de dispositivos y subredes. La flexibilidad que ofrece Nmap ha evolucionado a lo largo de los años, pero en su esencia, es una herramienta de escaneo de puertos, que recopila información enviando paquetes sin procesar a un sistema anfitrión. Nmap escucha entonces las respuestas y determina si un puerto está abierto, cerrado o filtrado.
El primer escaneo con el que deberías estar familiarizado es el escaneo básico de Nmap que escanea los primeros 1000 puertos TCP. Si descubres un puerto escuchando, mostrará el puerto como abierto, cerrado o filtrado. Filtrado significa que lo más probable es que haya un cortafuegos modificando el tráfico en ese puerto en particular. A continuación hay una lista de comandos de Nmap que se pueden utilizar para ejecutar el escaneo por defecto.
Nota: Nmap es un programa que se ejecuta desde la consola
A continuación vamos a ver los comandos que se deben escribir para usar nmap:
Escanear una sola IP
nmap 192.168.1.1
Escanear un host
nmap www.sevilla.com
Escanear un rango IPs
nmap 192.168.1.1-20
Escanear una subred
nmap 192.168.1.0/24
Escanear objetivos desde un archivo de texto
nmap -iL list-of-ipaddresses.txt
Cómo realizar un escaneo Nmap básico en Kali Linux
Para ejecutar un escaneo básico de Nmap en Kali Linux, siga los siguientes pasos. Con Nmap, tal y como se muestra arriba, tiene la capacidad de escanear una única IP, un nombre DNS, un rango de direcciones IP, subredes e incluso escanear desde archivos de texto. Para este ejemplo, escanearemos la dirección IP de localhost.
Desde el menú del Dock, haz clic en la segunda pestaña que es la Terminal.
La ventana de la Terminal debería abrirse, introduce el comando ifconfig, este comando devolverá la dirección IP local de su sistema Kali Linux. En este ejemplo, la dirección IP local es 10.0.2.15.
Anota la dirección IP local.
En la misma ventana de terminal, introduce nmap 10.0.2.15, esto escaneará los primeros 1000 puertos en el localhost. Teniendo en cuenta que esta es la instalación base, ningún puerto debería estar.
Revisa los resultados.
Por defecto, nmap sólo escanea los primeros 1000 puertos. Si necesitas escanear los 65535 puertos completos, simplemente debes modificar el comando anterior para incluir “-p-“.
Escaneo del Sistema Operativo (SO) de Nmap
Otra característica básica pero útil de nmap es la capacidad de detectar el SO del sistema anfitrión. Kali Linux por defecto es seguro, por lo que para este ejemplo se utilizará como ejemplo el sistema anfitrión, en el que está instalado VirtualBox de Oracle. Como ejercicio, vamos a realizar un escaneo al sistema anfitrión que posiblemente sea un Windows 10 o Windows 11.
Para eso realiza los siguientes pasos:
Presiona la tecla “Windows” +R.
Escribe “cmd“.
Y en la consola escribe el comando “ipconfig“.
A continuación se va a poder visualizar la Ip del Adaptador de red.
Ahora desde Kali, ejecuta:
nmap 192.168.1.153 – A (siendo 192.168.1.153 la dirección IP de la máquina anfitrión)
Añadir -A le dice a nmap que no sólo realice un escaneo de puertos sino que también intente detectar el Sistema:
Al escanear puertos con Nmap, hay tres tipos básicos de escaneo. Estos son:
Exploraciones de conexión TCP (-sT )
SYN Escaneos “medio abiertos” ( -sS)
Escaneos UDP-sU ( )
Además, hay varios tipos de escaneo de puertos menos comunes, algunos de los cuales también cubriremos (aunque con menos detalle). Estos son:
Exploraciones nulas de TCP-sN ( )
Escaneos TCP FIN (-sF )
Escaneos de Navidad TCP-sX ( )
Ahora toca jugar con nmap, contesta las siguientes preguntas.
Introducción a la interfaz gráfica (GUI) de Kali Linux
El Escritorio Kali tiene unas cuantas pestañas de las que deberías tomar nota inicialmente y familiarizarte con ellas: Pestaña de Aplicaciones, Pestaña de Lugares, y el Dock de Kali Linux.
Pestaña Aplicaciones
Proporciona una lista gráfica desplegable de todas las aplicaciones y herramientas preinstaladas en Kali Linux. Revisar la Pestaña de Aplicaciones es una gran manera de familiarizarse con el enriquecido sistema operativo Kali Linux. Dos aplicaciones que son muy utilizadas de Kali Linux son Nmap y Metasploit. Las aplicaciones están colocadas en diferentes categorías lo que hace que la búsqueda de una aplicación sea mucho más fácil.
Accediendo a las aplicaciones
Haz clic en la pestaña Aplicaciones.
Busca la categoría particular que te interesa explorar.
Haz clic en la aplicación que deseas iniciar.
Pestaña Lugares
Al igual que en cualquier otro sistema operativo con interfaz gráfica, como Windows o Mac, el acceso fácil a sus carpetas, imágenes y mis documentos es un componente esencial. Lugares en Kali Linux proporciona esa accesibilidad que es vital para cualquier sistema operativo. Por defecto, el menú de Lugares tiene las siguientes pestañas: Inicio, Escritorio, Documentos, Descargas, Música, Imágenes, Vídeos, Ordenador y Navegar por la Red.
Acceder a Lugares
Haz clic en la pestaña Lugares.
Selecciona la ubicación a la que deseas acceder.
Kali Linux Dock
Similar al Dock de Apple Mac o a la Barra de Tareas de Microsoft Windows, el Dock de Kali Linux proporciona un acceso rápido a las aplicaciones usadas frecuentemente / favoritas. Las aplicaciones pueden ser añadidas o eliminadas fácilmente.
Para eliminar un elemento del Dock
Haz clic con el botón derecho en el elemento del Dock.
Selecciona Eliminar de Favoritos.
Cómo añadir un elemento al Dock
Añadir un elemento al Dock es muy similar a eliminar un elemento del Dock:
Haz clic en el botón Mostrar aplicaciones en la parte inferior del Dock.
Haz clic con el botón derecho en la aplicación.
Selecciona Añadir a Favoritos.
Una vez completado, el elemento se mostrará en el Dock.
Kali Linux tiene muchas otras características únicas, lo que hace que este sistema operativo sea la principal elección de los ingenieros de seguridad y hackers por igual. Desafortunadamente, no es posible cubrirlas todas dentro de este tutorial de hacking de Kali Linux; sin embargo, deberías sentirte libre de explorar los diferentes botones mostrados en el escritorio.
Kali Linux está basado en Debian GNU/Linux y fue desarrollado por la compañía de ciberseguridad Offensive Security. Kali es un sistema operativo de código abierto y se diferencia de otras distribuciones de sistemas operativos en cuanto a que reúne más de 600 programas para hacking ético, que se encuentran preinstalados en el sistema.
¿Cuáles son las funciones de Kali Linux?
Recopilación de información: herramientas para obtener todos los datos posibles sobre el sistema objetivo.
Análisis de vulnerabilidades: escaneo e identificación de fallos de seguridad, los cuales pueden ser aprovechados para iniciar un ciberataque.
Análisis de aplicaciones web: herramientas especiales para escanear sitios web en búsqueda de vulnerabilidades.
Evaluación de bases de datos: encuentra vulnerabilidades de forma automática en bases de datos.
Ataques de contraseñas: ataques de diccionario, tablas y fuerza bruta para encontrar contraseñas fáciles de descubrir.
Ataques Wireless: herramientas para ejecutar ciberataques por medio de redes inalámbricas.
Ingeniería inversa: herramientas para descubrir el código fuente de una aplicación. Por ejemplo, de un malware.
Herramientas de explotación: sirven para aprovechar las fallas de seguridad de un sistema con el fin de infiltrarse en él.
Sniffing and Spoofing: robo de datos y suplantación de identidad.
Postexplotación: escalada de privilegios, establecimiento de persistencia y entrega del payload en el sistema. Es decir, ejecución de tareas dañinas como tal.
Análisis forense: estudio de las huellas dejadas por un ciberatacante.
Herramientas de reporte: especiales para diseñar informes de ciberseguridad, después de ejercicios de pentesting.
Herramientas de ingeniería social: para simular campañas de phishing, spear phishing y más.
Algunas herramientas de Kali Linux
Ya sabes qué es Kali Linux, un sistema operativo basado en Debian que tiene cientos de herramientas de pentesting preinstaladas. Ahora, hablaremos sobre algunos de los programas más famosos que incluye Kali y cuáles son sus funciones:
Nmap: este es uno de los programas de hacking más famosos y se utiliza para escanear redes, dispositivos y puertos abiertos. Nmap revela información sobre los dispositivos conectados a una red y sus fallos de seguridad.
John The Ripper: es un programa de código abierto que se especializa en ejecutar técnicas para descubrir contraseñas. Por medio de esta herramienta puedes realizar ataques de fuerza bruta y de diccionario, para «romper» contraseñas (sobre todo las más fáciles).
Metasploit: se trata de un framework de código abierto que contiene miles de herramientas para explotar vulnerabilidades conocidas en un sistema.
En este laboratorio, tenemos como objetivo explorar las herramientas que se suelen utilizar en cada una de las fases de pentesting.
Si no las recuerdas te las dejamos a continuación:
Hoy en día existen muchos kits de herramientas de pruebas de penetración de código abierto y están diseñados para reducir su trabajo. En el pasado, realizar una prueba de penetración significaba que cada pentester creaba un conjunto de herramientas que prefería usar, las mantenía actualizadas manualmente, conservaba copias maestras en caso de corrupción y tenía que investigar manualmente cómo integrar nuevas herramientas a medida que se actualizaban e integraban. Aquí era donde se gastaba una gran parte del tiempo del pentester en lugar de dedicarse al trabajo “real” de probar la seguridad de un cliente. Por lo general, esto no se consideraba tiempo facturable y era un verdadero desafío.
La primera decisión: Sistema operativo a utilizar.
La siguiente decisión que debes tomar es el tipo de sistema operativo que te gustaría usar. Hay una serie de herramientas de prueba de penetración que están diseñadas para ejecutarse en Windows, pero generalmente hay más herramientas disponibles en la plataforma GNU/Linux. El desafío aquí es determinar qué distribución de GNU/Linux para usar, ya que hay una gran variedad para elegir.
Algunos ejemplos de distribuciones populares de Linux son:
Ubuntu
Debian
Kali Linux
Parrot Linux
Arch Linux
….
Para este curso, vamos a utilizar y recomendamos que se use el sistema operativo de Kali Linux por varias razones: está basado en Debian, hay mucha documentación y sobre todo, ya viene con todas las herramientas que abordaremos en este curso.
Pero si tienes pasión por otra distribución como Debian, Parrot, eres libre de hacerlo, mientras tenga las herramientas que utilizaremos será más que suficiente. Y no prestes mucha atención a la interfaz gráfica, en definitiva en lo menos que usarás.
Lo siguiente que debemos tener claro, si vamos a trabajar con una máquina por ejemplo KALI de forma virtual o real, es decir instalada en nuestro ordenador. Si nos vamos a dedicar al pentesting tendremos que usar portátiles, ya que nos deberemos de mover de un sitio a otro. Por lo que debemos de ir pensando en que si no es dedicado, tendremos que compartir el disco duro con un arranque DUAL. Por lo que te guste o no en la práctica muchas veces no estarás usando el GNU/Linux, y estarás sacrificando parte de tu disco duro.
Nuestra recomendación es al menos 100 GB de disco duro, y al menos 8 GB de RAM.
Ahora tómate tu tiempo y piensa si lo vas a querer virtual o real.
Si lo quieres virtualizar puedes hacerlo con varias plataformas de virtualización. Aquí te dejamos dos opciones:
1. Instalar Oracle VM VirtualBox
Paso 1: Ve a la página de Oracle VM VirtualBox (https://www.virtualbox.org/wiki/Downloads) y haz clic en el botón ‘Descargar Oracle VM VirtualBox‘ para descargar el instalador.
Paso 2: Abre el archivo de instalación .exe de tu carpeta de descargas y haz clic en Next para iniciar la instalación.
Paso 3: Selecciona los componentes que quieres instalar y haz clic en Next para instalar el software en la ubicación predeterminada. También puedes cambiar la carpeta de destino.
Paso 4: Elige qué atajos quieres crear y haz clic en Next.
Paso 5: Haz clic en Yes para continuar.
Paso 6: Haz clic en Install para iniciar la instalación.
Paso 7: Haz clic en Install cuando se te pida. Al hacerlo, VirtualBox comenzará a instalarse en tu ordenador.
Paso 8: Una vez finalizada la instalación, marca la casilla para lanzar el programa y haz clic en Finish.
El programa está instalado y listo para usar.
2.Instalar una máquina virtual
Si prefieres instalar GNU/Linux en una máquina virtual a través de Virtualbox en lugar de VMware, puedes seguir los siguientes pasos.
Paso 1: Tener instalado Virtualbox.
Paso 2: Abre Virtualbox y haz clic en New para crear una nueva máquina virtual.
Paso 3: Da un nombre a la máquina virtual y selecciona en qué carpeta se almacenará.
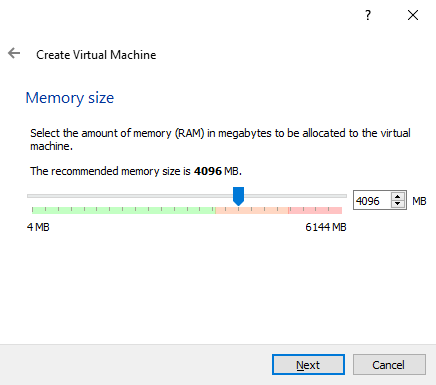
Paso 4: Selecciona la cantidad de memoria RAM de la máquina virtual.
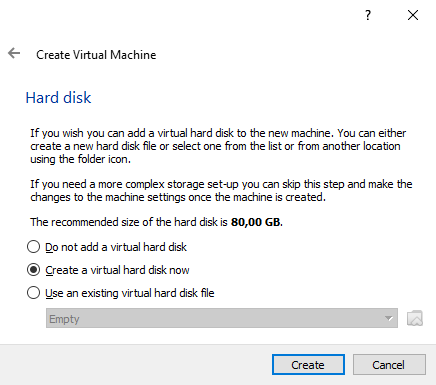
Paso 5: Elige qué disco se añadirá a la máquina virtual. Por defecto se optará por crear un nuevo disco virtual.
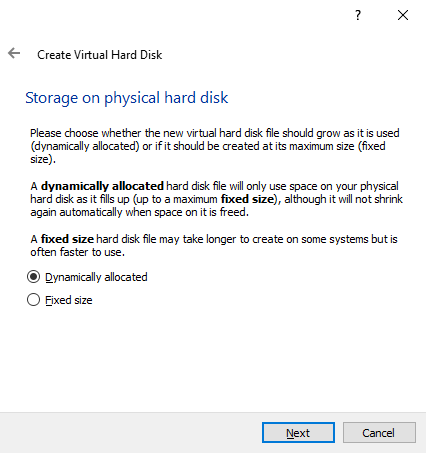
Paso 6: Elige el tipo de archivo del disco virtual. Por defecto se recomienda trabajar con VDI (Virtualbox Disk Image).
Paso 7: Selecciona cómo se asigna el disco virtual.
Paso 8: Determina el tamaño del disco.
Paso 9: Haz clic en Settings.
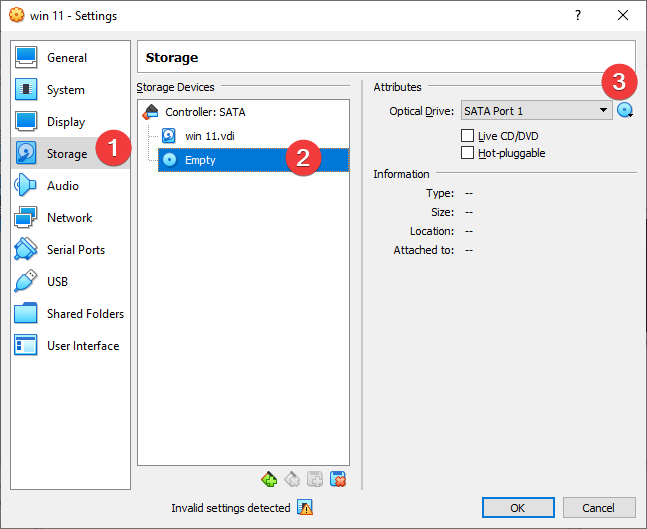
Paso 10: Haz clic en Storage > Empty disk. Haz clic en el icono del disco y luego en ‘Choose a disk file‘.
A continuación, selecciona el archivo ISO que descargaste en el primer paso.
Paso 11: Haz doble clic en la máquina virtual para iniciarla
Paso 12: Ya puedes empezar a instalar tu GNU/Linux virtual.
Paso2: Abre el archivo de instalación de VMware Workstation Pro.
Paso 3: Haz clic en Next.
Paso 4: Acepta el acuerdo de licencia.
Paso 5: Elige la ubicación deseada para la instalación y haz clic en Next.
Paso 6: Marca las opciones si lo deseas y haz clic en Next.
Paso 7: Haz clic en Next.
Paso 8: Haz clic en Install. La duración de la instalación depende de la potencia de tu ordenador.
Paso 9: Haz clic en License para añadir tu licencia.
Paso 10: Si no tienes la licencia y quieres probarlo, puedes darle a “Skip” y finalmente a “Install“
El software está listo para usar.
Creando una máquina virtual en VMWare Pro.
Paso 1: Abre VMware Workstation y haz clic en File > New Virtual Machine…
Paso 2: Se abre una nueva ventana. Selecciona la configuración deseada:
Elige Custom (advanced) si quieres modificar algunos aspectos.
Elige Typical (recommended) si no quieres modificar nada.
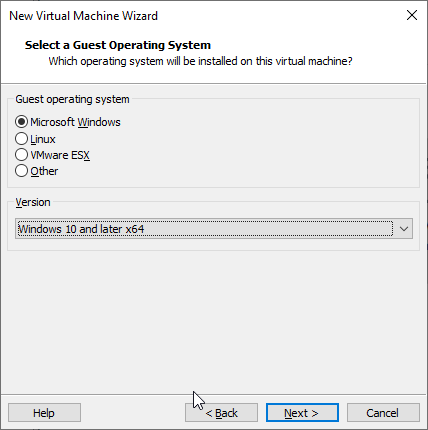
Paso 3: Selecciona el sistema operativo que se instalará en la máquina virtual. Selecciona Microsoft Windows y elige la versión correcta.
Paso 4: Elige un nombre para tu máquina virtual y la ubicación donde se almacenarán los datos.
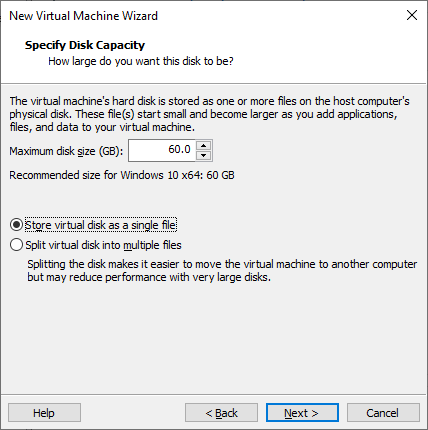
Paso 5: Determina el tamaño de tu disco y selecciona cómo el disco virtual almacenará los archivos (en un solo archivo o en varios archivos).
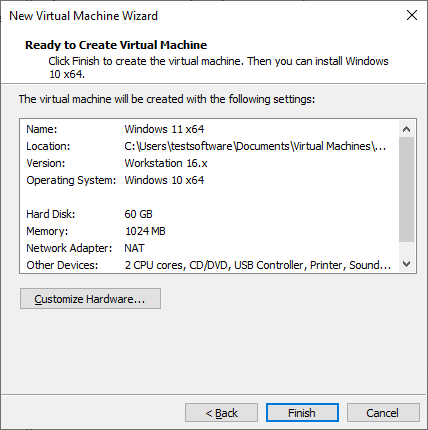
Paso 6: Revisa todos los ajustes y haz clic en Finish para completar la configuración.
Paso 8: Haz clic en la máquina virtual que acabas de crear y luego haz clic en ‘Power on this virtual machine‘.
Paso 9: Ahora puedes editar la configuración e indicarle en la unidad de CDROM la que utilice la imagen ISO de Kali o del sistema qui hayas elegido para empezar la instalación.
Una prueba de penetración o pentest es un ataque simulado y autorizado contra un sistema informático con el objetivo de evaluar la seguridad del sistema. Durante la prueba, se identifican las vulnerabilidades presentes en el sistema y se explotan tal como haría un atacante con fines maliciosos. Esto permite al pentester realizar una evaluación de riesgos en la actividad comercial del cliente basándose en los resultados de la prueba y sugerir un plan de medidas correctivas.
TIPOS DE PENTEST. Principalmente, existen dos tipos de pentest que se clasifican según el rol que adopta el pentester durante la prueba de penetración:
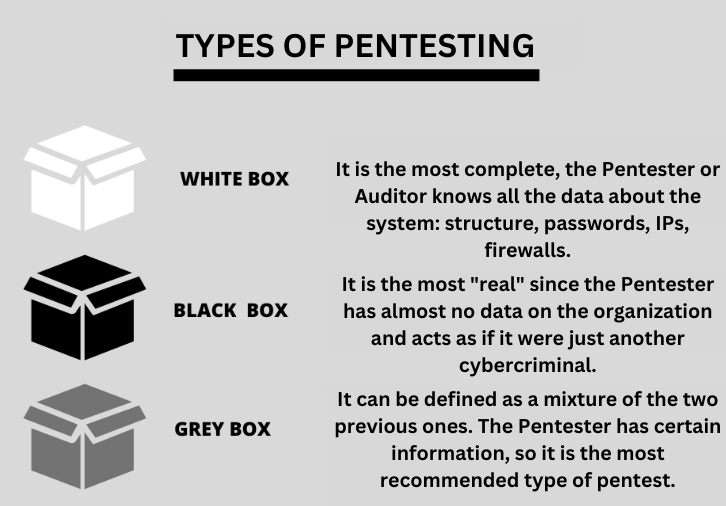
Auditoria Externa (Covert pentest) La auditoría externa, o de caja negra, pretende valorar el grado de seguridad de la red externa de una empresa. En este enfoque el pentester asume el rol de un atacante externo, que sin ninguna información previa, puede obtener algún beneficio de la organización, o incluso, acceso a información sensible que comprometa la privacidad de la empresa. De esta manera, se pone a prueba el estado de las barreras de seguridad que dispone la empresa entre internet y su red corporativa.
Auditoria interna (Overt pentest) La auditoría interna pretende evaluar la seguridad del entorno privado de la empresa u organización. En esta auditoría, el pentester asume el rol de un atacante que dispone de acceso a la red interna de la empresa. La auditoría interna puede ser de caja blanca o caja gris en función de los permisos que se tengan. En una auditoría de caja blanca, el pentester recibe gran cantidad de información del sistema que va a auditar como puede ser la topología de red, rangos de IP, sistemas operativos, etc. Lo que se pretende es ahorrarle la fase de recolección de información y facilitarle en gran medida la tarea de intrusión para ver si, incluso de esta forma, es capaz de encontrar vulnerabilidades en el sistema. Por otra parte, en la auditoria de caja gris, se combinan los enfoques de caja blanca y caja negra. De esta forma, el pentester asume un rol de usuario sin privilegios dentro de la organización y la cantidad de información que recibe es meramente orientativa. Por último, es pertinente, establecer que existen otras clases de auditoria diferenciadas por el ámbito en el que se aplican. Por ejemplo, la auditoria Wireless (que es un tipo de auditoria interna) y la auditoria WEB tipo de auditoría externa por lo general.
CONTEXTO:
Para comprender el contexto en el que se desarrolla este tipo de actividad se debe echar un vistazo a la historia del hacking ético. La historia del hacking ético es la historia del hacking. A principios de la década de los sesenta, mayormente en el MIT (Massachusetts Institute of Technology), comenzó a desarrollarse la cultura “hacker”. Esta fue también la época donde se datan las primeras discusiones lideradas por expertos sobre penetración en computadoras y pruebas deliberadas realizadas por profesionales. En aquel entonces, el termino hacking tenía el significado de encontrar diferentes formas de optimizar sistemas y máquinas para hacerlos funcionar de manera más eficiente. La influencia de la cultura hacker comenzó un gran periodo de expansión a partir del año 1969, año de creación de ARPANET. ARPANET fue la primera red intercontinental de alta velocidad. Fue construida por el departamento de defensa estadounidense como un experimento de comunicaciones digitales, pero creció hasta interconectar a cientos de universidades, contratistas de defensa y centros de investigación. Permitió a investigadores de todas partes intercambiar información con una rapidez y flexibilidad sin precedentes, dando un gran impulso a la colaboración y aumentando enormemente el ritmo y la intensidad de los avances tecnológicos.
Pero ARPANET hizo algo más. Sus autopistas electrónicas reunieron a hackers de todo Estados Unidos en una masa crítica: en lugar de permanecer en pequeños grupos aislados desarrollando efímeras culturas locales, se descubrieron a sí mismos como una tribu interconectada. Fue durante la década de 1970 cuando las aguas comenzaron a enturbiarse. Con la creciente popularidad de las computadoras, las personas que entendían los sistemas y los lenguajes de programación comenzaban a ver las posibilidades de probar esos sistemas para comprender sus capacidades. Este también fue el momento en que phreaking1 comenzó a ganar notoriedad. Los phreakers comenzaron a comprender la naturaleza de las redes telefónicas y comenzaron a usar dispositivos que imitaban los tonos de marcación para enrutar sus propias llamadas, lo que les permitía realizar llamadas gratuitas, específicamente, llamadas de larga distancia muy costosas. Podría decirse que esta fue una de las primeras veces que el hacking fue utilizado con fines ilegales por un gran número de personas. Simultáneamente, los gobiernos y las empresas comenzaron a ver el beneficio de contar con expertos técnicos que buscan activamente las debilidades de un sistema para ellos, lo que les permite resolver esos problemas antes de que puedan ser explotados. Estos eran conocidos como “equipos de tigres” y el gobierno estadounidense estaba especialmente interesado en usarlos para reforzar sus defensas.
Esto deriva en la formación del primer “equipo tigre” en 1971, el cual es contratado por la USAF (United States Air Force) para probar los sistemas de tiempo compartido y en 1974 lleva a cabo uno de los primeros hacks éticos para probar la seguridad del sistema operativo Multics. A principios de la década de los 80, el término hacker comenzó a asociarse casi exclusivamente con la actividad delictiva. La increíble popularidad de la computadora personal como herramienta para empresas e individuos significó que muchos datos y detalles importantes ahora se almacenan no en forma física, sino en programas de computadora. Los hackers comenzaron a ver las posibilidades de robar información que luego podría venderse o utilizarse para defraudar a las empresas.
El hacking estaba ganando un perfil negativo en los medios. Los hackers eran vistos como delincuentes, intrusos digitales, que usaban sus habilidades para acceder a computadoras privadas, robar datos e incluso chantajear a las empresas para que les entregaran grandes sumas de dinero. Este tipo de hackers son los nombrados hoy como black hat hackers, están puramente interesados en utilizar sus habilidades para fines maliciosos y, a menudo, están conectados a una variedad de actividades delictivas diferentes. Por otra parte, se distingue otro tipo de hacker: los white hat hackers que hacen práctica del hacking ético. Esto es, la aplicación de las mismas técnicas que utilizan los black hat hackers para romper las defensas cibernéticas. La diferencia es que cuando un white hat hacker ha puesto en peligro esas defensas, informan al negocio de cómo lograron hacerlo para que la vulnerabilidad pueda corregirse.
Finalmente, existe un tercer tipo de hacker denominado grey hat hack, el cual se caracteriza por violar la ley o la ética hacker algunas veces, pero siempre actuando sin un fin malicioso. En 1983 se produce el primer arresto de hackers por el FBI después de que invadieran el centro de investigación de Los Álamos. Un año después, en 1984, Fred Cohen crea el primer virus para PC y surge un nuevo término: ‘virus informático’. Ese mismo año, Steven Levy publicó el libro titulado Hackers: heroes of the computer revolution, en donde se plantea por primera vez la idea de la ética hacker, y donde se proclama y se promueve una ética de libre acceso a la información y al código fuente del software. Phreaking se refiere a la práctica de manipular sistemas de telecomunicaciones. No fue sino hasta 1986 que el gobierno de los Estados Unidos se dio cuenta del peligro que representaban los hackers para la seguridad nacional.
Como una forma de contrarrestar esta amenaza, el Congreso aprobó la Ley de Fraude y Abuso de Computadoras, convirtiendo el acceso ilícito a computadoras en un crimen en todo el país. En los años posteriores se sucedieron una serie de delitos que corroboraron la importancia de esta ley para cubrir el ordenamiento jurídico aplicable a este tipo de delitos.
En 1987 Herbert Zinn, con una edad de 17 años, es arrestado después de entrar en el sistema de AT&T. Los expertos afirman que estuvo a punto de bloquear todo el sistema telefónico norteamericano. Un año más tarde, en 1988, Robert Morris crea un gusano de Internet que infecta el 10% de los ordenadores de todo internet. Erradicarlo costó casi un millón de dólares, y produjo pérdidas estimadas las pérdidas totales en 96 millones de dólares. Ese mismo año aparece el primer software antivirus, escrito por un desarrollador de Indonesia. En 1889 Robert Morris se convierte en el primer encarcelado bajo la ley de fraude y abuso de computadoras. A continuación se deja el código del gusano Morris.
Durante la década de 1990, cuando el uso de Internet se extendió por todo el mundo, los piratas informáticos se multiplicaron, pero no fue sino hasta el final de la década que la seguridad del sistema se convirtió en la corriente principal entre el público. Uno de los delitos más importantes de la década ocurrió en 1994, cuando Vladimir Levin hackeó el Citibank y robó 10 millones de dólares. En 1995 Dan Farmer y Wietse Venema presentan SATAN, un escáner automático de vulnerabilidades, que se convierte en una popular herramienta de hacking. Ese mismo año, en 1995 el término “hacking ético” fue acuñado por el vicepresidente de IBM, John Patrick. A finales de la década de los 90, en 1999 la seguridad del software toma más importancia aún con el lanzamiento de Windows 98 de Microsoft. 1999 se convierte en un año excepcional para la seguridad (y la piratería). Los años posteriores hasta la actualidad se caracterizan por la continuidad de los ciberdelitos y un gran crecimiento en su escala, el desarrollo de la industria de las auditorias de seguridad y el desarrollo de la legislación para combatir el cibercrimen. Los delitos de cibercrimen afectan particulares y empresas de todos los tamaños. En los últimos años han ocurrido números hacks de alto perfil en enormes compañías como eBay y Sony, provocando cuantiosas pérdidas entre las empresas afectadas. El impacto económico de todos estos cibercrímenes es reflejado por informe oficial anual sobre cibercrimen de 2021, por Cybersecurity Ventures. Según el informe el cibercrimen tendrá un coste en daños de 6 trillones de dólares anuales en 2021, 3 trillones más que en 2015.
Respecto a la industria de las auditorias de seguridad, esta ha sufrido un proceso de profesionalización gracias desarrollo de estándares para realizar pruebas de penetración (con la publicación de la primera guía de pruebas OWASP en 2003 y la fundación del PTES en 2009) y el creciente número de cursos de formación en la materia. También se observa el desarrollo de la industria en términos económicos, llegando a un gasto mundial en seguridad empresarial que alcanzó los 71.1 billones de dólares en 2014.
CONCEPTOS, TÉCNICAS Y METODOLOGÍA.
FASES DE UN PENTEST. El desarrollo de este apartado se basa en las directrices, contenidos y estructuras presentes en el estándar PTES (Penetration Testing Execution Standard) ampliando sus contenidos con Pentesting con Kali 2.0. Una prueba de penetración se compone de las siguientes fases:
Interacciones previas al compromiso.
Recolección de información.
Modelado de amenazas.
Análisis de vulnerabilidades.
Explotación.
Post-explotación.
Reporte.
A continuación, se detalla cada una de estas fases.
INTERACIONES PREVIAS AL COMPROMISO. Esta primera fase del pentest define la planificación y las interacciones entre el pentester y el cliente antes de realizar las pruebas. Una mala realización de las actividades previas al compromiso puede suponer problemas como scope creep2 , clientes insatisfechos o incluso problemas legales. El pentest debe estar orientado al cumplimiento de una meta. Esto quiere decir que el objetivo de la prueba es identificar las vulnerabilidades específicas que conducen al compromiso de los objetivos comerciales del cliente. Antes de comenzar una prueba de penetración es beneficioso determinar el nivel de madurez de la postura de seguridad del cliente. De esta manera, en el caso de clientes con un programa de seguridad muy inmaduro, suele ser una buena idea realizar inicialmente un análisis de vulnerabilidades. También se ha de establecer, primeramente, con el cliente, qué información sobre los sistemas proporcionará. Por ejemplo, puede ser útil solicitar información sobre vulnerabilidades que ya están documentadas. Esto ahorrará tiempo a los pentesters y ahorrará dinero al cliente al evitar la realización de algunas pruebas. De esta manera, una prueba de caja blanca o gris puede brindar al cliente más valor que una prueba de caja negra, si los requerimientos del pentest no lo exigen.
DEFINICIÓN DEL ALCANCE. El alcance del pentest define específicamente que se probará. Para ello, se realiza la reunión de alcance (Scoping Meeting), que tiene como objetivo discutir lo que será probado con el cliente. Normalmente, la reunión tiene lugar una vez firmado el contrato, pero hay situaciones en las que muchos de los temas relacionados con el alcance pueden discutirse antes de la firma del contrato. Para esas situaciones, se recomienda que se firme un acuerdo de confidencialidad previamente. Las reglas del compromiso y costes no son tratados en esta reunión. Cada uno de estos temas debe manejarse en reuniones donde cada tema es el foco de esa reunión. Todo lo que no esté explícitamente cubierto dentro del alcance del pentest debe manejarse con mucho cuidado. La primera razón para esto es el scope creep. Cualquier solicitud fuera del alcance original debe documentarse en forma de una declaración de trabajo que identifique claramente el trabajo a realizar. Por otra parte, es recomendable claramente en el contrato que el trabajo adicional se realizará por una tarifa plana por hora y se establezca explícitamente que el 2 Scope creep: (cambios no controlados en el alcance de un proyecto) es uno de los problemas más peligrosos para una firma de pentest, llegando a provocar el cierre de la firma. Scope creep puede dar lugar a que el equipo que realiza el pentest exceda el presupuesto y cronograma del pentest aumentando el número de tareas a realizar por el mismo coste. 9 trabajo adicional no puede completarse hasta que se haya establecido un SOW (Statement Of Work) firmado. Cuestionarios. Durante las comunicaciones iniciales con el cliente, hay varias preguntas que el cliente tendrá que responder para que el alcance pueda ser bien definido. Estas preguntas están diseñadas para proporcionar una mejor comprensión de lo que el cliente busca obtener de la prueba de penetración. Dependiendo del ámbito del pentest, los cuestionarios presentados al cliente pueden variar. A modo de ejemplo se presenta un cuestionario de pentest de aplicación web:
¿Cuántas aplicaciones web se están evaluando?
¿Cuántos sistemas de inicio de sesión se están evaluando?
¿Cuántas páginas estáticas se están evaluando? (aproximado)
¿Cuántas páginas dinámicas se están evaluando? (aproximado)
¿El código fuente estará disponible?
¿Habrá algún tipo de documentación? En caso afirmativo, ¿qué tipo de documentación?
¿Se realizará el análisis estático en esta aplicación?
¿El cliente quiere que se realice un proceso de fuzzing en esta aplicación?
¿El cliente desea realizar pruebas basadas en roles contra esta aplicación?
¿El cliente desea que se realicen escaneos con credenciales? Estimación del tiempo.
En la definición del alcance es importante fijar una fecha límite para la finalización del pentest para mitigar riesgos. La capacidad de estimar, de manera precisa, el tiempo de las pruebas está directamente relacionada con la experiencia del pentester.
En caso de duda, el pentester puede acudir a los registros de pruebas similares realizadas por su firma para estimar el tiempo requerido. Una vez determinado el tiempo para la prueba, es una práctica prudente agregar un 20% al tiempo estimado previniendo posibles complicaciones. Si el 20 % extra de tiempo acaba siendo innecesario depende del pentester aportar valor añadido a la prueba durante ese tiempo. Especificar entornos dentro del alcance. Una vez establecido el orden aproximado de magnitud del proyecto, es hora de tener una reunión con el cliente para validar los supuestos. En primer lugar, se deben identificar todos los objetivos.
Los objetivos se pueden proporcionar en forma de direcciones IP específicas, rangos de red o nombres de dominio. En algunos casos, el único objetivo que brinda el cliente es el nombre de la organización y espera que los pentesters puedan identificar el resto por sí mismos, sin embargo, los posibles problemas legales deben considerarse por encima de todo. Debido a esto, es responsabilidad del pentester transmitirle al cliente estas inquietudes.
Por ejemplo, en la reunión, se debe verificar que el cliente posea todos los entornos de destino (servidor DNS, el servidor de correo electrónico, el hardware real en el que se ejecutan sus servidores web, etcétera). Además, deben identificarse los países, provincias y estados en los que operan los entornos objetivo. Esto se debe a que las leyes varían de una región a otra y las pruebas pueden verse afectadas por estas. También es importante definir si los sistemas como firewalls y IDS / IPS o equipos de red, que se encuentran entre el pentester y el objetivo final, también forman parte del alcance. Finalmente, Deben identificarse y definirse los servicios proporcionados por terceros, de manera que se verifique si se encuentran dentro del alcance o no. En caso afirmativo, deben conseguirse los permisos necesarios para actuar sobre estos servicios.
COMUNICACIÓN. Uno de los aspectos más importantes de cualquier prueba de penetración es la comunicación con el cliente. La regularidad de los reportes y las formas de comunicarse con el cliente afecta de forma considerable a su grado de satisfacción. 10 Información de contacto de emergencia. Un aspecto vital es poder ponerse en contacto con el cliente durante una emergencia para ser capaz de gestionarla. Para ello es útil una lista de contactos de emergencia.
Esta lista debe incluir información de contacto de todas las partes implicadas en el alcance de las pruebas. Una vez creada, debe compartirse con todos los que están en la lista. Respuesta a incidentes. El National Institute of Standards and Technology (NIST) define un incidente como: “una violación o amenaza inminente de violación de las políticas de seguridad informática, políticas de uso aceptable o prácticas estándar de seguridad”. Antes de un compromiso, es importante hablar sobre las capacidades de respuesta a incidentes de la organización por varias razones.
En parte, una prueba de penetración está destinada a probar las capacidades de respuesta a incidentes de la organización. Esto quiere decir que, si se puede completar el pentest sin alertar a los equipos de seguridad interna, se ha identificado una brecha importante en la postura de seguridad del cliente. Por otra parte, es importante asegurarse, antes de comenzar las pruebas, que alguien en la organización objetivo sepa cuándo cuando van a realizarse. De esta manera, el equipo de respuesta a incidentes no empezará a llamar a todos los miembros de la alta gerencia, en mitad de la noche, pensando que la organización ha sido comprometida. Informes. Se debe determinar la frecuencia y el cronograma de informes de estado para mantener al cliente informado e involucrado. Por otra parte, debido a la naturaleza sensible del compromiso, las comunicaciones de información confidencial deben estar encriptadas, especialmente el informe final. Por tanto, antes de que comience la prueba, debe establecerse un medio de comunicación seguro con el cliente.
REGLAS DEL COMPROMISO. Mientras alcance define lo que se probará, las reglas del compromiso definen cómo se realizará la prueba. Estos son dos aspectos diferentes que deben manejarse de manera independientemente. Cronograma. Debe establecerse un cronograma claro para el compromiso. Si bien el alcance define el inicio y el final de un compromiso, las reglas de trabajo definen todo lo que está en medio. Tener un cronograma al comienzo de una prueba permitirá a todos los involucrados identificar más claramente el trabajo que a realizar y las personas que serán responsables de dicho trabajo. Además, ver el calendario desglosado de esta manera ayuda a los involucrados a identificar dónde se deben aplicar los recursos y ayuda al cliente a identificar posibles obstáculos durante la realización de las pruebas. Por otra parte, debe entenderse que el cronograma cambiará a medida que avanza la prueba, por lo que es necesario que sea flexible.
Localizaciones. Otro parámetro importante de cualquier compromiso es establecer, antes de tiempo, con el cliente, cualquier destino al que los pentesters deberán viajar durante la prueba. Esto podría ser tan simple como identificar hoteles locales o complejo como identificar las leyes aplicables de un país específico. No es raro que una organización opere en múltiples ubicaciones y algunos sitios tendrán que ser elegidos para la prueba. En estas situaciones, se debe evitar viajar a cada ubicación del 11 cliente, en su lugar, se debe determinar si las conexiones VPN a los sitios están disponibles para pruebas remotas. Confidencialidad de información sensible. Si bien uno de los objetivos de un trabajo determinado puede ser obtener acceso a información confidencial, cierta información no debe verse ni descargarse. Esto es, hay una serie de situaciones en las que los pentesters no deberían tener los datos de destino en su poder.
Por ejemplo, los Personal Health Information (PHI), en conformidad con la ley Health Insurance Portability and Accountability Act (HIPAA), deben estar protegidos. En el caso de nuestra legislación vigente se considerará la Ley Orgánica de Protección de Datos y el nuevo marco legislativo europeo, la General Data Protection Regulation, de aplicación a partir de marzo del 2018.
Sin embargo, si los datos no pueden obtenerse física o virtualmente, ¿cómo puede probarse que los pentesters efectivamente obtuvieron acceso a la información? Este problema se ha resuelto de varias maneras. Por ejemplo, se puede tomar una captura de pantalla del esquema de la base de datos y de los permisos del archivo, o se pueden mostrar los archivos sin abrirlos para mostrar el contenido, siempre que no haya Personally Identifiable Information (PII) visible en los nombres de los archivos. Lo cautelosos que deben ser los pentesters en un compromiso dado es un parámetro que debe discutirse con el cliente, pero la empresa que realiza la prueba siempre debe asegurarse de protegerse en un sentido legal, a pesar de la opinión del cliente.
Además, Independientemente de la supuesta exposición a datos confidenciales, todas las plantillas de informes y las máquinas de prueba se deben sanear lo suficiente después de cada compromiso. Por otra parte, si los probadores descubren datos ilegales (como pornografía infantil), se debe notificar a las autoridades pertinentes y, a continuación, al cliente. Horario de las pruebas. Ciertos clientes requieren que todas las pruebas se realicen fuera del horario comercial. Esto puede significar noches tardías para la mayoría de los probadores.
Por tanto, los requisitos de la hora del día deben estar bien establecidos con el cliente antes de que comience la prueba. Evasión de ataques. Hay momentos en que la evasión es perfectamente aceptable y hay momentos en los que puede no ajustarse a las características de la prueba. Por ejemplo, si se trata de una prueba de caja negra completa donde se está probando no solo la tecnología, sino las capacidades del equipo de seguridad de la organización objetivo, la evasión sería correcta. Sin embargo, cuando se está probando una gran cantidad de sistemas en coordinación con el equipo de seguridad de la organización objetivo, puede que no sea lo mejor para la prueba evitar los ataques. Permisos. Uno de los documentos más importantes que deben obtenerse para una prueba de penetración es el documento de permiso para probar. Este documento establece el alcance y contiene una firma que reconoce el conocimiento de las actividades de los pentesters. Además, debe indicar claramente que las pruebas pueden conducir a la inestabilidad del sistema y que el pentester proporcionará todos los cuidados necesarios para no bloquear los sistemas en el proceso. Sin embargo, dado que las pruebas pueden generar inestabilidad, el cliente no deberá responsabilizar al pentester de la inestabilidad o fallos del sistema. Es fundamental que las pruebas no comiencen hasta que el cliente haya firmado este documento.
Conclusiones:
El pentesting se ha vuelto en una herramienta fundamental para comprobar la seguridad de los sistemas, tal como hemos dicho anteriormente, se ha profesionalizado con metodologías, certificaciones y estándares que garantizan de alguna manera la profundidad de las pruebas a los que someten los sistemas analizados.

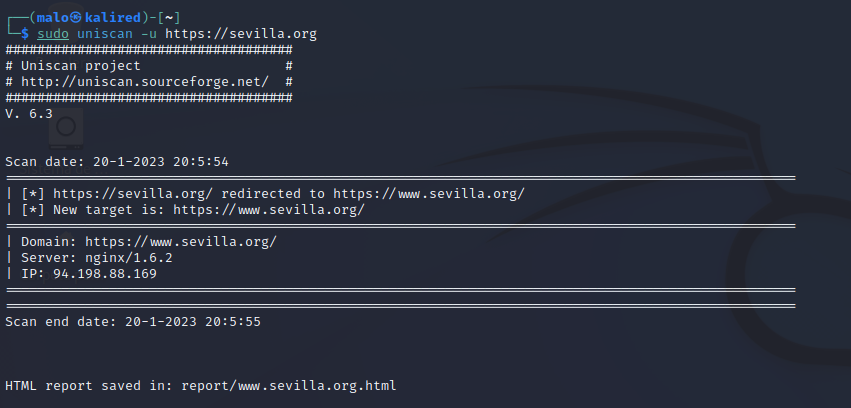
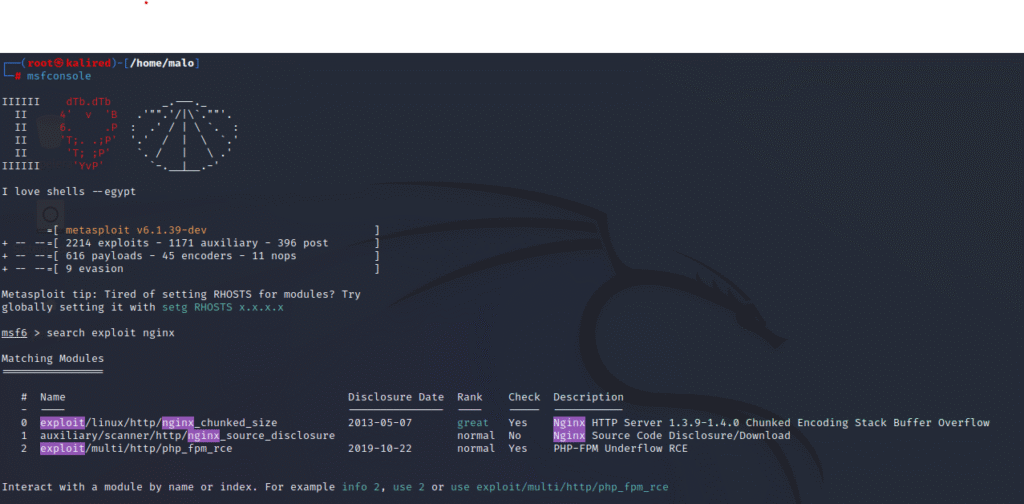
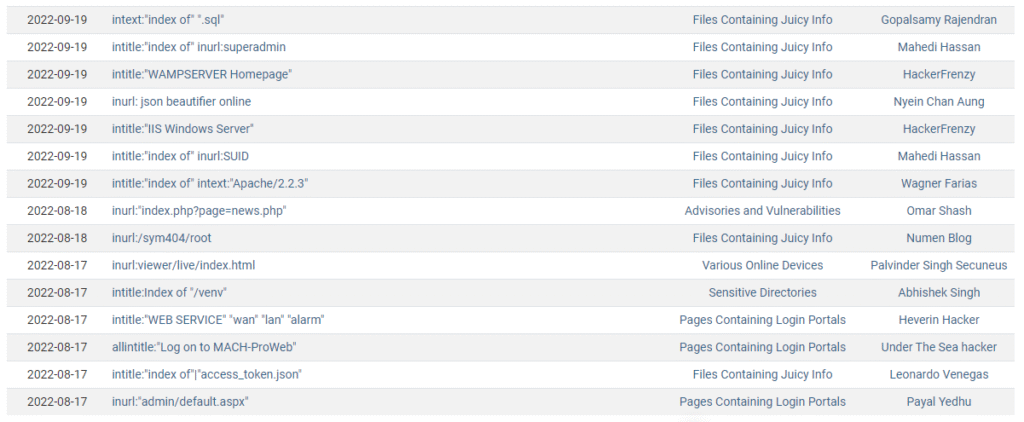
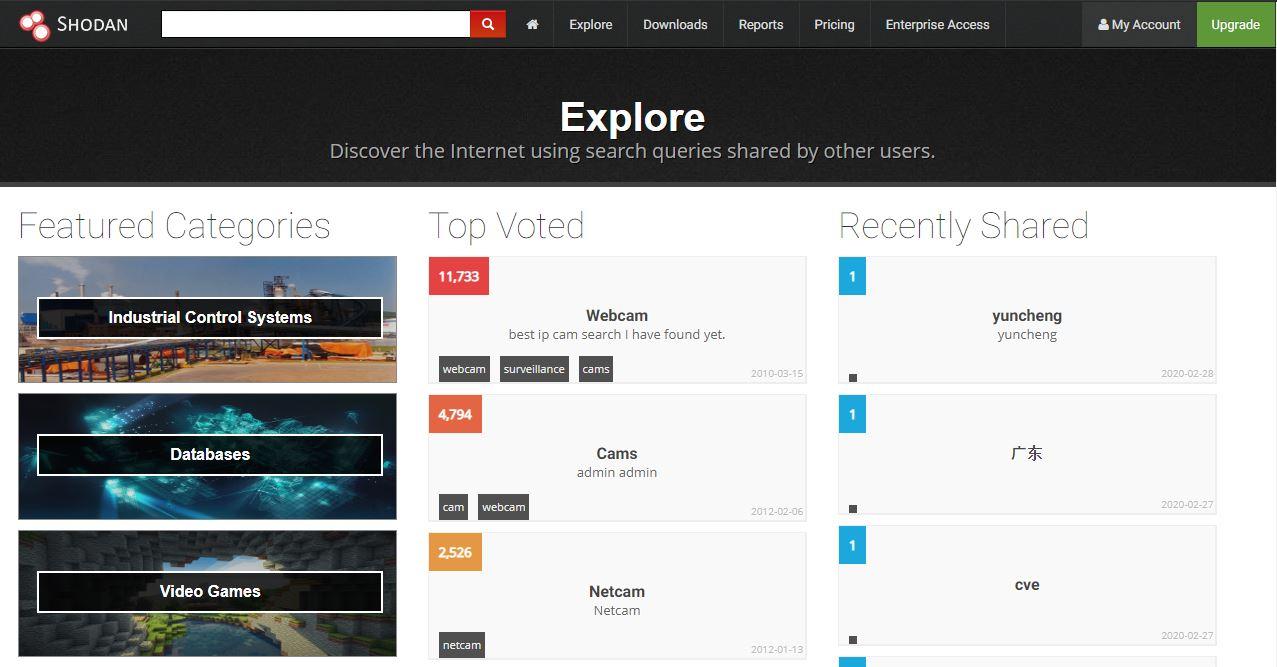
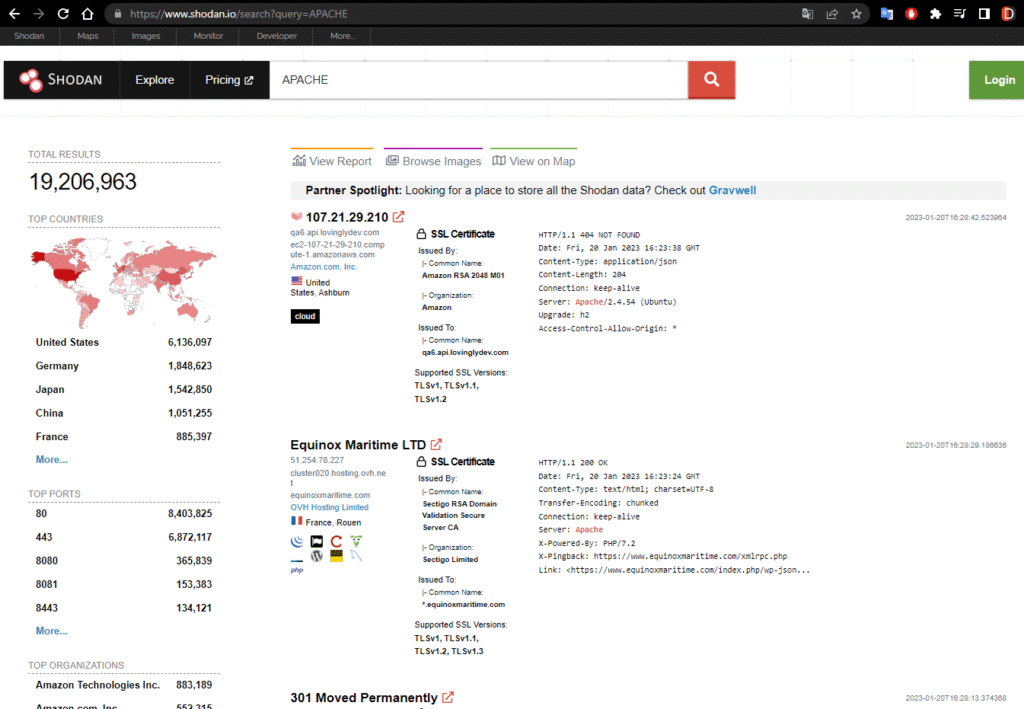
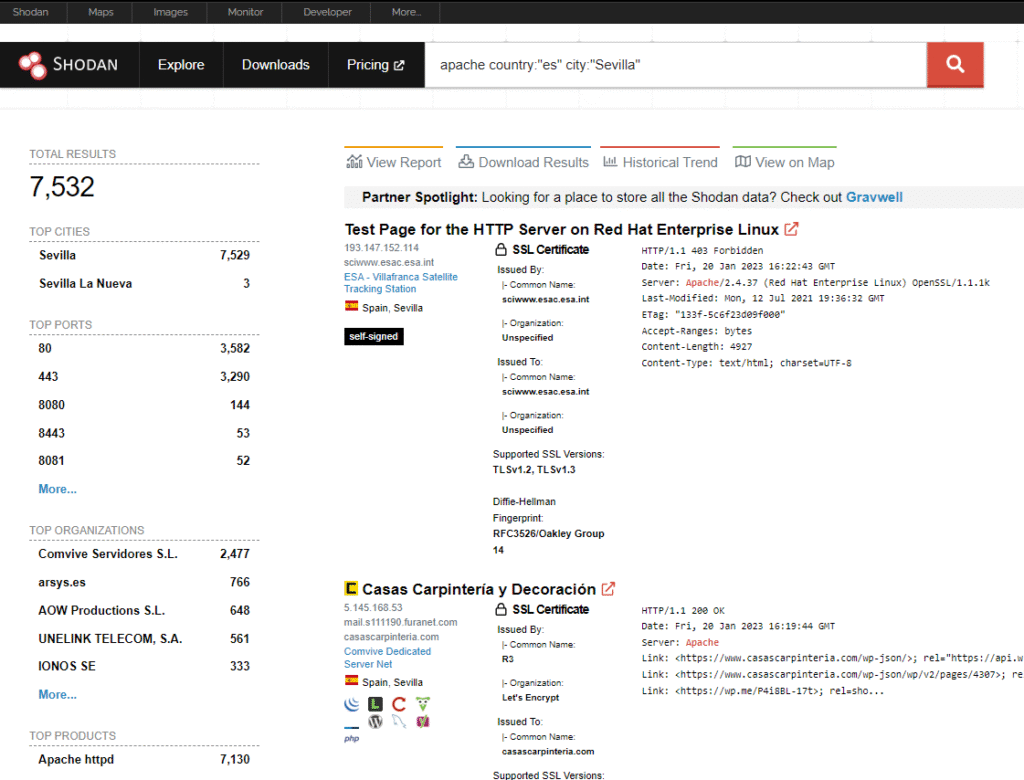

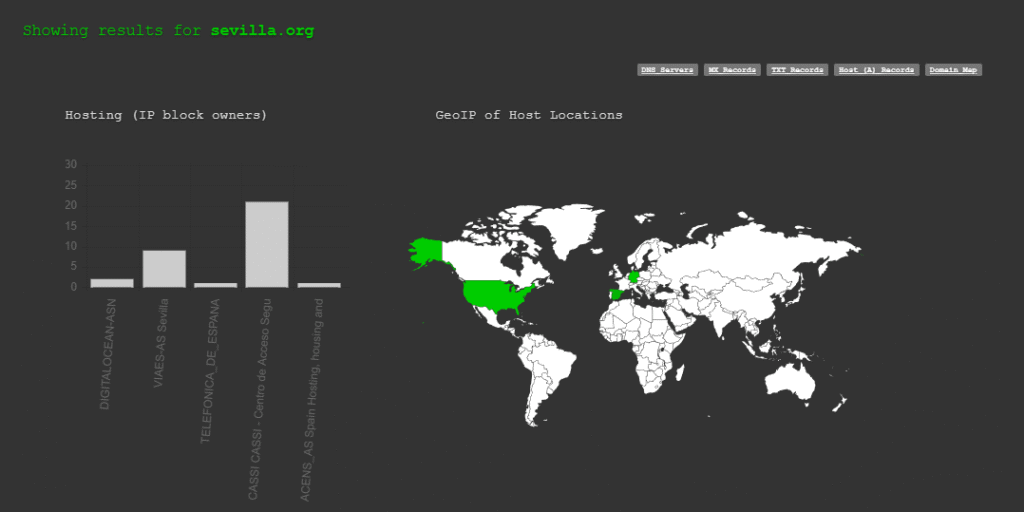
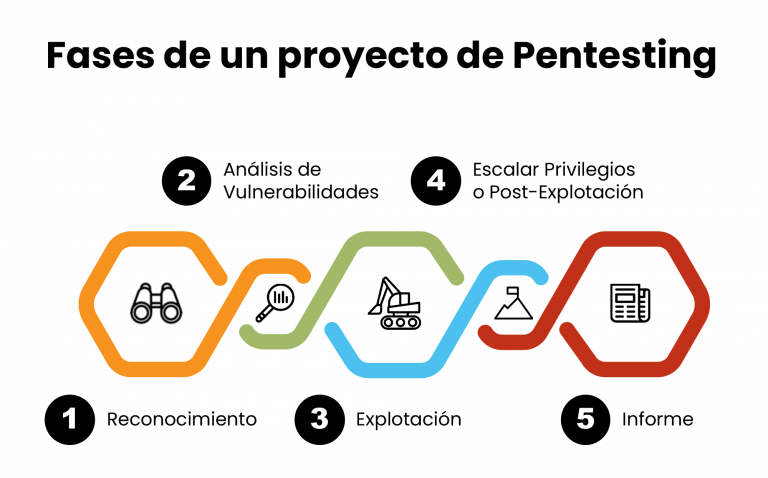





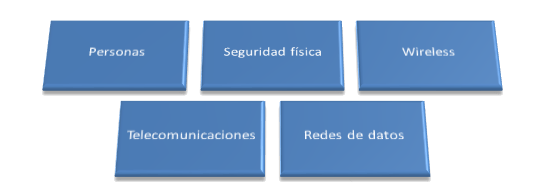

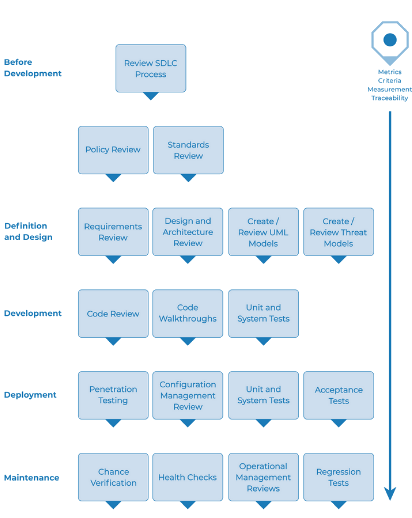



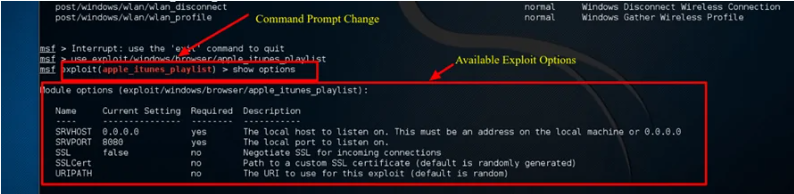
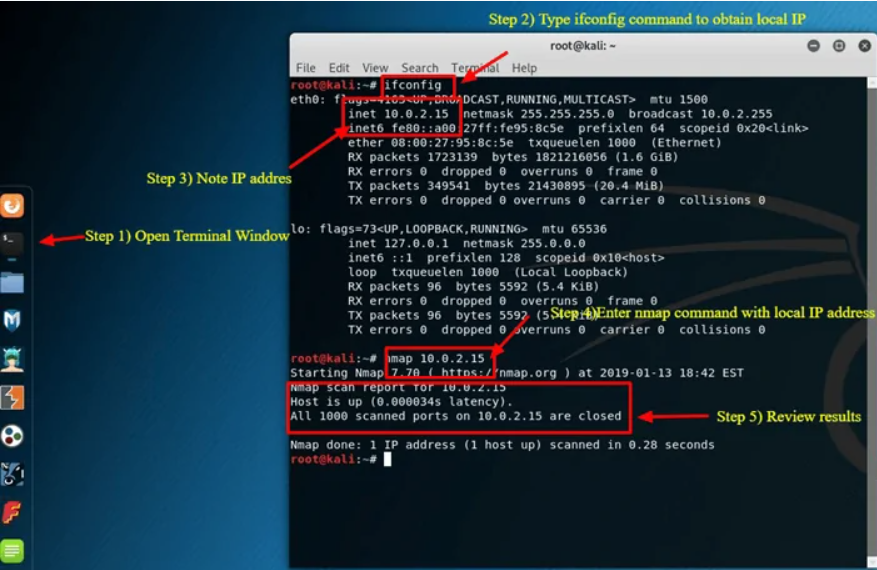
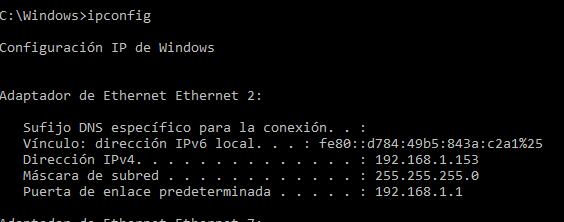
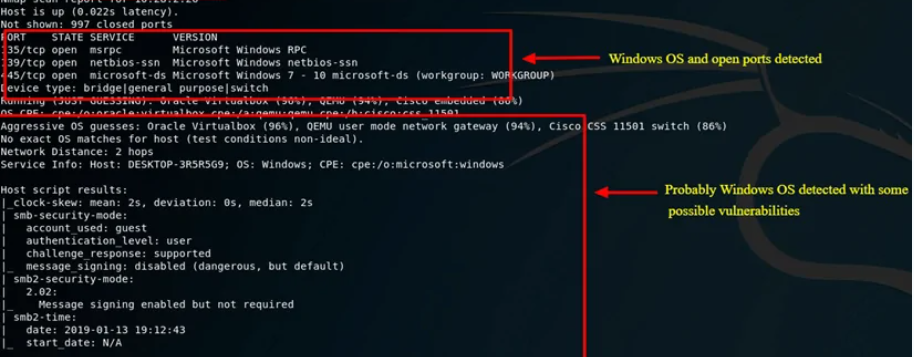
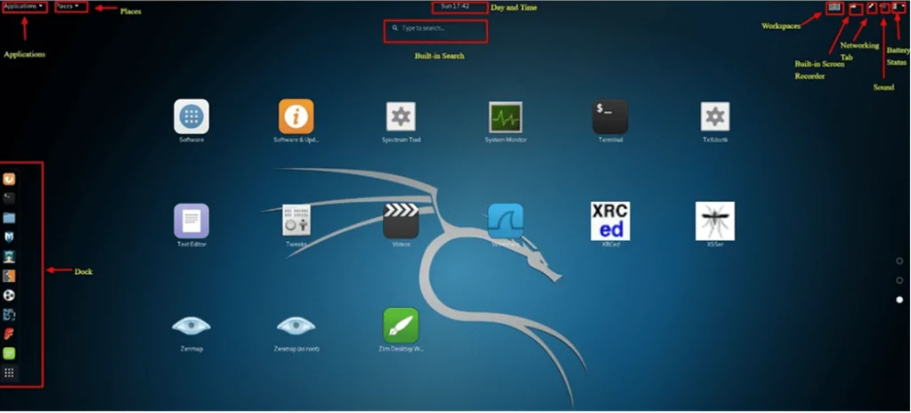
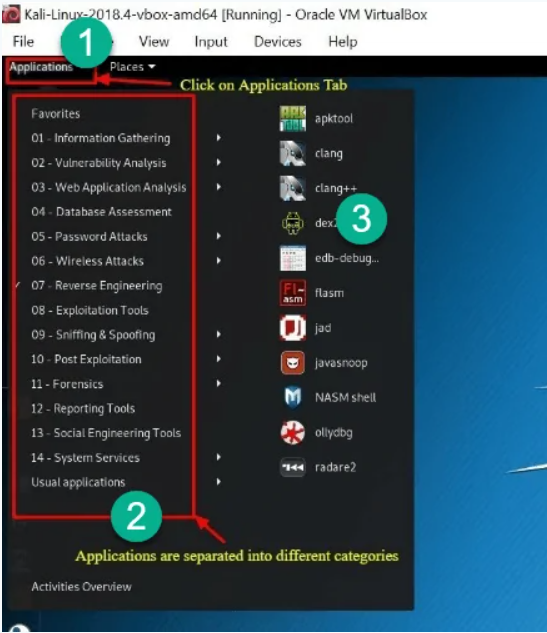
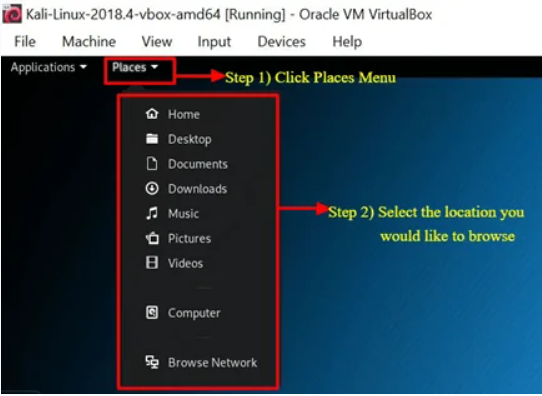
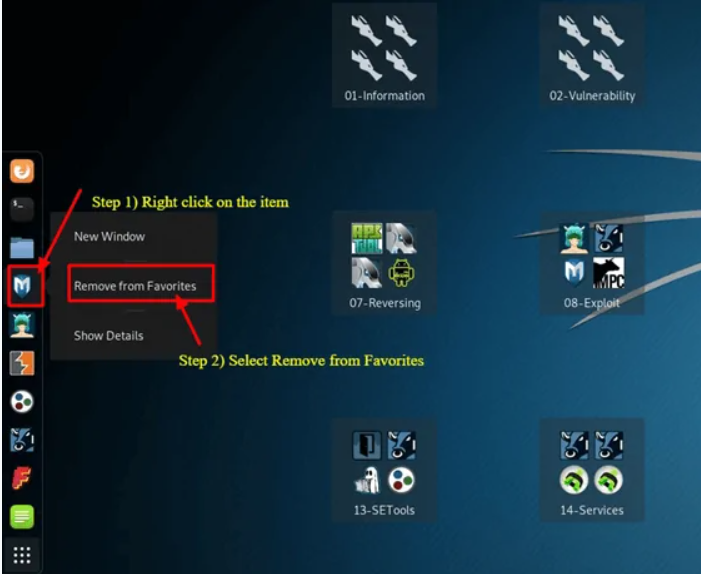
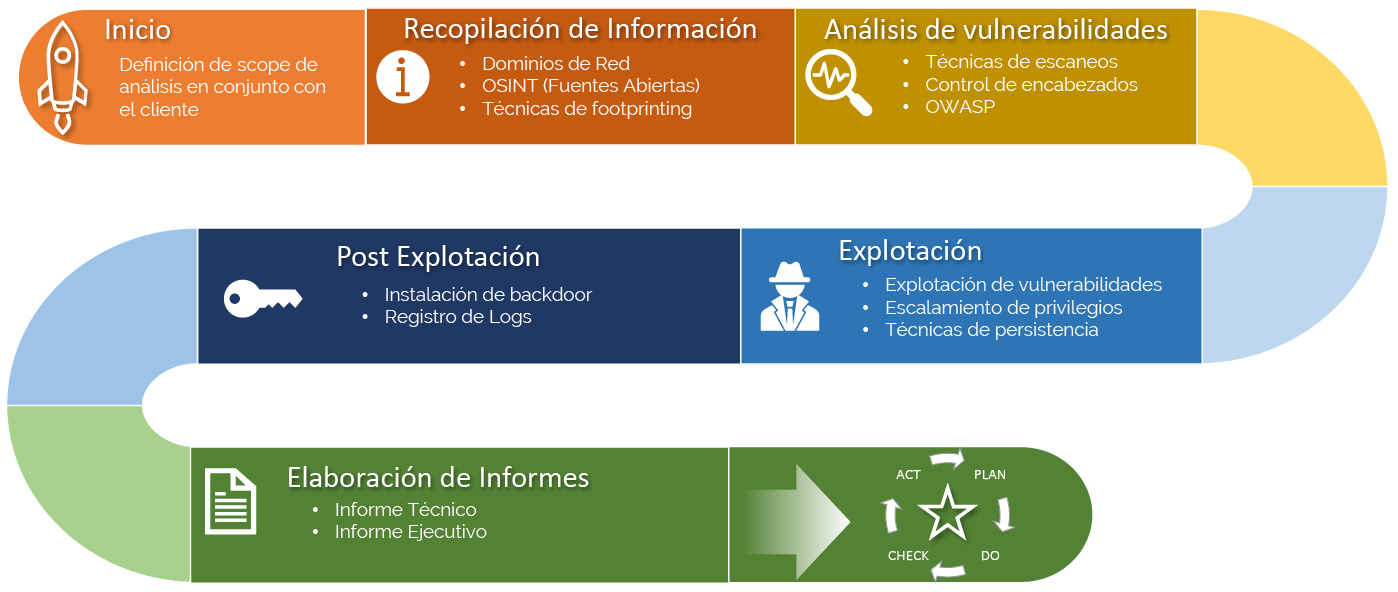
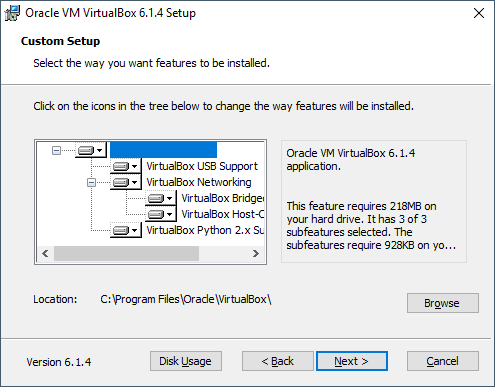
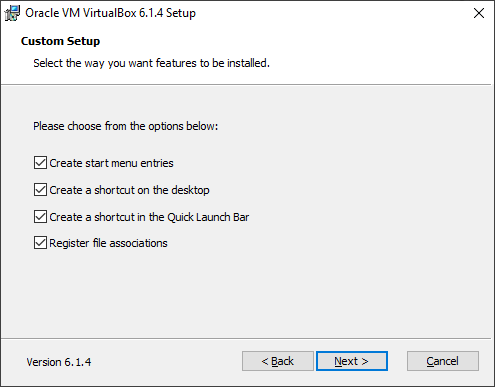
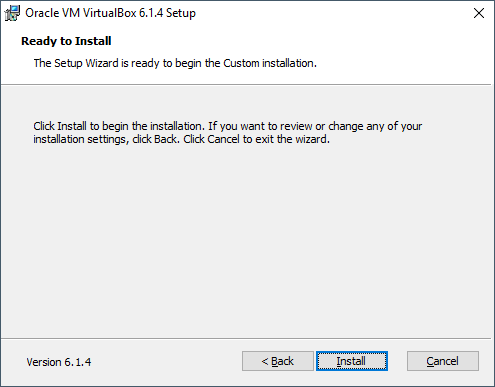
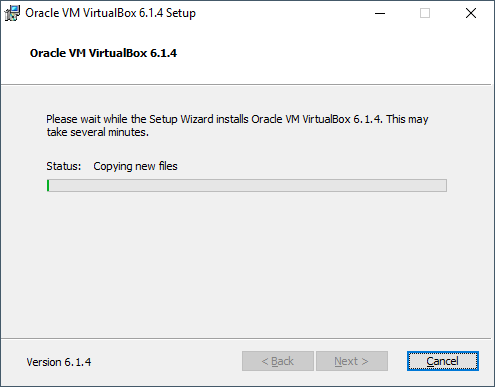
 Paso 3: Da un nombre a la máquina virtual y selecciona en qué carpeta se almacenará.
Paso 3: Da un nombre a la máquina virtual y selecciona en qué carpeta se almacenará. Paso 5: Elige qué disco se añadirá a la máquina virtual. Por defecto se optará por crear un nuevo disco virtual.
Paso 5: Elige qué disco se añadirá a la máquina virtual. Por defecto se optará por crear un nuevo disco virtual.