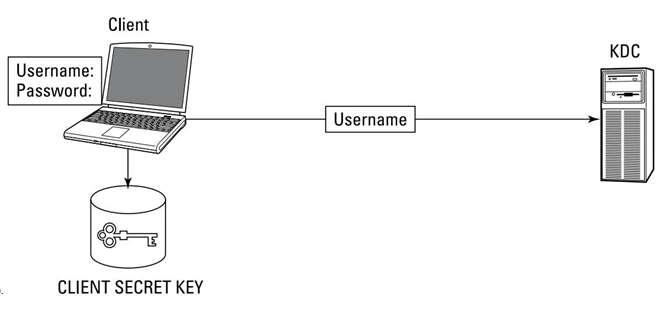
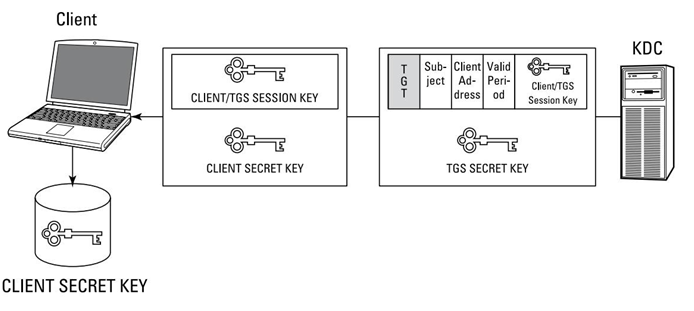
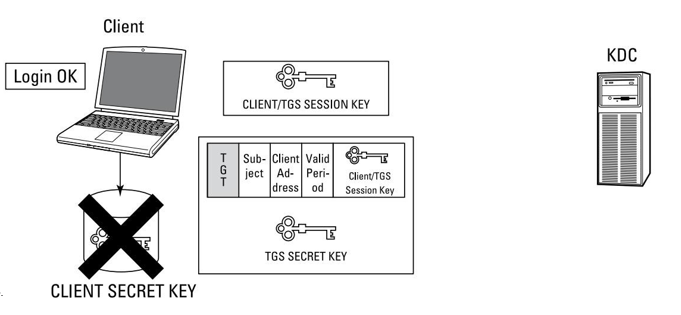
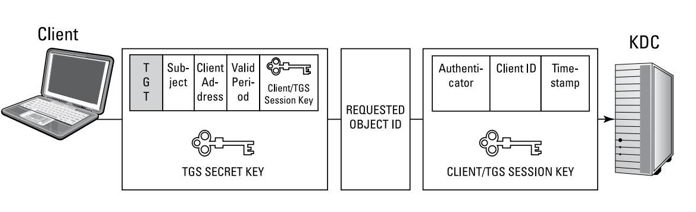
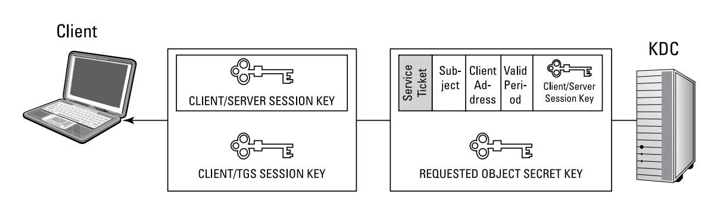
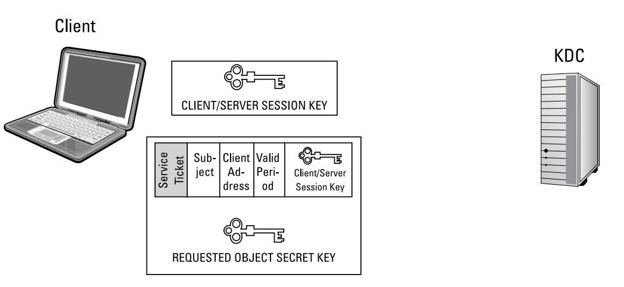
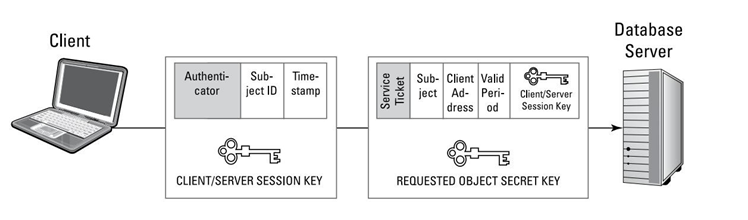
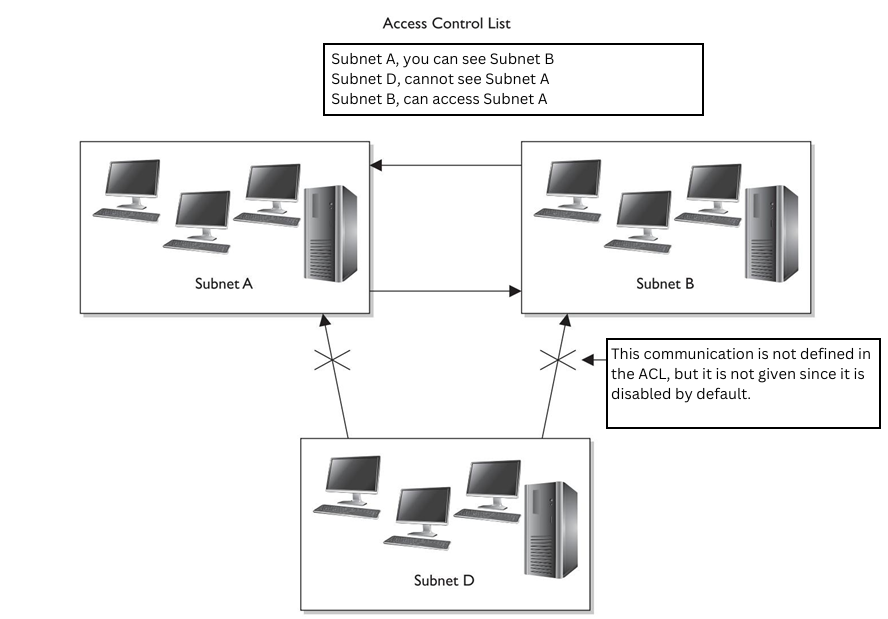
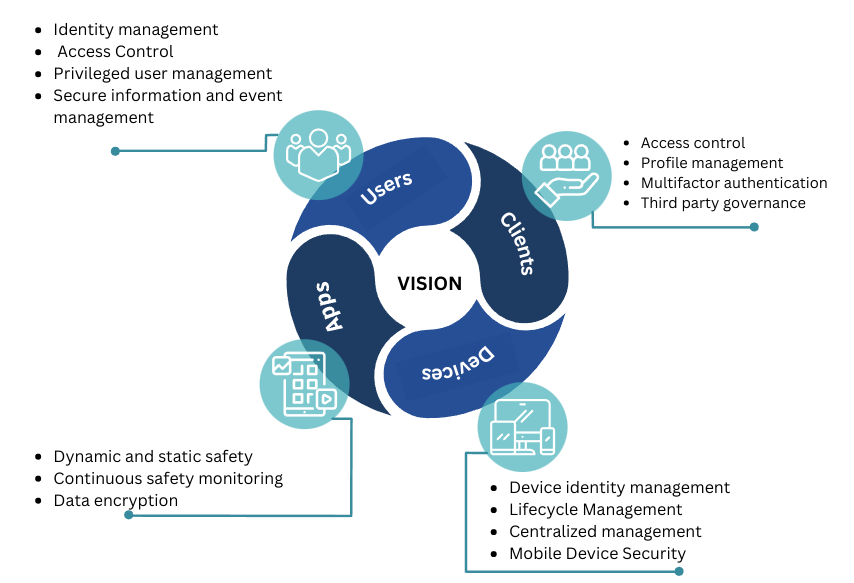
Acceso en la nube
Controles de acceso basados en la nube
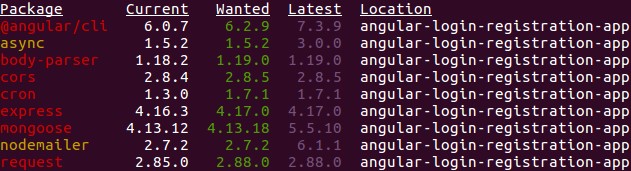
A medida que las organizaciones trasladan su infraestructura y aplicaciones a proveedores de servicios basados en la nube, las organizaciones también optan por emplear la autenticación basada en la nube.
Los protocolos que se utilizan para la gestión de acceso basada en la nube, como SAML, RADIUS y TACACS, todavía se utilizan. La principal diferencia con el acceso basado en la nube es que los servidores de directorio están en la nube, ya sea en la infraestructura basada en la nube de una organización o mediante un servicio de autenticación basado en la nube.
Controles de acceso descentralizados
Los sistemas de control de acceso descentralizados mantienen la información de la cuenta del usuario en ubicaciones separadas, mantenidas por los mismos o diferentes administradores, en toda una organización o empresa. Este tipo de sistema tiene sentido en organizaciones extremadamente grandes o en situaciones donde es necesario un control muy granular de relaciones y derechos de acceso de usuarios complejos. En un sistema de este tipo, los administradores suelen tener un conocimiento más profundo de las necesidades de sus usuarios y pueden aplicar los permisos apropiados, por ejemplo, en un laboratorio de investigación y desarrollo o en una planta de fabricación industrial. Sin embargo, los sistemas de control de acceso descentralizados también tienen varias desventajas potenciales.
Por ejemplo, las organizaciones pueden aplicar políticas de seguridad de manera inconsistente en varios sistemas, lo que resulta en un nivel de acceso incorrecto (demasiado o insuficiente) para usuarios particulares; y si necesita deshabilitar numerosas cuentas para un usuario individual, el proceso se vuelve mucho más laborioso y propenso a errores.
Autenticación de factor único/multifactor
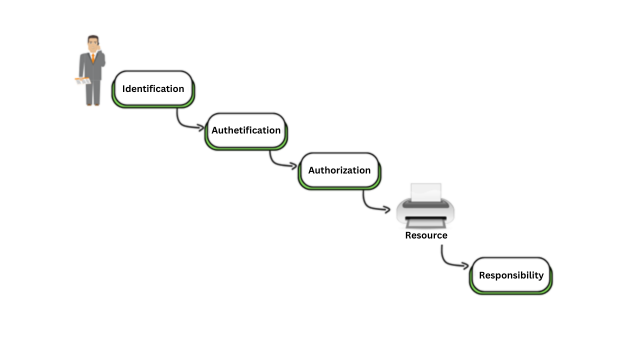
La autenticación es un proceso de dos pasos que consta de identificación y autenticación (I&A). La identificación es el medio por el cual un usuario o sistema (sujeto) presenta una identidad específica (como un nombre de usuario) a un sistema (objeto). La autenticación es el proceso de verificar esa identidad. Por ejemplo, una combinación de nombre de usuario y contraseña es una técnica común (aunque débil) que demuestra los conceptos de identificación (nombre de usuario) y autenticación (contraseña).

La autenticación se basa en cualquiera de estos factores:
- Algo que usted sabe, como una contraseña o un número de identificación personal (PIN): este concepto se basa en el supuesto de que solo el propietario de la cuenta conoce la contraseña secreta o el PIN necesario para acceder a la cuenta.
Las combinaciones de nombre de usuario y contraseña son el mecanismo de autenticación más simple, menos costoso y, por lo tanto, más común implementado en la actualidad.
Por supuesto, las contraseñas a menudo se comparten, se roban, se adivinan o se comprometen de otra manera; por lo tanto, también son uno de los mecanismos de autenticación más débiles.
- Algo que tenga, como una tarjeta inteligente, un token de seguridad o un teléfono inteligente: este concepto se basa en el supuesto de que solo el propietario de la cuenta tiene la clave necesaria para desbloquear la cuenta. Las tarjetas inteligentes, los tokens USB, los teléfonos inteligentes y los llaveros son cada vez más comunes, especialmente en entornos relativamente seguros como instituciones financieras. Muchas aplicaciones en línea, como LinkedIn y Twitter, también han implementado la autenticación de múltiples factores. Aunque las tarjetas inteligentes y los tokens son un poco más caros y complejos que otros mecanismos de autenticación menos seguros, no son (normalmente) prohibitivos, ni complicado de implementar, administrar y usar. Los teléfonos inteligentes que pueden recibir mensajes de texto o ejecutar aplicaciones de token de software como Google Authenticator o Microsoft Authenticator son cada vez más populares debido a su menor costo y conveniencia. Independientemente del método elegido, todas las formas de autenticación multifactor brindan un impulso significativo a la seguridad de la autenticación. Por supuesto, los tokens, las tarjetas inteligentes y los teléfonos inteligentes a veces se pierden, se los roban o se dañan.
| Dato curioso: Debido a los riesgos asociados con los mensajes de texto (como las estafas de portabilidad de teléfonos móviles), el Instituto Nacional de Estándares y Tecnología (NIST) de Estados Unidos ha desaprobado el uso de mensajes de texto para la autenticación multifactor. |
Recuerda que la autenticación se debe basar en: algo que sabes, algo que tienes o algo que eres.
Identificación y autenticación (I&A)
Las diversas técnicas de identificación y autenticación (I&A) que analizamos en las siguientes sección incluyen contraseñas/frases de contraseña y PIN (basadas en el conocimiento); biometría y comportamiento (basado en características); y contraseñas de un solo uso, tokens e inicio de sesión único (SSO).
El componente de identificación es normalmente un mecanismo relativamente simple basado en un nombre de usuario o, en el caso de un sistema o proceso, basado en un nombre de computadora o proceso, dirección de control de acceso a medios (MAC), dirección de protocolo de Internet (IP) o ID de proceso. (PID). Los requisitos de identificación incluyen solo que debe identificar de manera única al usuario (o sistema/proceso) y no debe identificar el rol de ese usuario o la importancia relativa en la organización (la identificación no debe incluir etiquetas como contabilidad o director general). No se deben permitir cuentas comunes, compartidas y grupales, como raíz, administrador o sistema. Tales cuentas no brindan responsabilidad y son objetivos principales para seres maliciosos.
Recuerda: La identificación es el acto de reclamar una identidad específica. La autenticación es el acto de verificar esa identidad.
Autenticación de un solo factor
La autenticación de un solo factor requiere solo uno de los tres factores anteriores discutidos anteriormente (algo que sabes, algo que tienes o algo que eres) para la autenticación. Los mecanismos comunes de autenticación de un solo factor incluyen contraseñas y frases de contraseña, contraseñas de un solo uso y números de identificación personal (PIN).
CONTRASEÑAS Y FRASES DE CONTRASEÑA
“Una contraseña debería ser como un cepillo de dientes. Úselo todos los días; cámbielo regularmente; y NO lo compartas con amigos.” –USENET
Las contraseñas son fácilmente las credenciales de autenticación más comunes y más débiles que se usan en la actualidad. Aunque existen tecnologías de autenticación más avanzadas y seguras disponibles, incluidos los tokens y la biometría, las organizaciones suelen utilizar esas tecnologías como complementos o en combinación con los nombres de usuario y contraseñas tradicionales, en lugar de reemplazarlos.
Una frase de contraseña es una variación de una contraseña; utiliza una secuencia de caracteres o palabras, en lugar de una única contraseña. Por lo general, los atacantes tienen más dificultades para descifrar frases de contraseña que para descifrar contraseñas normales porque las frases de contraseña más largas suelen ser más difíciles de descifrar que las contraseñas más cortas y complejas.
Las frases de contraseña también tienen las siguientes ventajas:
- Los usuarios utilizan con frecuencia las mismas contraseñas para acceder a numerosas cuentas; ¡sus redes corporativas, sus ordenadores personales, su Gmail o Hotmail! cuentas de correo electrónico, sus cuentas de Netflix y sus cuentas de Amazon, por ejemplo. Por lo tanto, un atacante que tiene como objetivo a un usuario específico puede obtener acceso a su cuenta de trabajo si busca un sistema menos seguro, como el ordenador de su hogar, o si compromete una cuenta de Internet (porque el usuario tiene contraseñas convenientemente almacenadas). Los sitios de Internet y los ordenadores personales generalmente no usan frases de contraseña, por lo que aumenta las posibilidades de que tus usuarios tengan que usar diferentes contraseñas/frases de contraseña para acceder a sus cuentas de trabajo.
Inconvenientes:
- Los usuarios pueden recordar y escribir frases de contraseña más fácilmente de lo que pueden recordar y escribir una contraseña críptica mucho más corta que requiere acrobacias con los dedos torcidos para escribirla en un teclado.
- Los pueden poner mucha resistencia a usar frases de contraseña, por lo que puede ser un método difícil de implantar. No todo el mundo es creativo.
- No todos los sistemas admiten frases de contraseña.
- Muchas interfaces y herramientas de línea de comandos no admiten el carácter de espacio que separa las palabras en una frase de contraseña.
- Al final, una frase de contraseña sigue siendo solo una contraseña (aunque mucho más larga y mejor) y, por lo tanto, comparte algunos de los mismos problemas asociados con las contraseñas.

Tal como hemos visto, las contraseñas puedes ser:
· Inseguras
· Fáciles de romper
· Fáciles de robar
· Inconveniente que puede poner los usuarios (ejemplo frases)
· Refutable (no garantiza al 100% que fue un usuario el que accedió)

Imagen que muestra el tiempo que se tarda actualmente en romper una contraseña
Las contraseñas tienen los siguientes controles de inicio de sesión y funciones de administración que debe configurar de acuerdo con la política de seguridad y las mejores prácticas de seguridad de una organización:
Longitud: Generalmente, cuanto más larga, mejor. Una contraseña es, en efecto, una clave de cifrado. Así como las claves de cifrado más grandes (como 1024 bits o 2048 bits) son más difíciles de descifrar, también lo son las contraseñas más largas. Debe configurar los sistemas para que requieran una longitud mínima de contraseña de diez a quince caracteres. Por supuesto, los usuarios pueden olvidar fácilmente contraseñas largas o simplemente poner mucha resistencia al usarla.
Complejidad: las contraseñas seguras contienen una combinación de letras mayúsculas y minúsculas, números y caracteres especiales como # y &. Tener en cuenta que es posible que algunos sistemas no acepten determinados caracteres especiales o que esos caracteres realicen funciones especiales (por ejemplo, en el software de emulación de terminal).
Caducidad (o caducidad máxima de la contraseña): debe establecer la caducidad máxima caducidad de la contraseña para requerir cambios de contraseña a intervalos regulares: los períodos de 30, 60 o 90 días son comunes.
Antigüedad mínima de la contraseña: Esto evita que un usuario cambie su contraseña con demasiada frecuencia. La configuración recomendada es de uno a diez días para evitar que un usuario eluda fácilmente los controles del historial de contraseñas (por ejemplo, cambiando su contraseña cinco veces en unos pocos minutos y luego volviendo a establecer su contraseña original).
Reutilización: la configuración de reutilización de contraseñas (de cinco a diez es común) permite que un sistema recordar las contraseñas utilizadas anteriormente (o, más apropiadamente, sus hashes) para una cuenta específica. Esta configuración de seguridad evita que los usuarios eludan la caducidad máxima de la contraseña al alternar entre dos o tres contraseñas conocidas cuando se les pide que cambien sus contraseñas.
Intentos limitados: este control limita el número de inicios de sesión fallidos intentos y consta de dos componentes: umbral de contador (por ejemplo, tres o cinco) y puesta a cero del contador (por ejemplo, 5 o 30 minutos). El umbral del contador es el número máximo de intentos fallidos consecutivos permitidos antes de que ocurra alguna acción (como deshabilitar automáticamente la cuenta). El reinicio del contador es la cantidad de tiempo entre intentos fallidos.
Duración del bloqueo (o bloqueo de intrusos): cuando un usuario supera el umbral del contador que describimos en el punto anterior, la cuenta se bloquea. Las organizaciones suelen establecer la duración del bloqueo en 30 minutos, pero puede establecerla para cualquier duración. Si establece la duración para siempre, un administrador debe desbloquear la cuenta.
Períodos de tiempo limitados: este control restringe la hora del día en que un usuario puede iniciar sesión. Por ejemplo, puede reducir efectivamente el período de tiempo que los atacantes pueden comprometer sus sistemas al limitar el acceso de los usuarios solo al horario comercial. Sin embargo, este tipo de control se está volviendo menos común en la era moderna de los adictos al trabajo y la economía global, los cuales requieren que los usuarios realicen el trabajo legítimamente a todas horas del día.
Certificados digitales
Se puede instalar un certificado digital en el dispositivo del usuario. Cuando el usuario intenta autenticarse en un sistema, el sistema consultará el dispositivo del usuario en busca del certificado digital para confirmar la identidad del usuario. Si se puede obtener el certificado digital y si se confirma que es genuino, el usuario puede iniciar sesión.
La autenticación con certificado digital también ayuda a obligar a los usuarios a iniciar sesión utilizando solo dispositivos proporcionados por la empresa. Esto presupone el hecho de que el usuario no puede copiar el certificado digital en otro dispositivo, tal vez de propiedad personal, o que un intruso no puede copiar el certificado en su propio dispositivo.
Al implementar certificados digitales en dispositivos como ordenadores portátiles, los administradores deben asegurarse de implementar un certificado por dispositivo o por usuario en cada ordenador portátil, no un certificado general de la empresa.
Biométrica

El único método absoluto para identificar positivamente a un individuo es basar la autenticación en alguna característica física o conductual única de ese individuo. La identificación biométrica utiliza características físicas, incluidas las huellas dactilares, la geometría de la mano y rasgos faciales como los patrones de la retina y el iris.
La biometría del comportamiento se basa en mediciones y datos derivados de una acción, y mide indirectamente las características del cuerpo humano. Las características de comportamiento incluyen voz, firma y patrones de pulsación de teclas.
La biometría se basa en el tercer factor de autenticación: algo que eres.
Los sistemas de control de acceso biométrico aplican el concepto de identificación y autenticación (I&A) de forma ligeramente diferente, dependiendo de su uso:
- Controles de acceso físico: El individuo presenta los datos biométricos requeridos característica y el sistema intenta identificar a la persona haciendo coincidir la característica de entrada con su base de datos de personal autorizado. Este tipo de control también se conoce como búsqueda de uno a muchos.
- Controles de acceso lógico: el usuario ingresa un nombre de usuario o PIN (o inserta una tarjeta inteligente) y luego presenta la característica biométrica requerida para la verificación. El sistema intenta autenticar al usuario haciendo coincidir la identidad declarada y el archivo de imagen biométrica almacenado para esa cuenta. Este tipo de control también se conoce como búsqueda uno a uno.
La autenticación biométrica, en sí misma, no proporciona una autenticación sólida porque se basa solo en uno de los tres requisitos de autenticación: algo que tu eres. Para ser considerado un mecanismo de autenticación realmente sólido, la autenticación biométrica debe incluir algo que tu sepas y algo que tienes.
Responsabilidad
El concepto de responsabilidad se refiere a la capacidad de un sistema para asociar usuarios y procesos con sus acciones (lo que hicieron). Los registros de auditoría y los registros del sistema son componentes de la responsabilidad.
Los sistemas utilizan registros de auditoría y pistas de auditoría principalmente como medio para solucionar problemas y verificar eventos. Los usuarios no deben ver los registros de auditoría y las pistas de auditoría como una amenaza o como un “hermano mayor” que los vigila porque no se puede confiar en ellos.
De hecho, los usuarios astutos consideran estos mecanismos como protectores, porque no solo prueban lo que hicieron, sino que también ayudan a probar lo que no hicieron. Aún así, es aconsejable que los usuarios sepan que los sistemas que utilizan, registran sus acciones.
Un concepto de seguridad importante que está estrechamente relacionado con la responsabilidad de lo que se hace, ese “responder de mis acciones”, es el no repudio. No repudio significa que un usuario (nombre de usuario Pepe Pérez) no puede negar una acción porque su identidad está positivamente asociada con sus acciones.
El no repudio es un concepto legal importante. Si un sistema permite que los usuarios inicien sesión con una cuenta de usuario genérica, o una cuenta de usuario que tiene una contraseña ampliamente conocida, o ninguna cuenta de usuario, entonces no puede asociar absolutamente a ningún usuario con una determinada acción (maliciosa) o ( no autorizado) en ese sistema, lo que hace que sea extremadamente difícil procesar o disciplinar a ese usuario.
La responsabilidad en los servicios AAA (autenticación, autorización y responsabilidad) registra siempre lo que hizo un sujeto. Está por descontando, que no se debe aceptar ya ningún sistema que no cumpla las AAA.
No repudio significa que un usuario no puede negar una acción porque usted puede asociarlo irrefutablemente con esa acción.
Gestión de sesiones
Una sesión es un término formal que se refiere al diálogo de un usuario individual, o a una serie de interacciones, con un sistema de información. Los sistemas de información necesitan rastrear las sesiones de los usuarios individuales para distinguir correctamente las acciones de un usuario de las de otro.
Para proteger la confidencialidad e integridad de los datos accesibles a través de una sesión, los sistemas de información generalmente utilizan tiempos de espera de sesión o actividad para evitar que un usuario no autorizado continúe una sesión que ha estado inactiva o inactiva durante un período de tiempo específico.
Se utilizan dos medios principales de tiempos de espera de sesión:
- Protectores de pantalla. Implementado por el sistema operativo, un protector de pantalla bloquea la estación de trabajo o el dispositivo móvil y requiere que el usuario vuelva a iniciar sesión en el sistema después de un período de inactividad. El protector de pantalla de la estación de trabajo o del dispositivo móvil protege todas las sesiones de la aplicación. Asegúrese de que esto realmente bloquee la pantalla o el dispositivo, ya que algunos sistemas se pueden configurar para que no requieran un PIN o contraseña para desbloquearlos.
- Tiempos de espera de inactividad. Las aplicaciones de software individuales pueden utilizar un auto función de bloqueo o cierre de sesión automático si un usuario ha estado inactivo durante un período de tiempo específico.
Por ejemplo, si un usuario autorizado deja una terminal de un ordenador desbloqueada o una ventana del navegador en una estación de trabajo desatendida, un usuario no autorizado puede simplemente sentarse en la estación de trabajo y continuar la sesión.
Los tiempos de espera de inactividad de la estación de trabajo se denominaron originalmente “protectores de pantalla” para evitar que una imagen estática en una pantalla de tubo de rayos catódicos (CRT) se queme en la pantalla. Si bien los monitores actuales no requieren esta protección, el término “protector de pantalla” todavía es de uso común.
Registro y acreditación de identidad
Los procesos formales de registro de usuarios son importantes para el aprovisionamiento seguro de cuentas, particularmente en organizaciones grandes donde no es práctico o posible conocer a todos los trabajadores. Esto es particularmente crítico en entornos SSO donde los usuarios tendrán acceso a múltiples sistemas y aplicaciones.
La prueba de identidad a menudo comienza en el momento de la contratación, cuando generalmente se requiere que los nuevos trabajadores muestren una identificación emitida por el gobierno y el estado legal de derecho a trabajar. Estos procedimientos deben constituir la base para el registro inicial de usuarios en los sistemas de información.
Las organizaciones deben tomar varias precauciones al registrarse y aprovisionar usuarios:
Identidad del usuario. La organización debe asegurarse de que las nuevas cuentas de usuario se aprovisionen y entreguen al usuario correcto.
Protección de la privacidad. La organización no debe utilizar el número de la Seguridad Social por ejemplo, fecha de nacimiento u otra información privada sensible para autenticar al usuario.
En su lugar, se deben utilizar otros valores, como el número de empleado (u otros que no puedan obtener otros empleados).
Credenciales temporales. La organización debe asegurarse de que las credenciales de inicio de sesión temporales se asignen a la persona correcta. Otros no deberían poder adivinar fácilmente las credenciales temporales. Finalmente, las credenciales temporales deben configurarse para que caduquen en un corto período de tiempo.
Acceso a la primogenitura. La organización debe revisar periódicamente qué derecho de nacimiento se otorga a los nuevos trabajadores, siguiendo los principios de necesidad de saber y privilegio mínimo.
Se producen consideraciones adicionales sobre la identidad del usuario cuando un usuario intenta iniciar sesión en un sistema. Estos son
Ubicación geográfica. Esto se puede derivar de la dirección IP del usuario.
Esto no es absolutamente confiable, pero puede ser útil para determinar la ubicación del usuario. Muchos dispositivos, en particular los teléfonos inteligentes y las tabletas, utilizan la tecnología GPS para la información de ubicación, que generalmente es más confiable que la dirección IP.
Estación de trabajo en uso. La organización puede tener políticas sobre si un usuario puede iniciar sesión con una estación de trabajo de quiosco de propiedad personal o pública.
Tiempo transcurrido desde el último inicio de sesión. Cuánto tiempo ha pasado desde la última vez que el usuario iniciado sesión en el sistema o la aplicación.
Intento de inicio de sesión después de intentos fallidos. Si ha habido intentos de inicio de sesión fallidos recientes.
Dependiendo de las condiciones anteriores, el sistema puede configurarse para presentar desafíos adicionales al usuario. Estos desafíos aseguran que la persona que intenta iniciar sesión sea realmente el usuario autorizado, no otra persona o máquina.
Esto se conoce como autenticación basada en riesgos.
Conclusión
Como hemos visto, la gestión de identidades y accesos es un conjunto de procesos y tecnologías que se utilizan para controlar el acceso a activos críticos. Junto con otros controles críticos, IAM es parte del núcleo de la seguridad de la información: cuando se implementa correctamente, las personas no autorizadas no pueden acceder a los activos críticos. Es menos probable que ocurran violaciones y otros abusos de información y activos.