Autopy software forense
Introducción a Autopsy
No podemos dejar de hablar de informática forense, si no vemos una excelente herramienta que acompaña a todos sitios a cualquier forense. Y esa herramienta es Autopsy.

Sí, lo sé, quizás el icono del perro no ayude mucho, pero cuando empieces a utilizarla no vas a querer dejar al perro atado, siempre lo llevarás a todas partes.
Una descripción de Autopsy sería:
“Autopsy es la principal plataforma forense de código abierto que es rápida, fácil de usar y capaz de analizar todo tipo de dispositivos móviles y medios digitales. Su arquitectura de complemento permite la extensibilidad desde desarrollado por la comunidad o personalizado- los módulos construidos de Autopsia evolucionan para satisfacer las necesidades de cientos de miles de profesionales en el cumplimiento de la ley, la seguridad nacional, el apoyo en litigios y la investigación corporativa.”
Instalando Autopsy
Sino tienes Autopsy, puedes descargarlo desde aquí.
Creación de un nuevo caso
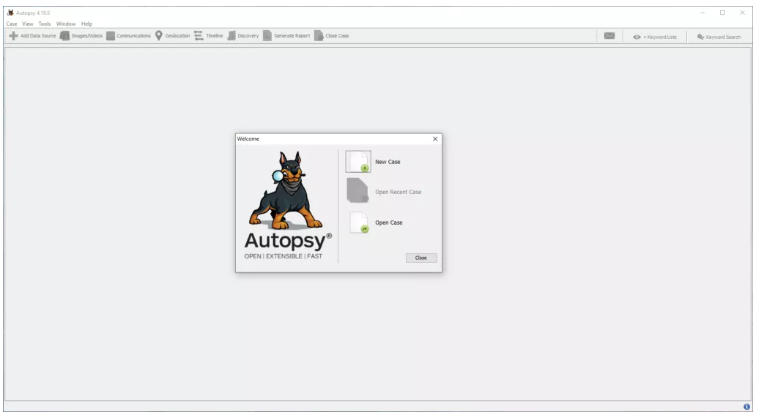
Ejecuta la herramienta de Autopsy en tu sistema operativo Windows y haz clic en “New Case” (“Nuevo Caso“) para crear un nuevo caso:
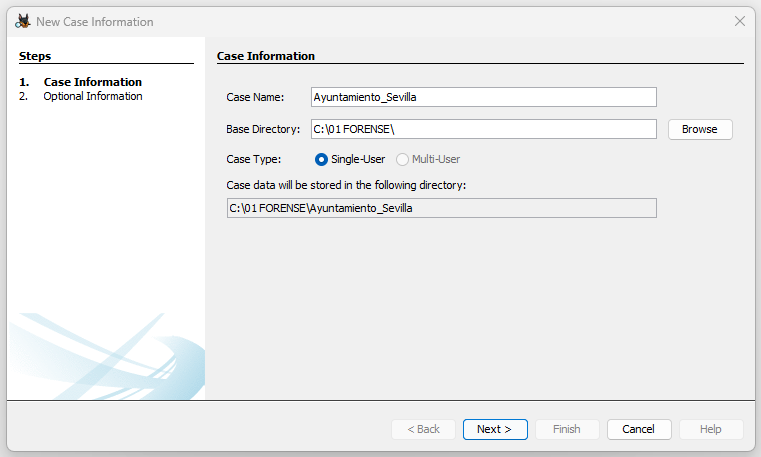
A continuación, se rellena toda la información necesaria del caso, como el nombre del mismo, y se elige un directorio base para guardar todos los datos del caso en un solo lugar:
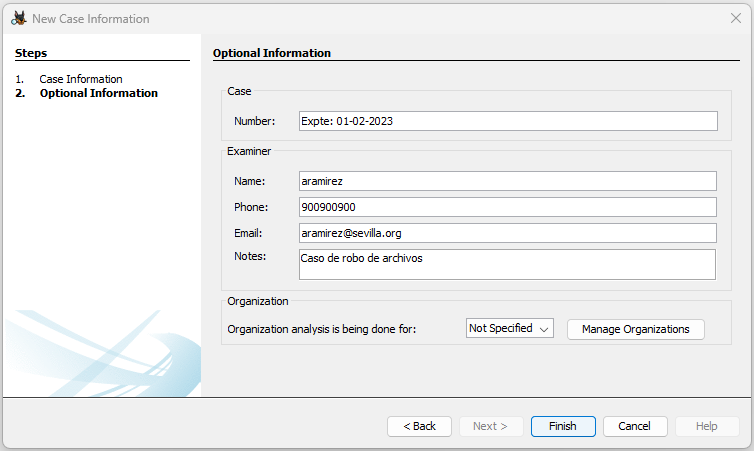
También puedes añadir información adicional opcional sobre el caso si es necesario:
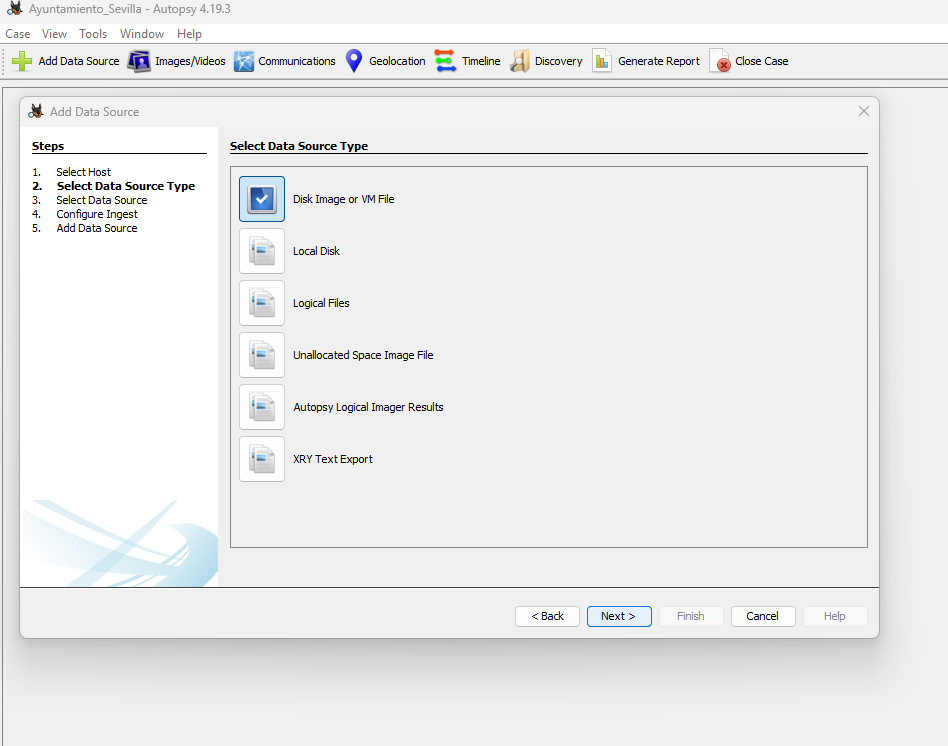
Ahora vamos a añadir el tipo de fuente de datos. Hay varios tipos para elegir:
- Disk Image or VM file: Esto incluye el archivo de imagen que puede ser una copia exacta de un disco duro, una tarjeta multimedia o incluso una máquina virtual.
- Local Disk: Esta opción incluye dispositivos como discos duros, pen drives, tarjetas de memoria, etc.
- Logical Files: Incluye la imagen de cualquier carpeta o archivo local.
- Unallocated Space Image File: Incluyen archivos que no contienen ningún sistema de archivos y se ejecutan con la ayuda del módulo Ingest.
- Autopsy Logical Imager Results: Incluyen la fuente de datos de la ejecución del generador de imágenes lógicas.
- XRY Text Export: Incluyen la fuente de datos de la exportación de archivos de texto desde XRY.
A continuación, se te pedirá que configures el módulo Ingest:
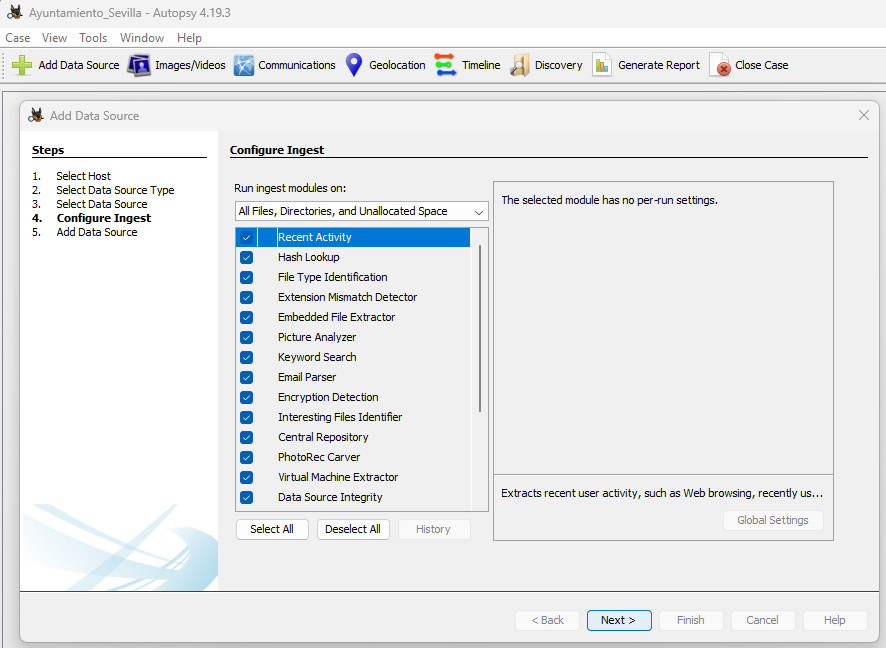
El contenido del módulo Ingest se encuentra en la siguiente lista:
- Detalles del Módulo Ingest: La información de la fuente de datos (Data Source) muestra los metadatos básicos. Su análisis detallado se muestra en la parte inferior. Se puede extraer uno tras otro.
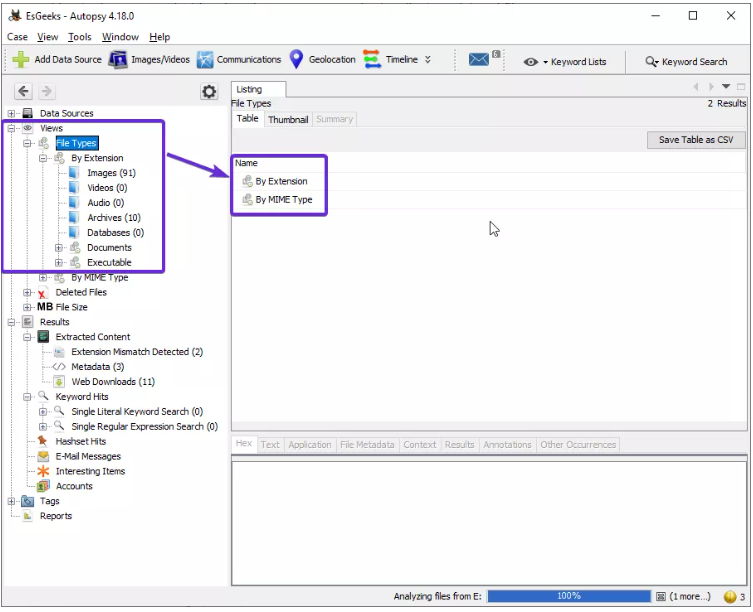
- VISTAS File Type (Tipo de archivo): se puede clasificar en forma de extensión de archivo o tipo MIME.
Proporciona información sobre las extensiones de archivo que suelen ser utilizadas por el sistema operativo, mientras que los tipos MIME son utilizados por el navegador para decidir qué datos representar. También muestra los archivos eliminados.
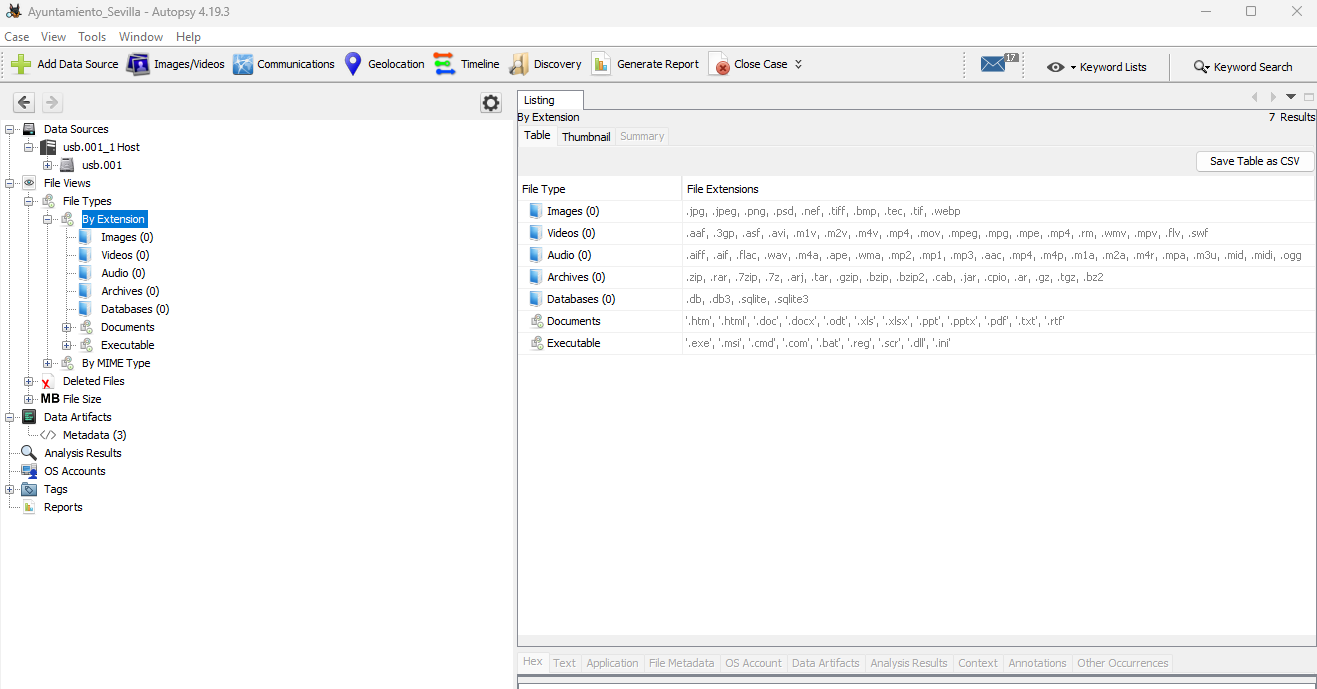
- POR EXTENSIÓN (By Extension): puedes ver que se ha subdividido en tipos de archivo como imágenes, vídeo, audio, archivos, bases de datos, etc.
Vamos a hacer clic en las imágenes y explorar las imágenes que se han recuperado:
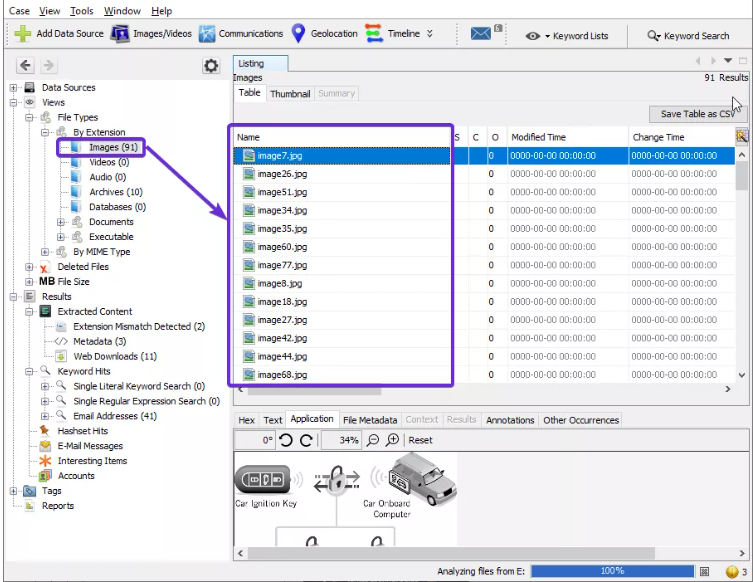
También podemos ver la miniatura de las imágenes:
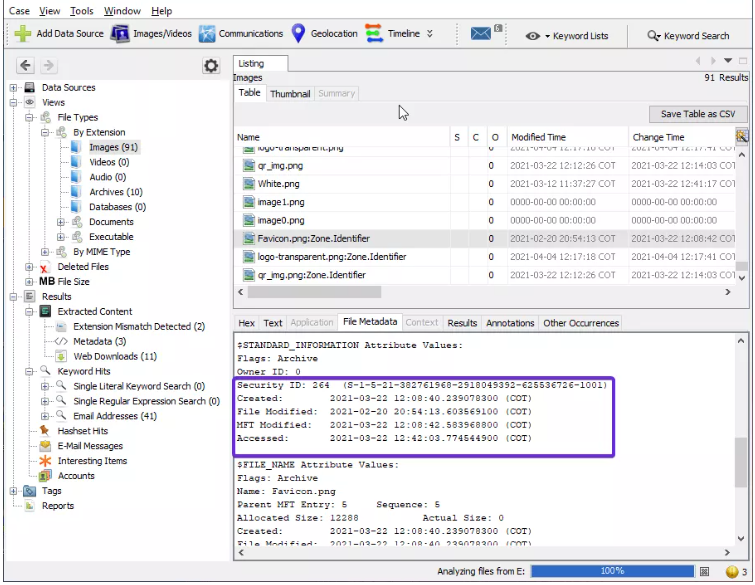
Al ver la miniatura, se pueden ver los metadatos del archivo y los detalles de la imagen:
Aquí también podemos ver algunos archivos del tipo “Archives” que se han recuperado. Podemos extraer estos archivos del sistema y visualizarlos utilizando varios programas:
- DOCUMENTOS: los documentos se clasifican en 5 tipos: HTML, Office, PDF, Texto sin formato (Plain Text) y Texto enriquecido (Rich Text).
Al explorar la opción de documentos, puedes ver todos los documentos PDF presentes, puedes hacer clic en los importantes para verlos.
Al explorar la opción de PDF, también puedes encontrar el PDF importante en la imagen del disco:
Del mismo modo, los diversos archivos de texto plano también se pueden ver. También puedes recuperar los archivos de texto plano eliminados.
- EJECUTABLES: estos tipos de archivos se subdividen en .exe, .dll, .bat, .cmd y .com.
- POR TIPO MIME: en este tipo de categoría, hay cuatro subcategorías como aplicación, audio, imagen y texto. Estas se dividen a su vez en más secciones y tipos de archivo.
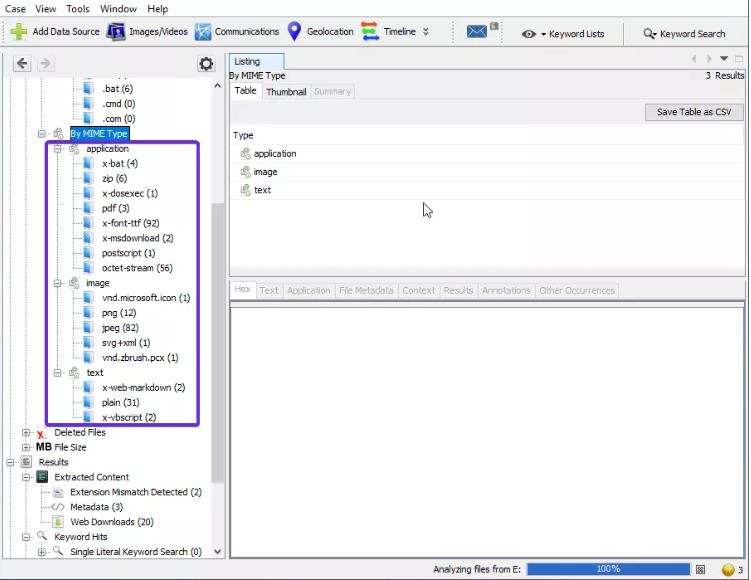
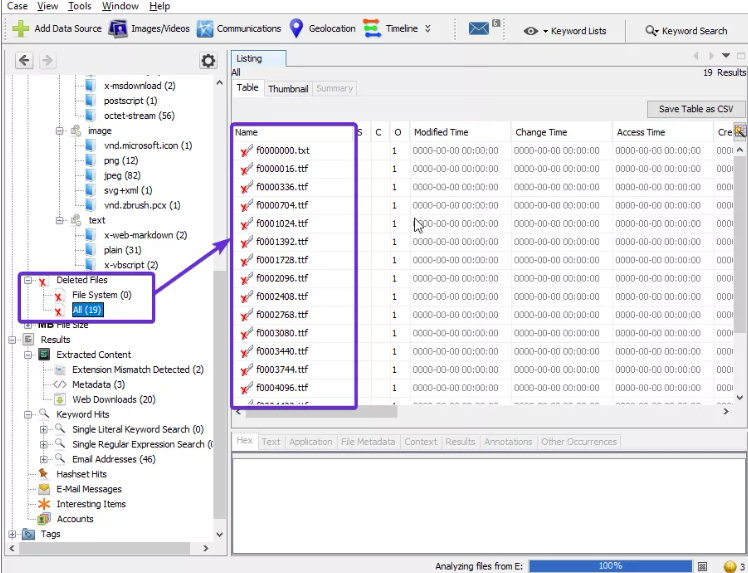
- ARCHIVOS ELIMINADOS (Deleted Files): muestra información sobre el archivo eliminado que luego se puede recuperar.
- ARCHIVOS DE TAMAÑO MB (MB Size Files):en esta sección, los archivos se clasifican en función de su tamaño, a partir de 50 MB. Esto permite al examinador buscar archivos de gran tamaño.
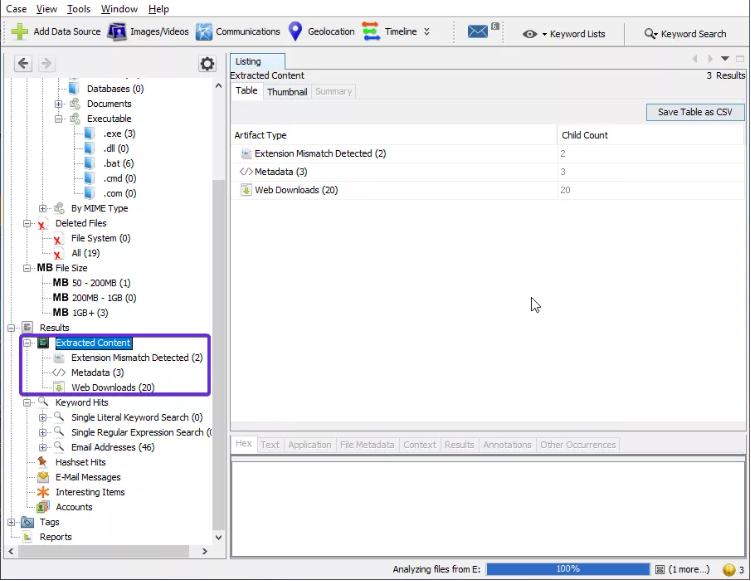
- CONTENIDO EXTRAÍDO (Extracted Content): todo el contenido que fue extraído, es segregado en detalle. Aquí hemos encontrado metadatos, papelera de reciclaje y descargas web. Veamos más a fondo cada uno de ellos.
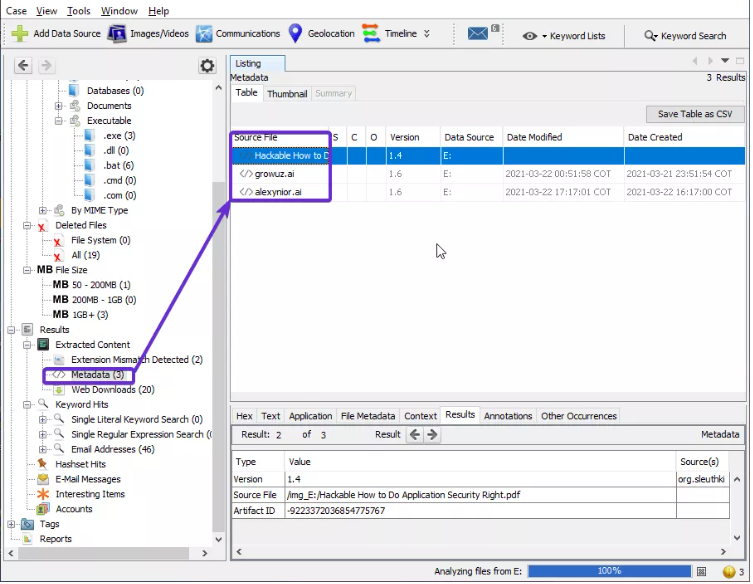
- Metadatos (Metadata): aquí podemos ver toda la información sobre los archivos como la fecha de creación, de modificación, el propietario del archivo, etc.
- Descargas Web (Web Downloads): aquí se pueden ver los archivos que fueron descargados de internet.
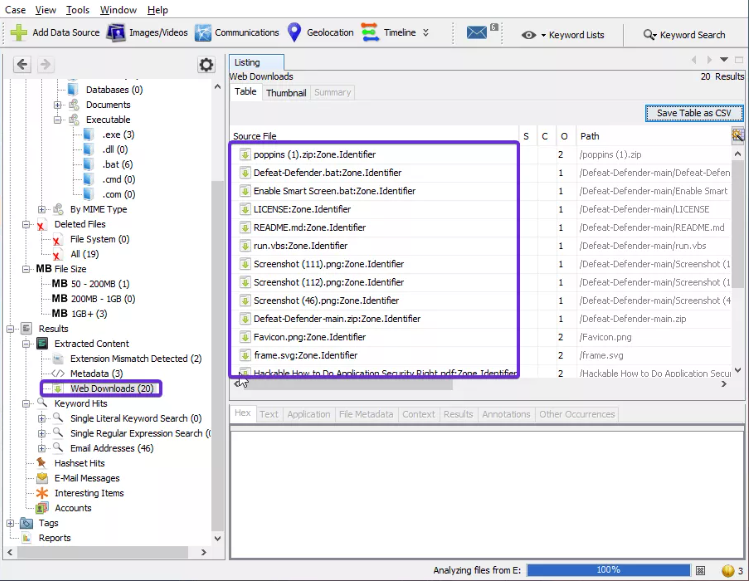
- PALABRAS CLAVE (Keyword Hits): aquí se puede buscar cualquier palabra clave específica en la imagen de disco. La búsqueda se puede realizar con respecto a la coincidencia exacta, coincidencias de subcadena, correos electrónicos, palabras literales, expresiones regulares, etc.
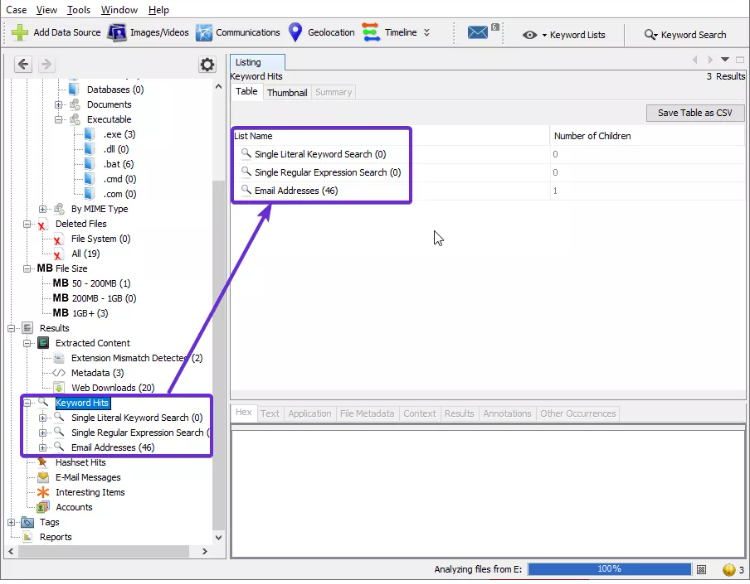
Puedes ver las direcciones de correo electrónico disponibles:
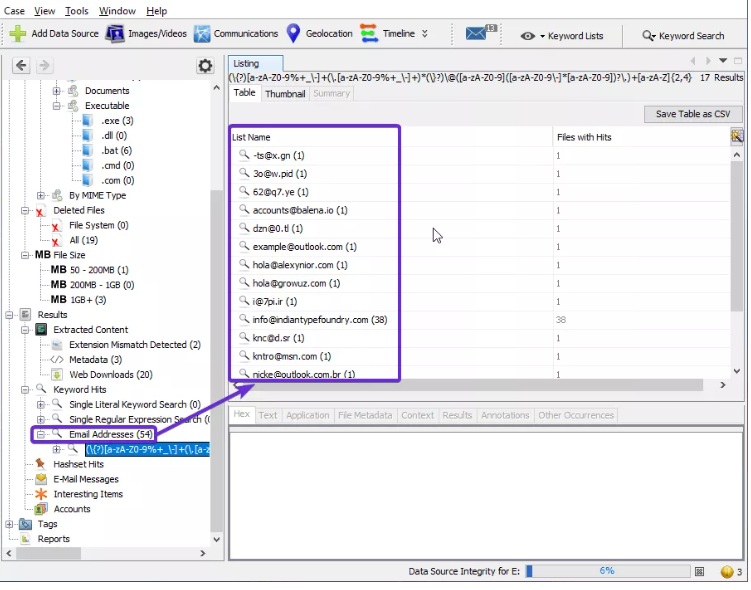
Se puede optar por exportar a un formato CSV.
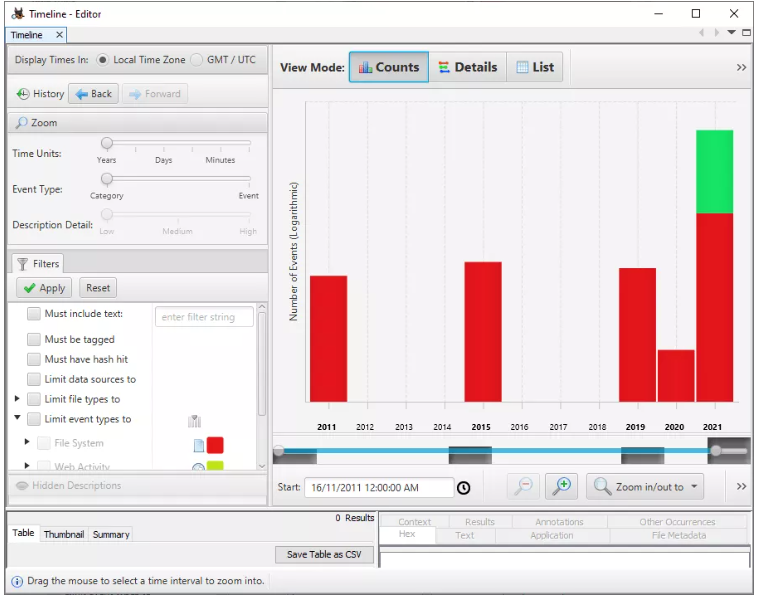
- LÍNEA DE TIEMPO (TIMELINE): mediante esta función puedes obtener información sobre el uso del sistema en forma de estadística (statistical), detallado (detailed) o lista (list). Para nosotros esta es la función más importante.
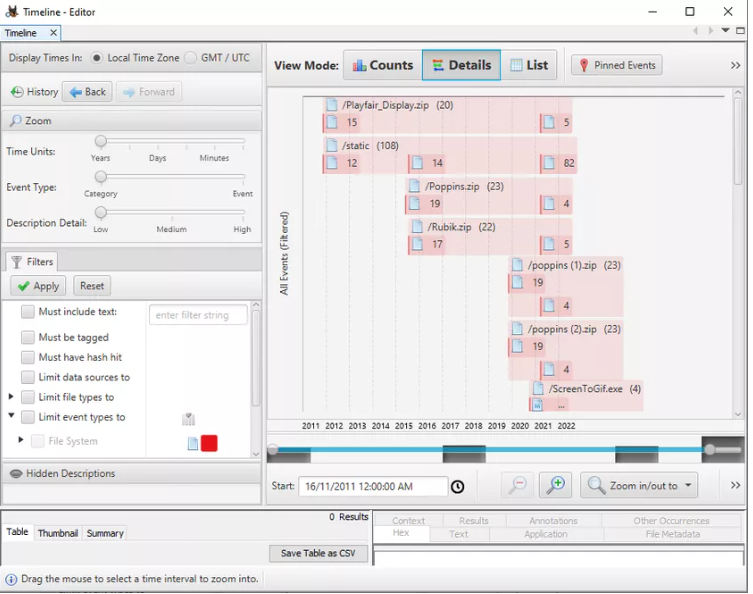
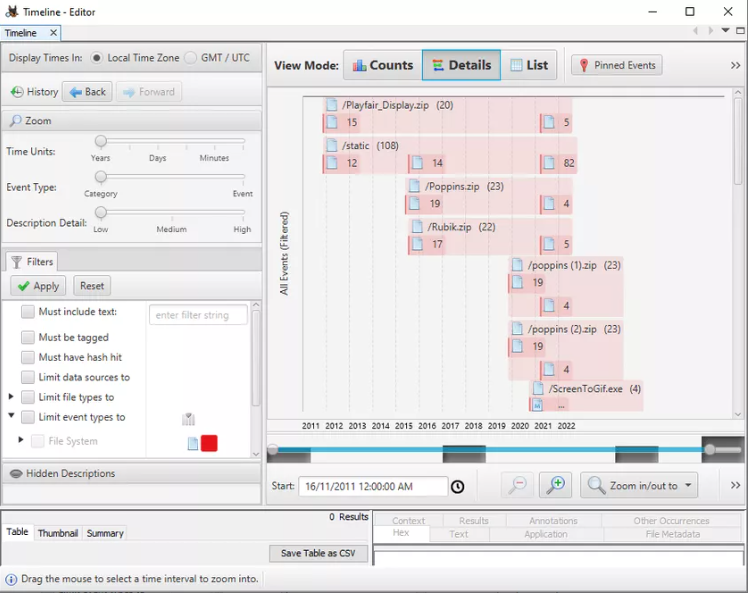
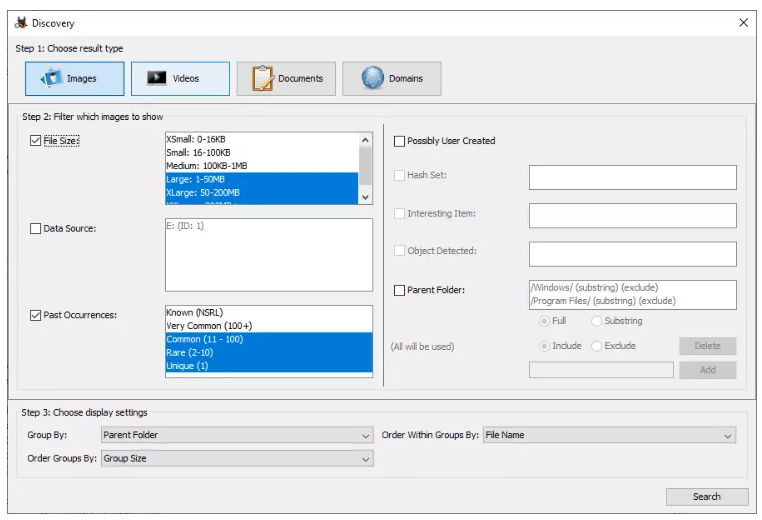
- DESCUBRIMIENTO (DISCOVERY): esta opción permite encontrar medios utilizando diferentes filtros que están presentes en la imagen de disco.
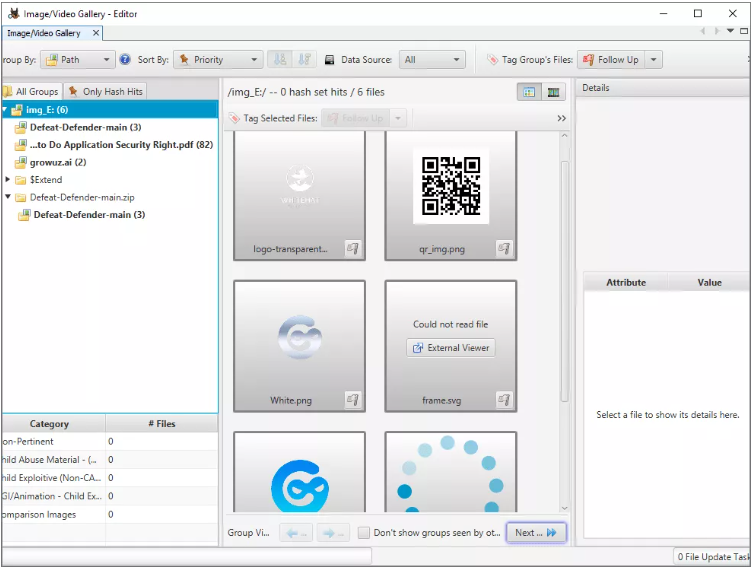
- IMÁGENES/VÍDEOS: esta opción permite encontrar imágenes y vídeos a través de varias opciones y múltiples categorías.
- AÑADIR ETIQUETA DE ARCHIVO: el etiquetado se puede utilizar para crear marcadores, seguimiento, marcar como cualquier elemento notable, etc.
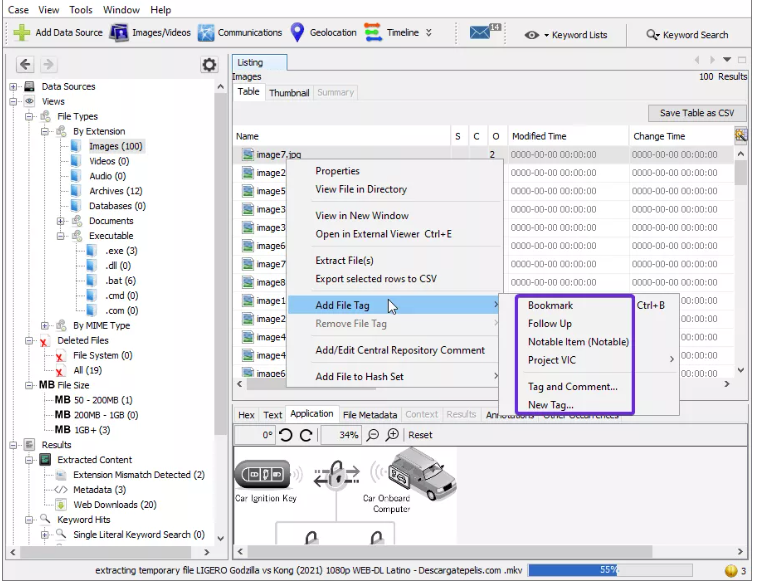
Ahora cuando veas las opciones de etiquetas, verás que los archivos fueron etiquetados de acuerdo a varias categorías.
- GENERAR INFORME: una vez terminada la investigación, el examinador puede generar el informe en varios formatos según su preferencia.
Conclusión
Autopsy es una herramienta de código abierto que se utiliza para realizar operaciones forenses en la imagen de disco de las evidencias. Aquí se muestra la investigación forense que se realiza sobre la imagen de disco. Los resultados obtenidos aquí son de ayuda para investigar y localizar información relevante. Esta herramienta es utilizada por las fuerzas del orden, la policía local y también se puede utilizar en las empresas para investigar las pruebas encontradas en un delito informático. También se puede utilizar para recuperar información que ha sido borrada como veremos en el próximo laboratorio.
Si no tienes una imagen, puedes utilizar tu propio disco duro, no le pasará nada. Practica y prepárate para la próximo laboratorio donde veremos un caso de pérdida de información.
| Módulo Ingest | Descripción |
| Recent Activity | Se utiliza para descubrir las operaciones recientes que se realizaron en el disco, como los archivos que se vieron recientemente. |
| Hash Lookup | Se utiliza para identificar un archivo concreto mediante su valor hash. |
| File Type Identification | Se utiliza para identificar los archivos basándose en sus firmas internas y no sólo en las extensiones de los archivos. |
| Extension Mismatch Detector | Se utiliza para identificar los archivos cuyas extensiones han sido manipuladas o han sido modificadas para ocultar las pruebas. |
| Embedded File Extractor | Se utiliza para extraer archivos incrustados como .zip, .rar, etc. y utilizar esos archivos para su análisis. |
| Keyword Search | Se utiliza para buscar una palabra clave concreta o un patrón en el archivo de imagen. |
| Email Parser | Se utiliza para extraer información de los archivos de correo electrónico si el disco contiene alguna información de la base de datos de correo electrónico. |
| Encryption Detection | Esto ayuda a detectar e identificar los archivos encriptados protegidos por contraseña. |
| Interesting File Identifier | Mediante esta función, el examinador recibe una notificación cuando los resultados corresponden al conjunto de reglas definidas para identificar un tipo de archivo concreto. |
| Central Repository | Guarda las propiedades en el repositorio central para su posterior correlación. |
| PhotoRec Carver | Esto ayuda al examinador a recuperar archivos, fotos, etc. del espacio no asignado en el disco de imagen. |
| Virtual Machine Extractor | Ayuda a extraer y analizar si se encuentra alguna máquina virtual en la imagen de disco. |
| Data Source Integrity | Ayuda a calcular el valor hash y a almacenarlo en la base de datos. |