
Reversing
Citando wikipedia: “La ingeniería inversa es el proceso llevado a cabo con el objetivo de obtener información o un diseño a partir de un producto, con el fin de determinar cuáles son sus componentes y de qué manera interactúan entre sí y cuál fue el proceso de fabricación.”
¿Qué utilidades tiene el reversing?
Si bien uno de los usos más conocidos es la detección de vulnerabilidades y el análisis de malware en el ámbito de la seguridad informática, también existen otros motivos del uso del reversing.
- Las más comunes son las siguientes:
- Descifrar algoritmos criptográficos
- Agregar funcionalidades
- Análisis de malware
- Testing del software
- Detección de vulnerabilidades
¿Por dónde empezar?
Es importante conocer los fundamentos y para ello hay que remontarse a la base. Si bien podemos empezar por técnicas de forma directa y aplicar ciertas “metodologías” a la hora de realizar reversing, es necesario tener una buena base, ya que sin la misma nos costará mucho avanzar y pensar de forma creativa a la hora de intentar resolver las problemáticas que nos puedan aparecer cuando aplicamos ingeniería inversa.
Existe mucha información al respecto relativa al reversing, por lo que aquí nos enfocaremos en explicar toda esta información de forma resumida y comprensible para todo el mundo. Se hablará desde compiladores, estructuras de los propios ejecutables, programación a bajo nivel (ASM, C, etc), arquitecturas de hardware entre otras.
En 1954 se empezó a desarrollar un lenguaje que permitía escribir fórmulas matemáticas de manera traducible por un ordenador; lo llamaron FORTRAN (FORmulae TRANslator). Fue el primer lenguaje de alto nivel y se introdujo en 1957 para el uso de la computadora IBM modelo 704.
Surgió así por primera vez el concepto de un traductor como un programa que traducía un lenguaje a otro lenguaje. En el caso particular de que el lenguaje que se ha de traducir es de alto nivel y el lenguaje traducido, de bajo nivel, se emplea el término compilador. La tarea de hacer un compilador no fue fácil. El primer compilador de FORTRAN tardó 18 años en desarrollarse. Esto deja de manifiesto la cantidad de investigación que se necesitó realizar para poder llegar a un producto final, un compilador completo, por sencillo que fuera su lenguaje. Toda esta investigación aportó la gran parte de teoría, técnicas y herramientas utilizadas hoy en día en los campos de lenguajes y autómatas. Los compiladores permiten escribir código fuente en lenguajes de alto nivel, es decir, en lenguajes no dependientes de la arquitectura del ordenador en el que se ejecute, así como que el lenguaje sea fácilmente interpretable por un ser humano, lejos de ser una lista de comandos secuenciales, como venía siendo el lenguaje ensamblador u otros lenguajes de bajo nivel.
Los lenguajes de alto nivel han permitido un desarrollo exponencial de software que se adapta a las necesidades de los usuarios y funcionan sin prácticamente cambios en diferentes arquitecturas y tipos de ordenadores. Esta ventaja, junto con otras, como la reutilización de código y disciplinas como la ingeniería de software, nos han llevado a los complejos programas informáticos con entornos visuales de escritorio, así como efectos gráficos y videojuegos en 3D en tiempo real, el desarrollo de complejos sistemas de comunicaciones que llevaron a la creación y utilización en masa de Internet o la capacidad de llevar a cabo software con finalidades matemáticas, médicas o de otros sectores y que nos permiten realizar grandes obras de ingeniería, bioingeniería, química o análisis y diagnósticos médicos, así como muchas otras utilidades del software.
Programa fuente
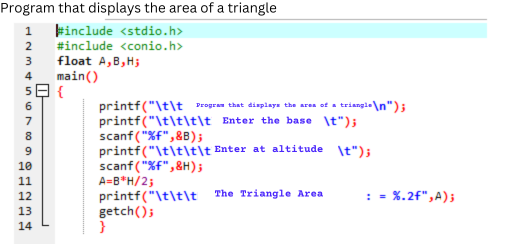
Este código escrito en un lenguaje de alto nivel, en concreto, C++, calcula el área de un triángulo de forma muy sencilla, solicita una serie de argumentos introducido por el usuario por línea de comandos y luego muestra un mensaje con el resultado, o salir con un mensaje de error si no hubiera argumento.
Como se puede observar en la figura, este código de alto nivel permite no solo la utilización de variables con nombre a la libre elección del programador, sino el empleo de comentarios sobre el código, así como la indentación del texto. Estas características facilitan la lectura a las personas, aunque no tenga ninguna trascendencia respecto al código máquina que se ha de generar.
También se puede observar la utilización de estructuras de código, como pueden ser las funciones, que ayudan a la reutilización de código y a su abstracción, pudiendo construir código centrándose en lo particular, para ir resolviendo problemas más generales, además de poder realizar invocaciones recursivas sin necesidad de llevar el control de manera explícita.
Estas facilidades y la proximidad del código fuente al lenguaje natural permiten al desarrollador centrarse en “el qué” debe hacer el software en lugar de en “el cómo” debe implementarlo para que funcione en una máquina con una arquitectura u ordenador en concreto.
Programa objeto / Código ensamblador
Una vez que el compilador ha desarrollado todas las etapas y conseguido generar un código objeto correcto y operativo, se convierte en un código objeto, por lo general, código ensamblador. El lenguaje ensamblador es la representación más cercana al código máquina. La siguiente captura muestra el código ensamblador, que compone el programa objeto, de un programa similar al visto anteriormente del cálculo de un área.
Mnemónico
En informática, un mnemónico o nemónico es una palabra que sustituye a un código de operación (lenguaje de máquina), con lo cual resulta más fácil la programación, es de aquí de donde se aplica el concepto de lenguaje ensamblador.
Un ejemplo común de mnemónico es la instrucción MOV (mover), que le indica al microprocesador que debe asignar datos de un lugar a otro. El microprocesador no entiende palabras, sino números binarios, por lo que es necesaria la traducción del término mnemónico a código objeto.
En muchas ocasiones se puede tomar a nivel de usuario como las teclas de acceso rápido que vemos en las ventanas, por ejemplo en un navegador encontramos el menú típico que dice Archivo, Editar, Ver, entre otras opciones, el mnemónico sería el valor de la letra que esta subrayada, así si presionamos la tecla alt y luego por ejemplo la A, se nos abrirá el menú de archivo, es por esta razón que se puede decir que la A en el menú resulta la tecla mnemónica de Archivo, o la tecla de acceso rápido a la opción Archivo.
El lenguaje Mnemónico también es utilizado en la programación de controladores lógicos programables (PLC), haciendo más rápida y eficiente la construcción de programas de alta complejidad.
Instrucción
Como se puede apreciar, existen varias diferencias en cuanto a los mnemónicos y operandos, tal y como se puede ver en la siguiente instrucción expresada en ambas sintaxis:
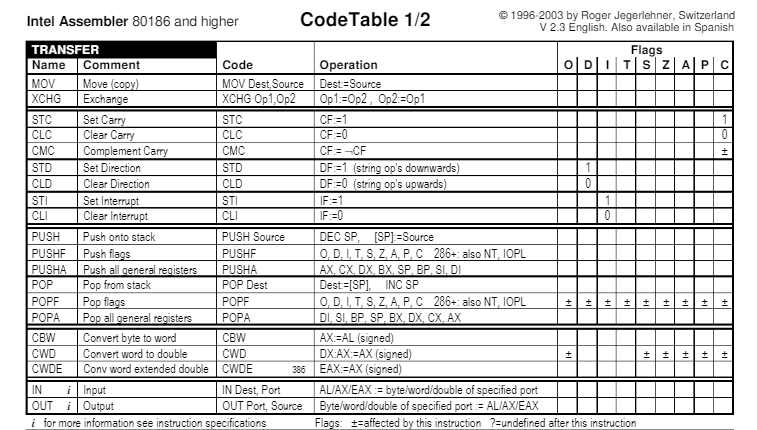
Hay varios tipos de instrucciones, en este caso dejamos la tabla de esamblador de Intel para procesadores 80186 o superiores. Pero también lo hay para procesadores AT&T, entre otros.
Etiquetas
Además de las instrucciones, se puede observar cómo hay etiquetas dentro del código a modo de localizaciones, que se utilizan para las bifurcaciones de código necesario:
Estas etiquetas son traducidas por direcciones de memoria relativas en la fase de construcción del binario final.
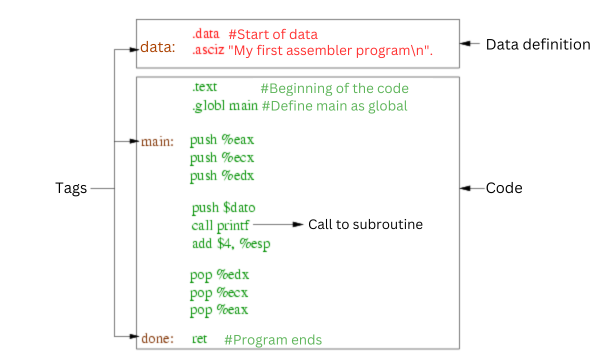
Como se puede apreciar en esta captura, podemos ver claramente no solo las etiquetas sino la estructura de un lenguaje ensamblador.
Un programa consta de varias partes diferenciadas. La palabra .data es una directiva y comunica al ensamblador que a continuación se define un conjunto de datos. El programa tan sólo tiene un único dato que se representa como una secuencia de caracteres. La línea .asciz, también una directiva, seguida del string entre comillas es la que instruye al ensamblador para crear una zona de memoria con datos, y almacenar en ella el string que se muestra terminado por un byte con valor cero. Nótese que el efecto de la directiva .asciz no se traduce en código sino que son órdenes para que el ensamblador haga una tarea, en este caso almacenar un string en memoria.
Antes de la directiva .asciz se incluye la palabra dato seguida por dos puntos. Esta es la forma de definir una etiqueta que luego se utilizará en el código para acceder a estos datos.
La línea siguiente contiene la directiva .text que denota el comienzo de la sección de código. Nótese que todas las directivas tienen como primer carácter un punto. La línea con la directiva .globl main comunica al ensamblador que la etiqueta con nombre main será globalmente accesible desde otro programa.
A continuación, se encuentran las instrucciones en ensamblador propiamente dichas. Se pueden ver las instrucciones push parar almacenar un operando en una zona específica de memoria que se denomina la pila.
Al comienzo del código se define la etiqueta main. Esta etiqueta identifica la posición en por la que el procesador va a empezar a ejecutar. Hacia el final del código se puede ver una segunda etiqueta con nombre done.
Una vez creado el fichero de texto con el editor y guardado con el contenido de la figura superior y con nombre miprograma.s, se ejecuta el compilador. Para ello primero es preciso arrancar una ventana con el intérprete de comandos y estando situados en el mismo directorio en el que se encuentra el fichero miprograma.s ejecutar el comando:
gcc -o miprograma miprograma.s
También tienes un emulador en javascript en esta web assembler-simulator donde poder probar código.
Una vez que el código objeto ha sido generado, entran en juego otras herramientas fuera del alcance del compilador, como son el ensamblador y el enlazador de códigos objeto. El ensamblador genera código binario partiendo del programa en lenguaje ensamblador. Es decir, traduce los mnemónicos en los códigos binarios correspondientes. Por otro lado, el enlazador de códigos objeto se encarga de obtener los códigos objeto requeridos por el código objeto en cuestión de las librerías disponibles. Una vez que tiene todas las piezas necesarias, genera un fichero final ejecutable o en forma de librería del sistema.
Conceptos básicos sobre reconstrucción de código
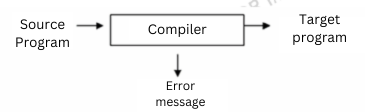
En el tema anterior profundizamos en el proceso de compilación, que convierte el código fuente, escrito en un lenguaje estructurado de alto nivel y fácilmente comprensible por una persona, en código objeto escrito en lenguaje máquina, para la arquitectura escogida y directamente ejecutable.
Ahora conocemos los conceptos básicos sobre diseño, análisis e implementación de lenguajes, así como los detalles sobre las fases por las que pasa un compilador, las técnicas utilizadas para generar y optimizar el código objeto y, en definitiva, todo lo relacionado con el proceso de compilación que genera código objeto partiendo de código fuente.
Ya sabemos cómo el compilador convierte el código fuente a código intermedio, utilizando este finalmente para traducirlo a código máquina de manera directa, tal como se puede apreciar en la siguiente imagen.

Proceso inverso
Tal como hemos visto antes, si podemos realizarlo en un sentido, también podríamos de alguna forma hacer el proceso inverso, pudiendo generar código fuente a partir del código objeto en lenguaje máquina.
Esta labor sí es posible en gran medida, aunque se deben tener en cuenta algunas las limitaciones. En este tema, vamos a referirnos como “Reconstrucción de código” al proceso inverso al que hemos estado estudiando en el tema anterior. Es decir, al proceso de obtener el código fuente a partir del código objeto. Debido a las limitaciones mencionadas, no será posible obtener comentarios, ni nombre de variables, tal y como las describió el desarrollador, puede que ni tan siquiera con el tipo ni el tamaño exacto con el que este lo hizo.
No obstante, sí se va a poder obtener una estructura de código que cumple con bastante exactitud con el comportamiento del programa fuente. Para ello, es necesario conocer las estructuras que el compilador maneja, y con las que traduce el código fuente a código objeto. De esta forma, podremos identificar estas estructuras en el código objeto y ser traducidas a código fuente. Esta traducción depende de:
- Arquitectura (INTEL, ARM, x86,etc)
- Optimizaciones que pueda sufrir el código
Resumiendo
Si bien ya hemos visto lo fundamental para comprender el mundo de los compiladores, lo que nos resultaba útil para comprender como se construyen los binarios que queremos analizar; ahora es el momento de empezar a comprender las estructuras de datos que nos podemos encontrar a la hora de reconstruir el código fuente partiendo del desemsamblado.
Haciendo un poco de memoria respecto a las fases de compilación, podemos observar en las últimas fases de “Generación de código intermedio”, “Optimización” y “Generación de código” que la idea de reconstrucción del código sería volver al proceso del “código intermedio”.
Debemos tener claro que existen limitaciones cuando volvemos del código final al código intermedio, como la perdida de comentarios del programador, nombres reales de las variables, tipo de variables, el tamaño, etc.
Para poder identificar todas estas estructuras de datos y comprender el código, trataremos aquí como identificarlas manualmente, dependiendo de la arquitectura del código (x86, x86_64, arm, …) y las optimizaciones aplicadas por el compilador.
Cuando tengamos identificadas las estructuras de datos, podremos darles nombres a las mismas mediante nuestro software de ingeniería inversa (radare2, IDA, papel y lápiz? ) para así poder reversear sin volvernos locos y dejar invertir más esfuerzo mental en algo que no merece la pena por no apuntarlo o nombrar las cosas, pudiendo dejar ese esfuerzo en pensar las estructuras mentalmente y al vuelo, en tratar otras cosas más relevantes del reversing, como la lógica de programación del propio código a analizar.
Las estructuras de datos que vamos a analizar serán las típicas del lenguaje de programación C.
versing?
Citando wikipedia: “La ingeniería inversa es el proceso llevado a cabo con el objetivo de obtener información o un diseño a partir de un producto, con el fin de determinar cuáles son sus componentes y de qué manera interactúan entre sí y cuál fue el proceso de fabricación.”
¿Qué utilidades tiene el reversing?
Si bien uno de los usos más conocidos es la detección de vulnerabilidades y el análisis de malware en el ámbito de la seguridad informática, también existen otros motivos del uso del reversing.
- Las más comunes son las siguientes:
- Descifrar algoritmos criptográficos
- Agregar funcionalidades
- Análisis de malware
- Testing del software
- Detección de vulnerabilidades
¿Por dónde empezar?
Es importante conocer los fundamentos y para ello hay remontarse a la base. Si bien podemos empezar por técnicas de forma directa y aplicar ciertas “metodologías” a la hora de realizar reversing, es necesario tener una buena base, ya que sin la misma nos costará mucho avanzar y pensar de forma creativa a la hora de intentar resolver las problemáticas que nos puedan aparecer cuando aplicamos ingeniería inversa.
Existe mucha información al respecto relativa al reversing, por lo que aquí nos enfocaremos en explicar toda esta información de forma resumida y comprensible para todo el mundo. Se hablará desde compiladores, estructuras de los propios ejecutables, programación a bajo nivel (ASM, C, etc), arquitecturas de hardware entre otras.
En 1954 se empezó a desarrollar un lenguaje que permitía escribir fórmulas matemáticas de manera traducible por un ordenador; lo llamaron FORTRAN (FORmulae TRANslator). Fue el primer lenguaje de alto nivel y se introdujo en 1957 para el uso de la computadora IBM modelo 704.
Surgió así por primera vez el concepto de un traductor como un programa que traducía un lenguaje a otro lenguaje. En el caso particular de que el lenguaje que se ha de traducir es de alto nivel y el lenguaje traducido, de bajo nivel, se emplea el término compilador. La tarea de hacer un compilador no fue fácil. El primer compilador de FORTRAN tardó 18 años en desarrollarse. Esto deja de manifiesto la cantidad de investigación que se necesitó realizar para poder llegar a un producto final, un compilador completo, por sencillo que fuera su lenguaje. Toda esta investigación aportó la gran parte de teoría, técnicas y herramientas utilizadas hoy en día en los campos de lenguajes y autómatas. Los compiladores permiten escribir código fuente en lenguajes de alto nivel, es decir, en lenguajes no dependientes de la arquitectura del ordenador en el que se ejecute, así como que el lenguaje sea fácilmente interpretable por un ser humano, lejos de ser una lista de comandos secuenciales, como venía siendo el lenguaje ensamblador u otros lenguajes de bajo nivel.
Los lenguajes de alto nivel han permitido un desarrollo exponencial de software que se adapta a las necesidades de los usuarios y funcionan sin prácticamente cambios en diferentes arquitecturas y tipos de ordenadores. Esta ventaja, junto con otras, como la reutilización de código y disciplinas como la ingeniería de software, nos han llevado a los complejos programas informáticos con entornos visuales de escritorio, así como efectos gráficos y videojuegos en 3D en tiempo real, el desarrollo de complejos sistemas de comunicaciones que llevaron a la creación y utilización en masa de Internet o la capacidad de llevar a cabo software con finalidades matemáticas, médicas o de otros sectores y que nos permiten realizar grandes obras de ingeniería, bioingeniería, química o análisis y diagnósticos médicos, así como muchas otras utilidades del software.
Programa fuente
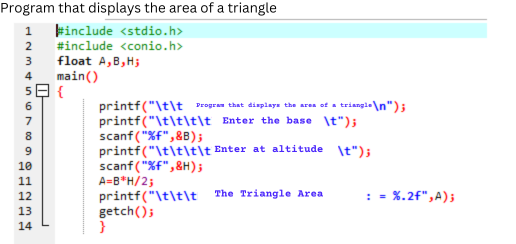
Este código escrito en un lenguaje de alto nivel, en concreto, C++, calcula el área de un triángulo de forma muy sencilla, solicita una serie de argumentos introducido por el usuario por línea de comandos y luego muestra un mensaje con el resultado, o salir con un mensaje de error si no hubiera argumento.
Como se puede observar en la figura, este código de alto nivel permite no solo la utilización de variables con nombre a la libre elección del programador, sino el empleo de comentarios sobre el código, así como la indentación del texto. Estas características facilitan la lectura a las personas, aunque no tenga ninguna trascendencia respecto al código máquina que se ha de generar.
También se puede observar la utilización de estructuras de código, como pueden ser las funciones, que ayudan a la reutilización de código y a su abstracción, pudiendo construir código centrándose en lo particular, para ir resolviendo problemas más generales, además de poder realizar invocaciones recursivas sin necesidad de llevar el control de manera explícita.
Estas facilidades y la proximidad del código fuente al lenguaje natural permiten al desarrollador centrarse en “el qué” debe hacer el software en lugar de en “el cómo” debe implementarlo para que funcione en una máquina con una arquitectura u ordenador en concreto.
Programa objeto / Código ensamblador
Una vez que el compilador ha desarrollado todas las etapas y conseguido generar un código objeto correcto y operativo, se convierte en un código objeto, por lo general, código ensamblador. El lenguaje ensamblador es la representación más cercana al código máquina. La siguiente captura muestra el código ensamblador, que compone el programa objeto, de un programa similar al visto anteriormente del cálculo de un área.
Mnemónico
En informática, un mnemónico o nemónico es una palabra que sustituye a un código de operación (lenguaje de máquina), con lo cual resulta más fácil la programación, es de aquí de donde se aplica el concepto de lenguaje ensamblador.
Un ejemplo común de mnemónico es la instrucción MOV (mover), que le indica al microprocesador que debe asignar datos de un lugar a otro. El microprocesador no entiende palabras, sino números binarios, por lo que es necesaria la traducción del término mnemónico a código objeto.
En muchas ocasiones se puede tomar a nivel de usuario como las teclas de acceso rápido que vemos en las ventanas, por ejemplo en un navegador encontramos el menú típico que dice Archivo, Editar, Ver, entre otras opciones, el mnemónico sería el valor de la letra que esta subrayada, así si presionamos la tecla alt y luego por ejemplo la A, se nos abrirá el menú de archivo, es por esta razón que se puede decir que la A en el menú resulta la tecla mnemónica de Archivo, o la tecla de acceso rápido a la opción Archivo.
El lenguaje Mnemónico también es utilizado en la programación de controladores lógicos programables (PLC), haciendo más rápida y eficiente la construcción de programas de alta complejidad.
Instrucción
Como se puede apreciar, existen varias diferencias en cuanto a los mnemónicos y operandos, tal y como se puede ver en la siguiente instrucción expresada en ambas sintaxis:
Hay varios tipos de instrucciones, en este caso dejamos la tabla de esamblador de Intel para procesadores 80186 o superiores. Pero también lo hay para procesadores AT&T, entre otros.
Etiquetas
Además de las instrucciones, se puede observar cómo hay etiquetas dentro del código a modo de localizaciones, que se utilizan para las bifurcaciones de código necesario:
Estas etiquetas son traducidas por direcciones de memoria relativas en la fase de construcción del binario final.
Como se puede apreciar en esta captura, podemos ver claramente no solo las etiquetas sino la estructura de un lenguaje ensamblador.
Un programa consta de varias partes diferenciadas. La palabra .data es una directiva y comunica al ensamblador que a continuación se define un conjunto de datos. El programa tan sólo tiene un único dato que se representa como una secuencia de caracteres. La línea .asciz, también una directiva, seguida del string entre comillas es la que instruye al ensamblador para crear una zona de memoria con datos, y almacenar en ella el string que se muestra terminado por un byte con valor cero. Nótese que el efecto de la directiva .asciz no se traduce en código sino que son órdenes para que el ensamblador haga una tarea, en este caso almacenar un string en memoria.
Antes de la directiva .asciz se incluye la palabra dato seguida por dos puntos. Esta es la forma de definir una etiqueta que luego se utilizará en el código para acceder a estos datos.
La línea siguiente contiene la directiva .text que denota el comienzo de la sección de código. Nótese que todas las directivas tienen como primer carácter un punto. La línea con la directiva .globl main comunica al ensamblador que la etiqueta con nombre main será globalmente accesible desde otro programa.
A continuación, se encuentran las instrucciones en ensamblador propiamente dichas. Se pueden ver las instrucciones push parar almacenar un operando en una zona específica de memoria que se denomina la pila.
Al comienzo del código se define la etiqueta main. Esta etiqueta identifica la posición en por la que el procesador va a empezar a ejecutar. Hacia el final del código se puede ver una segunda etiqueta con nombre done.
Una vez creado el fichero de texto con el editor y guardado con el contenido de la figura superior y con nombre miprograma.s, se ejecuta el compilador. Para ello primero es preciso arrancar una ventana con el intérprete de comandos y estando situados en el mismo directorio en el que se encuentra el fichero miprograma.s ejecutar el comando:
gcc -o miprograma miprograma.s
También tienes un emulador en javascript en esta web assembler-simulator donde poder probar código.
Programa binario ejecutable
Una vez que el código objeto ha sido generado, entran en juego otras herramientas fuera del alcance del compilador, como son el ensamblador y el enlazador de códigos objeto. El ensamblador genera código binario partiendo del programa en lenguaje ensamblador. Es decir, traduce los mnemónicos en los códigos binarios correspondientes. Por otro lado, el enlazador de códigos objeto se encarga de obtener los códigos objeto requeridos por el código objeto en cuestión de las librerías disponibles. Una vez que tiene todas las piezas necesarias, genera un fichero final ejecutable o en forma de librería del sistema.
Conceptos básicos sobre reconstrucción de código En el tema anterior profundizamos en el proceso de compilación, que convierte el código fuente, escrito en un lenguaje estructurado de alto nivel y fácilmente comprensible por una persona, en código objeto escrito en lenguaje máquina, para la arquitectura escogida y directamente ejecutable.
Ahora conocemos los conceptos básicos sobre diseño, análisis e implementación de lenguajes, así como los detalles sobre las fases por las que pasa un compilador, las técnicas utilizadas para generar y optimizar el código objeto y, en definitiva, todo lo relacionado con el proceso de compilación que genera código objeto partiendo de código fuente.
Ya sabemos cómo el compilador convierte el código fuente a código intermedio, utilizando este finalmente para traducirlo a código máquina de manera directa, tal como se puede apreciar en la siguiente imagen.
Proceso inverso
Tal como hemos visto antes, si podemos realizarlo en un sentido, también podríamos de alguna forma hacer el proceso inverso, pudiendo generar código fuente a partir del código objeto en lenguaje máquina.
Esta labor sí es posible en gran medida, aunque se deben tener en cuenta algunas las limitaciones. En este tema, vamos a referirnos como “Reconstrucción de código” al proceso inverso al que hemos estado estudiando en el tema anterior. Es decir, al proceso de obtener el código fuente a partir del código objeto. Debido a las limitaciones mencionadas, no será posible obtener comentarios, ni nombre de variables, tal y como las describió el desarrollador, puede que ni tan siquiera con el tipo ni el tamaño exacto con el que este lo hizo.
No obstante, sí se va a poder obtener una estructura de código que cumple con bastante exactitud con el comportamiento del programa fuente. Para ello, es necesario conocer las estructuras que el compilador maneja, y con las que traduce el código fuente a código objeto. De esta forma, podremos identificar estas estructuras en el código objeto y ser traducidas a código fuente. Esta traducción depende de:
- Arquitectura (INTEL, ARM, x86,etc)
- Optimizciones que pueda sufrir el código
Resumiendo
Si bien ya hemos visto lo fundamental para comprender el mundo de los compiladores, lo que nos resultaba útil para comprender como se construyen los binarios que queremos analizar; ahora es el momento de empezar a comprender las estructuras de datos que nos podemos encontrar a la hora de reconstruir el código fuente partiendo del desemsamblado.
Haciendo un poco de memoria respecto a las fases de compilación, podemos observar en las últimas fases de “Generación de código intermedio”, “Optimización” y “Generación de código” que la idea de reconstrucción del código sería volver al proceso del “código intermedio”.
Debemos tener claro que existen limitaciones cuando volvemos del código final al código intermedio, como la perdida de comentarios del programador, nombres reales de las variables, tipo de variables, el tamaño, etc.
Para poder identificar todas estas estructuras de datos y comprender el código, trataremos aquí como identificarlas manualmente, dependiendo de la arquitectura del código (x86, x86_64, arm, …) y las optimizaciones aplicadas por el compilador.
Cuando tengamos identificadas las estructuras de datos, podremos darles nombres a las mismas mediante nuestro software de ingeniería inversa (radare2, IDA, papel y lápiz? ) para así poder reversear sin volvermos locos y dejar invertir más esfuerzo mental en algo que no merece la pena por no apuntarlo o nombrar las cosas, pudiendo dejar ese esfuerzo en pensar las estructuras mentalmente y al vuelo, en tratar otras cosas más relevantes del reversing, como la lógica de programación del propio código a analizar.
Las estructuras de datos que vamos a analizar serán las típicas del lenguaje de programación C.
Variables
Como seguro que sabemos, las variables sirgen para almacenar valores de nuestra aplicación y existen varios tipos. Los tipos son clasificados en base a un tamaño (ancho de bits) y unos valores mínimos y máximos (en base al signo) ayudan a definir con más exactitud el valor numérico hasta donde abarcan.
Vamos a tratar los tipos de variables en C en arquitecturas de 32bits, excluyendo floats y double.
Si construimos una aplicación realizada en código c donde sólo realizamos la definición de variables globales y locales, podemos ver un ejemplo de cómo se sitúan en el binario.
Código aplicación “test”
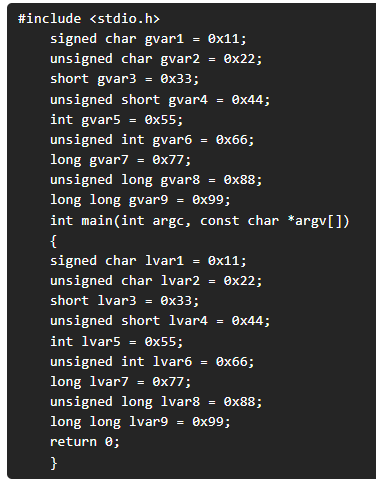
Si compilamos el fichero en 64 bits y analizamos el desemsamblado del mismo en sintaxis Intel nos encontraremos con lo siguiente:
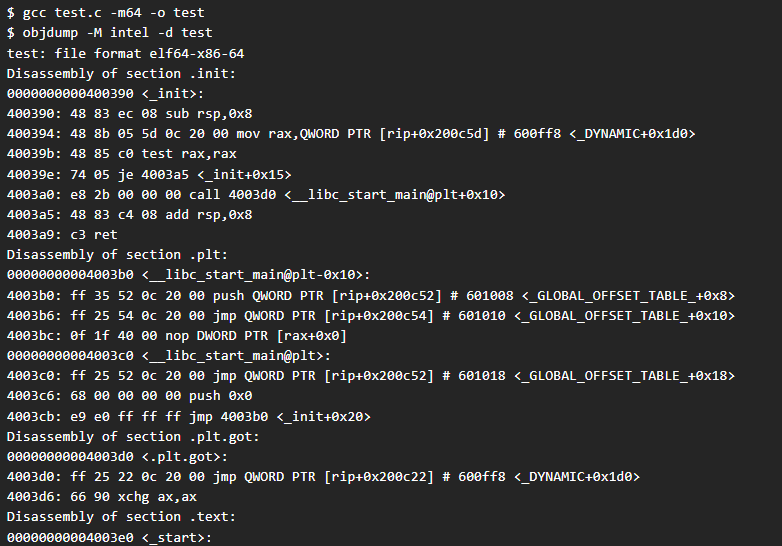
Si analizamos el binario de 64 bits con gdb en la función main se nos mostrará lo siguiente:
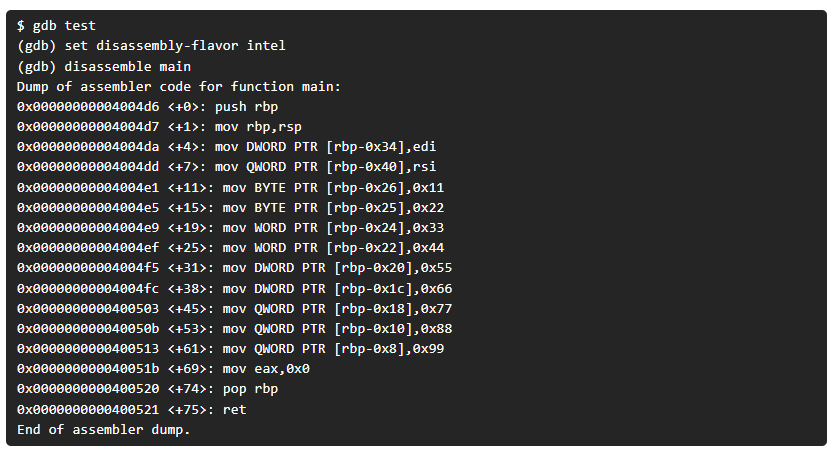
Si lo recompilamos en 32bits (si usas ubuntu/debian probablemente necesites el paquete “libc6-dev-i386”) y tiramos de gdb desde la función main se mostrará lo siguiente:
(gdb) disassemble main
Dump of assembler code for function main:
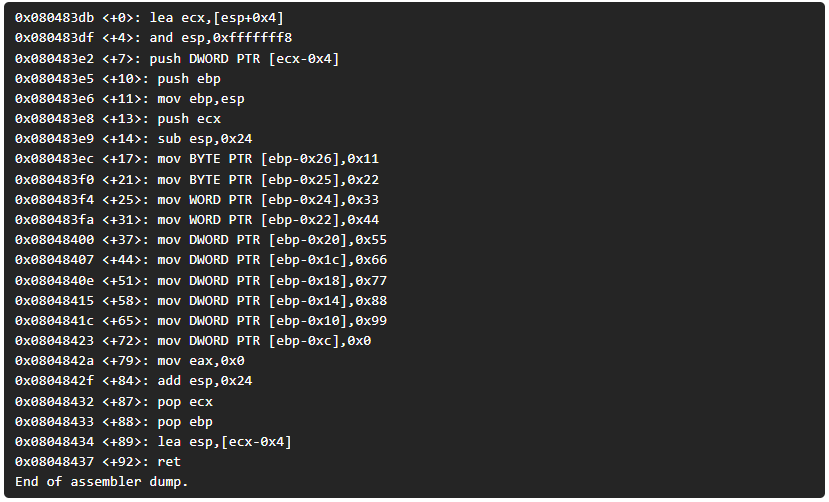
Ahora, si observamos detenidamente sólo hemos mostrado las variables de tipo local, las cuales hemos tenido que encontrar la entrada main mediante la instrucción de gdb “disassemble main”, ¿pero qué hay de las variables de tipo global?
Para ello vamos a decirle a gdb que nos muestre o “examine” el contenido de la memoria en una dirección dada usando el formato especificado. Esa dirección dada será la dirección de memoria de la variable gvar1 mediante el uso del carácter “&” (AND) y que muestre en contenido en hexadecimal agrupado en una longitud de byte, mostrando un total de 32 bytes.
(gdb) set disassembly-flavor intel

Ahora mostraremos estas variables en hexadecimal con una longitud por defecto, normalmente “word” (palabra) y hasta un total de 8, ya que con esto cubriremos el poder mostrar todas las variables globales.
(gdb) x/8wx &gvar1
0x804a018 <gvar1>: 0x00332211 0x00000044 0x00000055 0x00000066
0x804a028 <gvar7>: 0x00000077 0x00000088 0x00000099 0x00000000
Otra forma curiosa de ver y confirmar el tamaño de las variables globales, sería compilando la aplicación sin ensamblado/linkado, donde podemos ver en el apartado “size” el tamaño de las variables.
gcc -m32 -S test.c -o test
Conclusiones
Esta lección habla sobre el tema de la ingeniería inversa o reversing, que consiste en el proceso de obtener información o un diseño a partir de un producto para determinar cuáles son sus componentes y cómo interactúan entre sí. Se menciona que uno de los usos más conocidos del reversing es la detección de vulnerabilidades y el análisis de malware en el ámbito de la seguridad informática, pero también se mencionan otros usos como descifrar algoritmos criptográficos y agregar funcionalidades. Se recomienda empezar el estudio del reversing conociendo los fundamentos y remontándose a la base. También se menciona que en un curso de reversing se hablará de compiladores, estructuras de ejecutables, programación de bajo nivel, arquitecturas de hardware, sistemas operativos y kernel e incluso técnicas de explotación y metodologías.