
Colisiones (hash)
No podemos hablar de función hash, sin colisiones.
Es matemáticamente imposible que una función de hash carezca de colisiones, ya que el número potencial de posibles entradas es mayor que el número de salidas que puede producir un hash. Sin embargo, las colisiones se producen más frecuentemente en los malos algoritmos. En ciertas aplicaciones especializadas con un relativamente pequeño número de entradas que son conocidas de antemano es posible construir una función de hash perfecta, que se asegura que todas las entradas tengan una salida diferente. Pero en una función en la cual se puede introducir datos de longitud arbitraria y que devuelve un hash de tamaño fijo (como MD5), siempre habrá colisiones, debido a que un hash dado puede pertenecer a un infinito número de entradas.
Y ahora que sacamos el tema de las colisiones es bueno preguntarnos: para mantener nuestra famosa cadena de custodia, ¿qué función hash debería utilizar? ¿Cómo de seguro es utilizar una función hash que fue rota? Depende mucho en el ámbito que nos movamos, el MD4, MD5 y SHA-1 son funciones hash rotas, pero en un entorno de una forense es poco probable que se pueda impugnar una prueba por tener una hash débil ya que, por ejemplo, la colisión de SHA-1 se ha demostrado de forma teórica, pero no de forma real. Nuestra recomendación es empezar a utilizar SHA-256, por ejemplo, para despejar cualquier tipo de duda.
No queremos ahondar más en la explicación del mundo teórico de las colisiones en funciones hash porque entendemos que escapar al objetivo, pero sí queríamos incidir un poco más en el concepto de “hash” y su utilización. Evidentemente, si se quiere profundizar más en el mundo de las colisiones dejamos un trabajo de investigación del profesor Kim-Biryukov-Preneel-Hong.
En resumen, los algoritmos hash o funciones de resumen son unos algoritmos de formulación matemática, los cuales, a partir de la consideración de elemento de entrada bien sea una cadena de caracteres, un fichero, una carpeta, una partición o un disco entero, son capaces de proporcionar a modo de “resumen” una salida de caracteres alfanuméricos de longitud fija, constante y estable para cada entrada.
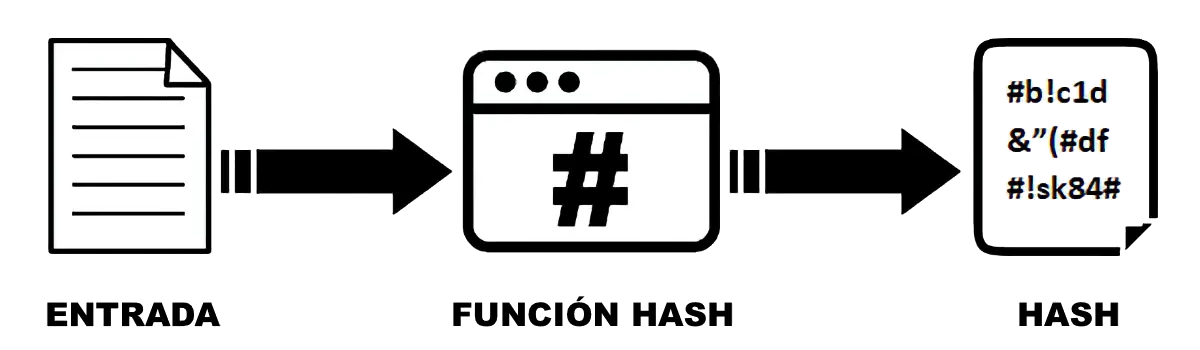
Características principales de los hashes:
- La salida proporcionada es un valor unívoco para una entrada en concreto y, salvo la presencia excepcional de colisiones en algoritmos sencillos, en un mismo algoritmo, no es posible obtener dos salidas diferentes para una misma entrada, ni dos entradas diferentes pueden generar un mismo valor de salida.
- La salida proporcionada es de longitud fija y varía según el algoritmo aplicado, con independencia de la longitud, tamaño o contenido de la entrada.
- El cálculo realizado es un proceso de generación unidireccional e irreversible puesto que tomando una entrada y aplicando el algoritmo se obtiene siempre el mismo valor de salida, pero conociendo el valor la salida no se puede llevar a cabo el proceso inverso y llegar a conocer la entrada utilizada para la generación de dicha salida, salvo en cadenas muy pequeñas (de unos pocos caracteres y sin caracteres especiales), a las cuales se les podría aplicar “métodos de ataque de fuerza bruta“.
- Cada algoritmo hash posee sus propias reglas de cálculo, son estables y universales para todos aquellos programas que utilicen el mismo algoritmo hash de cálculo, no existiendo dos formulaciones de algoritmos diferentes con el mismo nombre, por lo que un algoritmo siempre ofrece el mismo valor de salida para una entrada dada, con total independencia de la herramienta, software o dispositivo utilizado para su cálculo.
Los peritos informáticos forenses nos valemos de las funciones hashes para:
- La verificación de archivos idénticos: Internamente dos ficheros son idénticos aunque cambien de nombre o de extensión incluso si se abren, siempre que no se grabe o acepte cambio alguno no cambie el contenido interno de los mismos, tal como vimos en el caso de mi fotografía que cambiaba el nombre del archive. Por lo tanto, a través del valor del algoritmo hash se puede conocer y corroborar si el contenido de dos ficheros es idéntico. Dada esta propiedad, los algoritmos hash son utilizados en situaciones en las que es necesario o conveniente verificar esta identidad de contenido interno como, por ejemplo, cuando se aporta un fichero en una investigación forense, o cuando alguien se descarga un software o un fichero y se quiere comprobar que es idéntico al que los desarrolladores han liberado en origen, o quizás, para verificar si algún fichero de un sistema operativo o de un aplicativo, por ejemplo, una página web que haya sido modificado por un malware introduciéndole una cadena de código malicioso.
En la identificación y registro de copias forenses: En la realización de clones idénticos (imagen bit a bit) de discos HDD (Hard Drive Disk), es decir, los discos duros convencionales, pudiéndose aplicar el algoritmo a todo el disco, a particiones concretas o a carpetas determinadas o de forma individualizada a grupos de ficheros. Esta es una comprobación muy significativa y relevante puesto que, si no se realizan manipulaciones (borrado, copiado de ficheros o modificación interna de los mismos), la información permanece estable y perenne sin alteración alguna, por lo que el valor del algoritmo hash permanecerá también invariable a lo largo del tiempo.
En este sentido, no se puede hacer la misma afirmación respecto a los discos SSD (Solid State Drive) y se debe tener cuidado con esto, ya que cuando se pretende validar la imagen completa del disco, puesto que el mero hecho de conectarlos hace que la información interna del propio dispositivo varíe puesto que funcionan a modo de memoria flash y no son dispositivos de grabado en soporte físico como los discos tradicionales, consecuentemente, el valor del hash obtenido sobre el contenido global del disco será diferente cada ocasión en la que se calcule y obtenga.
En la investigación forense se utiliza el cálculo de los valores hash a nivel global o extendido en las carpetas sobre sus ficheros para poder comparar el contenido de dispositivos frente a otros dispositivos o las carpetas conteniendo ficheros incautados pero, tal y como se ha comentado, los valores hash de los ficheros examinados sólo serán idénticos si los ficheros comparados no han sido variados internamente, aunque hayan variado de nombre y de extensión, por lo que:
- En sentido positivo, la ventaja de investigar usando los algoritmos hash: Si los ficheros que se copiaron no han sido modificados, el cálculo de los valores hash permite realizar una comparativa rápida, fiable e infalible, no dejando lugar a dudas de si el contenido de los ficheros examinados es el mismo, aunque exista cambio de nombre o de extensión del fichero, siempre y cuando no se abra y grabe. Este proceso se puede automatizar ejecutándose de forma rápida y con una gran economía de esfuerzo, recursos y tiempo.
- En sentido negativo, la desventaja o debilidad de investigar usando los algoritmos hash: La posibilidad de que tras la copia o sustracción de los ficheros, estos hayan sido modificados para su uso o, simplemente, porque se haya añadido, modificado o quitado algo, por nimio que esto sea o represente, hará que se obtenga un valor hash diferente por lo que, bajo esta premisa, la comparativa a través del hash dará como resultado que se trata de ficheros diferentes.
Normalmente, en las investigaciones forenses, los Cuerpos y Fuerzas de Seguridad cuando examinan la similitud del contenido de los dispositivos lo hacen en base a la comparativa de algoritmos hash, que es un método adecuado y razonable en cuanto a esfuerzo requerido en la investigación y, con el resultado de la comparativa de los valores hash de los ficheros contenidos en los dispositivos, se llega a la determinación de si se ha encontrado ficheros idénticos o no, con independencia del nombre que pudieran tener los ficheros.
Ahora que ya conoces la función HASH, verás que no solo se aplica en el mundo forense, sino en criptografía, sino que tiene muchos ámbitos de aplicación. Pero dentro del mundo forense es fundamental para establecer cadenas de custodia de la evidencia digital obtenida.
Conclusiones
La función Hash es una función criptográfica que se traduce como un algoritmo matemático que transforma cualquier bloque arbitrario de datos en una nueva serie de caracteres con una longitud fija. Esto significa que da igual la longitud de los datos de entrada, los datos de salida siempre tendrán la misma longitud. Los valores hash se utilizan para mantener la cadena de custodia en la evidencia de forense digital. En resumen, la función hash es una herramienta importante para garantizar la integridad de los datos y evitar la modificación no autorizada de la información.