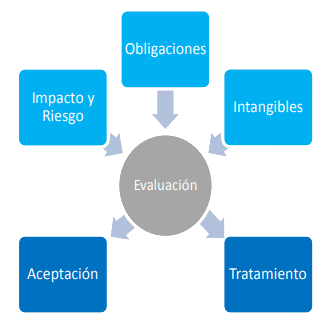
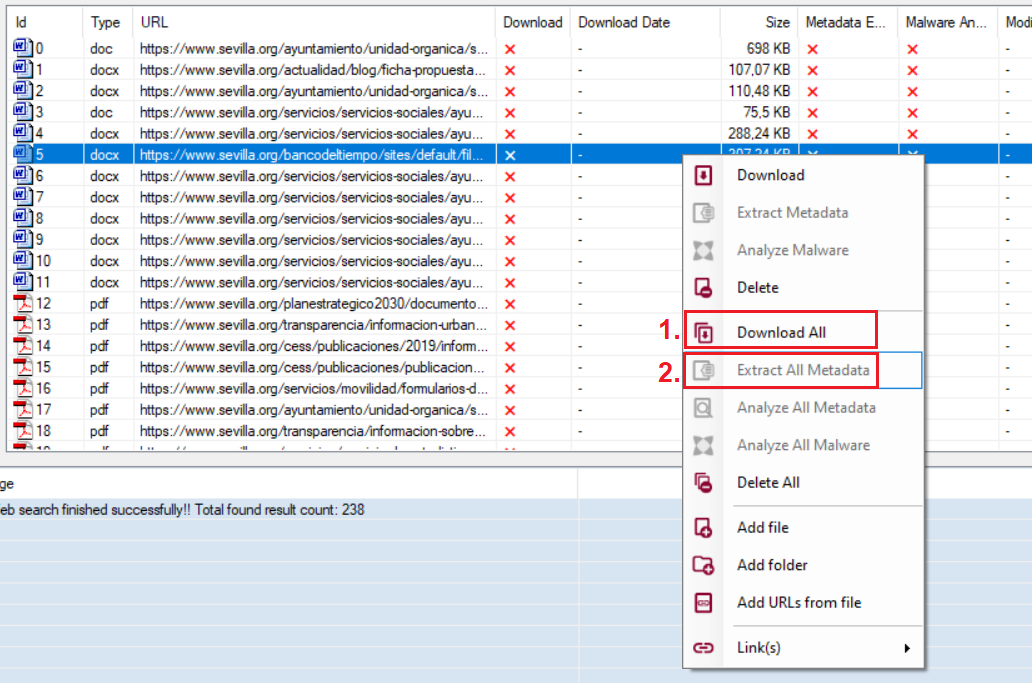
A la vista de los impactos y riesgos a que está expuesto el sistema, hay que tomar una serie de decisiones condicionadas por la gravedad de los mismos y por las obligaciones a las que esté sometida la Organización por ley, reglamento sectorial o por contrato
Pueden aparecer consideraciones adicionales sobre la capacidad de la Organización para aceptar ciertos impactos de naturaleza intangible tales como:
Imagen pública de cara a la Sociedad (aspectos reputacionales).
Política interna: relaciones con los propios empleados, tales como capacidad de contratar al personal idóneo, capacidad de retener a los mejores, capacidad de soportar rotaciones de personas, capacidad de ofrecer una carrera profesional atractiva, etc.
Relaciones con los proveedores, tales como capacidad de llegar a acuerdos ventajosos a corto, medio o largo plazo, capacidad de obtener trato prioritario, etc.
Relaciones con los clientes o usuarios, tales como capacidad de retención, capacidad de incrementar la oferta, capacidad de diferenciarse frente a la competencia, …
Relaciones con otras organizaciones, tales como capacidad de alcanzar acuerdos estratégicos, alianzas, etc. • nuevas oportunidades de negocio, tales como formas de recuperar la inversión en seguridad.
Acceso a sellos o calificaciones reconocidas de seguridad.
Todas las consideraciones anteriores desembocan en una calificación de cada riesgo significativo, determinándose si…
Es crítico y requiere atención urgente.
Es grave y requiere atención.
Es apreciable en el sentido de que pueda ser objeto de estudio para su tratamiento.
Es asumible, en el sentido de que no se van a tomar acciones para atajarlo Las opciones 1,2 y 3 requieren tratamiento técnico del riesgo.
La opción 4, aceptación del riesgo, siempre es arriesgada y hay que tomarla con prudencia y justificación cuando el impacto y el riesgo residual es asumible o cuando el coste de las salvaguardas oportunas es desproporcionado en comparación al impacto y riesgo residuales.
El Proceso de Evaluación
Impacto y riesgo residual son una medida del estado presente, desde la inseguridad potencial (sin salvaguarda alguna) y las medidas adecuadas que reducen impacto y riesgo a valores aceptables.
Los párrafos siguientes se refieren conjuntamente a impacto y riesgo.
Si el valor residual es igual al valor potencial, las salvaguardas existentes no valen para nada, típicamente no porque no haya nada hecho, sino porque hay elementos fundamentales sin hacer.
Es importante entender que un valor residual es sólo un número. Para su correcta interpretación debe venir acompañado de la relación de lo que se debería hacer y no se ha hecho; es decir, de las vulnerabilidades que presenta el sistema. Los responsables de la toma de decisiones deberán prestar cuidadosa atención a esta relación de tareas pendientes, que se denomina Informe de Insuficiencias o de vulnerabilidades.
Aceptación de los Riesgos
La Dirección de la Organización sometida al análisis de riesgos debe determinar el nivel de impacto y riesgo aceptable. Más propiamente dicho, debe aceptar la responsabilidad de las insuficiencias. Esta decisión no es técnica. Puede ser una decisión política o gerencial o puede venir determinada por ley o por compromisos contractuales con proveedores o usuarios. Estos niveles de aceptación se pueden establecer por activo o por agregación de activos (en un determinado departamento, en un determinado servicio, en una determinada dimensión, …)
Cualquier nivel de impacto y/o riesgo es aceptable si lo conoce y acepta formalmente la Dirección
Para tomar una u otra decisión hay que enmarcar los riesgos soportados por el sistema de información dentro de un contexto más amplio que evalúe los aspectos intangibles del negocio
Tratamiento de los riesgos
La Dirección puede decidir aplicar algún tratamiento al sistema de seguridad desplegado para proteger el sistema de información. Hay dos grandes opciones:
Reducir el riesgo residual (aceptar un menor riesgo).
Ampliar el riesgo residual (aceptar un mayor riesgo).
En condiciones de riesgo residual extremo, casi la única opción es reducir el riesgo.
En condiciones de riesgo residual aceptable, podemos optar entre aceptar el nivel actual o ampliar el riesgo asumido. En cualquier caso hay que mantener una monitorización continua de las circunstancias para que el riesgo formal cuadre con la experiencia real y reaccionemos ante cualquier desviación significativa.
En condiciones de riesgo residual medio, podemos observar otras características como las pérdidas y ganancias que pueden verse afectadas por el escenario presente, o incluso analizar el estado del sector en el que operamos para compararnos con la norma.
Eliminación del Riesgo
La eliminación de la fuente de riesgo es una opción frente a un riesgo que no es aceptable. En un sistema podemos eliminar varias cosas, siempre que no afecten a la esencia de la Organización. Es extremadamente raro que podamos prescindir de la información o los servicios esenciales por cuanto constituyen la misión de la Organización. Más viable es prescindir de otros componentes no esenciales, que están presentes simple y llanamente para implementar la misión, pero no son parte constituyente de la misma. Esta opción puede tomar diferentes formas:
Eliminar cierto tipo de activos, emplean otros en su lugar. Por ejemplo: cambiar de sistema operativo, de fabricante de equipos, …
Reordenar la arquitectura del sistema (el esquema de dependencias en nuestra terminología) de forma que alteremos el valor acumulado en ciertos activos expuestos a grandes amenazas. Por ejemplo: segregar redes, desdoblar equipos para atender a necesidades concretas, alejando lo más valioso de lo más expuesto, …
Las decisiones de eliminación de las fuentes de riesgo suponen realizar un nuevo análisis de riesgos sobre el sistema modificado.
Mitigación del Riesgo
La mitigación del riesgo se refiere a una de dos opciones:
Reducir la degradación causada por una amenaza (a veces se usa la expresión “acotar el impacto”).
Reducir la probabilidad de que una amenaza de materializa.
En ambos casos lo que hay que hacer es ampliar o mejorar el conjunto de salvaguardas. En términos de madurez de las salvaguardas: subir de nivel.
Algunas salvaguardas se traducen en el despliegue de más equipamiento. Estos nuevos activos estarán a su vez sujetos a amenazas que pueden perjudicar a los activos esenciales.
Hay que repetir el análisis de riesgos, ampliándolo con el nuevo despliegue de medios y, por supuesto, cerciorarse de que el riesgo del sistema ampliado es menor que el del sistema original.
Compartición del Riesgo
Hay dos formas básicas de compartir riesgo:
Riesgo cualitativo: se comparte por medio de la externalización de componentes del sistema, de forma que se reparten responsabilidades: unas técnicas para el que opera el componente técnico; y otras legales según el acuerdo que se establezca en la prestación del servicio.
Riesgo cuantitativo: se comparte por medio de la contratación de seguros, de forma que a cambio de una prima, el tomador reduce el impacto de las posibles amenazas y el asegurador corre con las consecuencias.
Hay multitud de tipos y cláusulas de seguros para concretar el grado de responsabilidad de cada una de las partes.
Cuando se comparten riesgos cambia, bien el conjunto de componentes del sistema, bien su valoración, requiriéndose un nuevo análisis del sistema resultante.
Financiación del Riesgo
Cuando se acepta un riesgo, la Organización hará bien en reservar fondos para el caso de que el riesgo se concrete y haya que responder de sus consecuencias. A veces de habla de “fondos de contingencia” y también puede ser parte de los contratos de aseguramiento. Normalmente esta opción no modifica nada del sistema y nos vale el análisis de riesgos disponible.
Conclusión
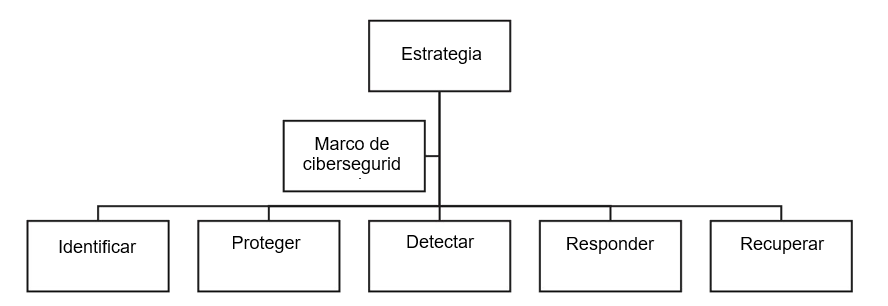
Hemos visto todo el proceso del tratamiento de riesgo, normalmente el análisis del riesgo se enfoca en las dimensiones que queremos definir para nuestro sistema de seguridad de la información. Si nos movemos en IS 27001 entonces hablaremos de confidencialidad, disponibilidad y integridad. Pero si hablamos del ENS, entonces además deberemos introducir trazabilidad y autenticidad. Por lo que nuestros salvaguardas deberán de ir orientados a las 5 dimensiones que contempla el ENS.
Se definen las salvaguardas, o contra medidas, como aquellos procedimientos o mecanismos tecnológicos que reducen el riesgo. Ante el amplio abanico de posibles salvaguardas a considerar, es necesario hacer una criba inicial para quedarnos con aquellas que son relevantes para lo que hay que proteger. En esta criba se deben tener en cuenta los siguientes aspectos:
Tipo de activos a proteger, pues cada tipo se protege de una forma específica.
Dimensión o dimensiones de seguridad que requieren protección.
Amenazas de las que necesitamos protegernos.
Si existen salvaguardas alternativas.
Además, es prudente establecer un principio de proporcionalidad y tener en cuenta:
El mayor o menor valor propio o acumulado sobre un activo, centrándonos en lo más valioso y obviando lo irrelevante.
La mayor o menor probabilidad de que una amenaza ocurra, centrándonos en los riesgos más importantes (ver zonas de riesgo).
La cobertura del riesgo que proporcionan salvaguardas alternativas Esto lleva a dos tipos de declaraciones para excluir una cierta salvaguarda del conjunto de las que conviene analizar:
no aplica – se dice cuando una salvaguarda no es de aplicación porque técnicamente no es adecuada al tipo de activos a proteger, no protege la dimensión necesaria o no protege frente a la amenaza en consideración.
no se justifica – se dice cuando la salvaguarda aplica, pero es desproporcionada al riesgo que tenemos que proteger Como resultado de estas consideraciones dispondremos de una “declaración de aplicabilidad” o relación de salvaguardas que deben ser analizadas como componentes nuestro sistema de protección.
¿Cómo afectan las Salvaguardas en el Análisis del Riesgo?
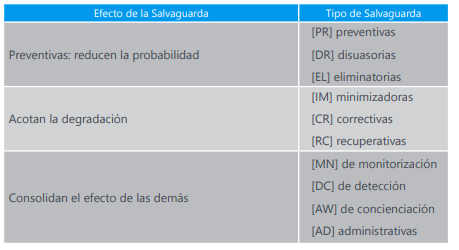
Las salvaguardas entran en el cálculo del riesgo de dos formas:
Reduciendo la probabilidad de las amenazas: Se llaman salvaguardas preventivas. Las ideales llegan a impedir completamente que la amenaza se materialice.
Limitando el daño causado: Hay salvaguardas que directamente limitan la posible degradación, mientras que otras permiten detectar inmediatamente el ataque para frenar que la degradación avance. Incluso algunas salvaguardas se limitan a permitir la pronta recuperación del sistema cuando la amenaza lo destruye. En cualquiera de las versiones, la amenaza se materializa; pero las consecuencias se limitan.
¿Cómo se miden las Salvaguardas: Eficacia y Madurez?
Las salvaguardas se caracterizan, además de por su existencia, por su eficacia frente al riesgo que pretenden conjurar. La salvaguarda ideal es 100% eficaz combinando 2 factores: desde el punto de vista técnico:
es técnicamente idónea para enfrentarse al riesgo que protege.
se emplea siempre desde el punto de vista de operación de la salvaguarda.
está perfectamente desplegada, configurada y mantenida.
existen procedimientos claros de uso normal y en caso de incidencias.
los usuarios están formados y concienciados.
existen controles que avisan de posibles fallos.
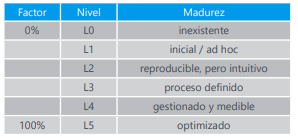
Entre una eficacia del 0% para aquellas que faltan y el 100% para aquellas que son idóneas y que están perfectamente implantadas, se estimará un grado de eficacia real en cada caso concreto. Para medir los aspectos organizativos, se puede emplear una escala de madurez que recoja en forma de factor corrector la confianza que merece el proceso de gestión de la salvaguarda:
Componente o funcionalidad de un sistema de información susceptible de ser atacado deliberada o accidentalmente con consecuencias para la organización.
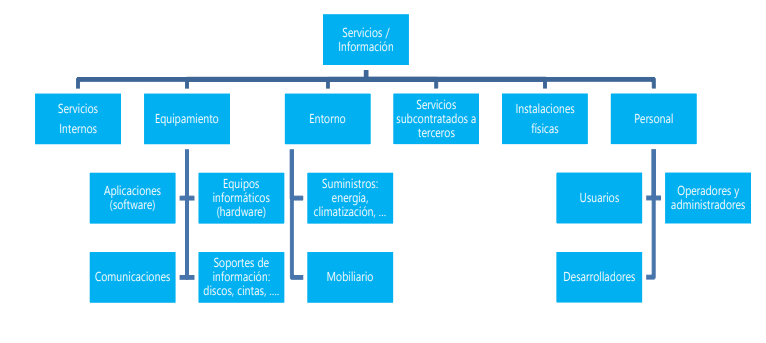
En un sistema de información hay 2 cosas esenciales: la información que maneja y los servicios que presta. Estos activos esenciales marcan los requisitos de seguridad para todos los demás componentes del sistema.
Subordinados a dichos elementos se pueden identificar otros activos relevantes:
Servicios auxiliares que se necesitan para poder organizar el sistema.
Las aplicaciones informáticas (software) que permiten manejar los datos.
Los equipos informáticos (hardware) y que permiten hospedar datos, aplicaciones y servicios.
Los soportes de información que son dispositivos de almacenamiento de datos.
El equipamiento auxiliar que complementa el material informático.
Las redes de comunicaciones que permiten intercambiar datos.
Las instalaciones que acogen equipos informáticos y de comunicaciones.
Las personas que explotan u operan todos los elementos anteriormente citados.
No todos los activos son de la misma especie. Dependiendo del tipo de activo, las amenazas y las salvaguardas son diferentes.
¿Cuál es el valor de los activos?
La valoración se debe realizar desde la perspectiva de la necesidad de proteger. Cuanto más valioso es un activo, mayor nivel de protección requeriremos en la dimensión (o dimensiones) de seguridad que sean pertinentes.
El valor puede ser propio, o puede ser acumulado. Se dice que los activos inferiores en un esquema de dependencias, acumulan el valor de los activos que se apoyan en ellos. El valor nuclear suele estar en la información que el sistema maneja y los servicios que se prestan (activos denominados esenciales), quedando los demás activos subordinados a las necesidades de explotación y protección de lo esencial. La valoración es la determinación del coste que supondría recuperarse de una incidencia que destrozara el activo.
Hay muchos factores a considerar:
Coste de reposición: adquisición e instalación.
Coste de mano de obra (especializada) invertida en recuperar (el valor) del activo
Lucro cesante: pérdida de ingresos.
Capacidad de operar: confianza de los usuarios y proveedores que se traduce en una pérdida de actividad o en peores condiciones económicas.
Sanciones por incumplimiento de la ley u obligaciones contractuales.
Daño a otros activos, propios o ajenos.
Daño a personas.
Daños medioambientales: la valoración puede ser cuantitativa (con una cantidad numérica) o cualitativa (en alguna escala de niveles).
Los criterios más importantes a respetar son:
La homogeneidad: es importante poder comparar valores aunque sean de diferentes dimensiones a fin de poder combinar valores propios y valores acumulados, así como poder determinar si es más grave el daño en una dimensión o en otra.
La relatividad: es importante poder relativizar el valor de un activo en comparación con otros activos.
Ambos criterios se satisfacen con valoraciones económicas (coste dinerario requerido para curar el activo) y es frecuente la tentación de ponerle precio a todo. Si se consigue, excelente.
Incluso es fácil ponerle precio a los aspectos más tangibles (equipamiento, horas de trabajo, etc.). Pero al entrar en valoraciones más abstractas (intangibles como la credibilidad de la Organización) la valoración económica exacta puede ser escurridiza y motivo de agrias disputas entre los analistas.
Valoración y activos
¿Qué aporta una Valoración Cualitativa?
Las escalas cualitativas permiten avanzar con rapidez, posicionando el valor de cada activo en un orden relativo respecto de los demás. Es frecuente plantear estas escalas como órdenes de magnitud y, en consecuencia, derivar estimaciones del orden de magnitud del riesgo.
La limitación de las valoraciones cualitativas es que no permiten comparar valores más allá de su orden relativo. No se pueden sumar valores.
¿Podemos realizar una Valoración Cuantitativa?
Las valoraciones numéricas absolutas cuestan mucho esfuerzo; pero permiten sumar valores numéricos de forma absolutamente natural. La interpretación de las sumas no es nunca motivo de controversia. Si la valoración es dineraria, además se pueden hacer estudios económicos comparando lo que se arriesga con lo que cuesta la solución respondiendo a las preguntas:
¿Vale la pena invertir tanto dinero en esta salvaguarda?
¿Qué conjunto de salvaguardas optimizan la inversión?
¿En qué plazo de tiempo se recupera la inversión?
¿Cuánto es razonable que cueste la prima de un seguro?
Dependencia entre activos y amenazas
Dependencias entre Activos
Los activos vienen a formar árboles o grafos de dependencias donde la seguridad de los activos que se encuentran más arriba en la estructura o superiores depende de los activos que se encuentran más abajo o inferiores. Estas estructuras reflejan de arriba hacia abajo las dependencias, mientas que de abajo hacia arriba la propagación del daño caso de materializarse las amenazas. Se dice que un “activo superior” depende de otro “activo inferior” cuando las necesidades de seguridad del superior se reflejan en las necesidades de seguridad del inferior. Típicamente, la estructura de dependencia sigue el siguiente grafo:
¿Qué son las Amenazas?
Las amenazas son “cosas que ocurren”. Y, de todo lo que puede ocurrir, interesa lo que puede pasarle a nuestros activos y causar un daño.
Típicamente:
De origen natural: Hay accidentes naturales (terremotos, inundaciones, …). Ante esos avatares el sistema de información es víctima pasiva, pero debemos tener en cuenta lo que puede suceder.
Del entorno (de origen industrial): Hay desastres industriales (contaminación, fallos eléctricos, …) ante los cuales el sistema de información es víctima pasiva; pero no por ser pasivos hay que permanecer indefensos.
Defectos de las aplicaciones: Hay problemas que nacen directamente en el equipamiento propio por defectos en su diseño o en su implementación, con consecuencias potencialmente negativas sobre el sistema. Frecuentemente se denominan vulnerabilidades técnicas o, simplemente, vulnerabilidades.
Causadas por las personas de forma accidental: Las personas con acceso al sistema de información pueden ser causa de problemas no intencionados, típicamente por error o por omisión.
Causadas por las personas de forma deliberada: Las personas con acceso al sistema de información pueden ser causa de problemas intencionados: ataques deliberados; bien con ánimo de beneficiarse indebidamente, bien con ánimo de causar daños y perjuicios a los legítimos propietarios. No todas las amenazas afectan a todos los activos, sino que hay una cierta relación entre el tipo de activo y lo que le podría ocurrir.
¿Afectan las amenazas al valor de los activos?
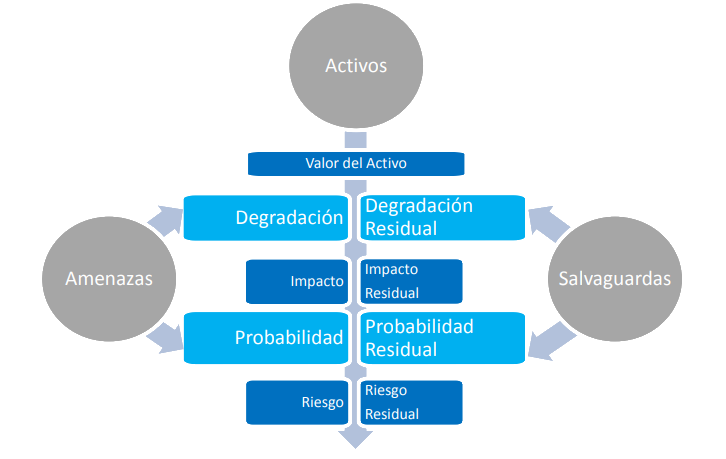
Una vez determinado que una amenaza puede perjudicar a un activo, hay que valorar su influencia en el valor del activo, en dos sentidos:
Degradación: cuán perjudicado resultaría el [valor del] activo. La degradación mide el daño causado por un incidente en el supuesto de que ocurriera. La degradación se suele caracterizar como una fracción del valor del activo y así aparecen expresiones como que un activo se ha visto “totalmente degradado”, o “degradado en una pequeña fracción”.
Probabilidad: cuán probable o improbable es que se materialice la amenaza. La probabilidad de ocurrencia es más compleja de determinar y de expresar. A veces se modela cualitativamente por medio de alguna escala nominal. A veces se modela numéricamente como una frecuencia de ocurrencia. Es habitual usar 1 año como referencia, de forma que se recurre a la tasa anual de ocurrencia como medida de la probabilidad de que algo ocurra.
Impacto y Riesgo Potencial
¿Qué es el Impacto?
Conociendo el valor de los activos y la degradación que causan las amenazas, es directo derivar el impacto que estas tendrían sobre el sistema. Se miden dos variables de impacto:
Impacto acumulado: Es el calculado sobre un activo teniendo en cuenta su valor acumulado (el propio mas el acumulado de los activos que dependen de él) y las amenazas a que está expuesto.
Impacto repercutido: Es el calculado sobre un activo teniendo en cuenta su valor propio y las amenazas a que están expuestos los activos de los que depende.
¿Qué es el Riesgo Potencial?
Se denomina riesgo a la medida del daño probable sobre un sistema. Conociendo el impacto de las amenazas sobre los activos, para derivar el riesgo no hay más que tener en cuenta la probabilidad de ocurrencia.
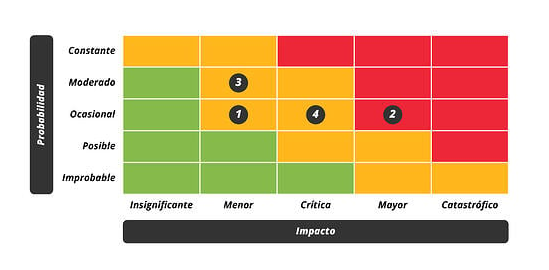
El riesgo crece con el impacto y con la probabilidad, pudiendo distinguirse una serie de zonas a tener en cuenta en el tratamiento del riesgo:
zona 1 – riesgos muy probables y de muy alto impacto.
zona 2 – cubre un amplio rango desde situaciones improbables y de impacto medio, hasta situaciones muy probables pero de impacto bajo o muy bajo.
zona 3 – riesgos improbables y de bajo impacto.
zona 4 – riesgos improbables pero de muy alto impacto.
Riesgo acumulado: Es el calculado sobre un activo teniendo en cuenta el impacto acumulado sobre un activo debido a una amenaza y la probabilidad de la amenaza.
Riesgo repercutido: Es el calculado sobre un activo teniendo en cuenta el impacto repercutido sobre un activo debido a una amenaza y la probabilidad de la amenaza.
MAGERIT es la metodología de análisis y gestión de riesgos elaborada por el Consejo Superior de Administración Electrónica, que permite estudiar los riesgos que soporta un sistema de información y el entorno asociado a él.
MAGERIT propone la realización de un análisis de los riesgos que implica la evaluación del impacto que una violación de la seguridad tiene en la organización; señala los riesgos existentes, identificando las amenazas que acechan al sistema de información, y determina la vulnerabilidad del sistema de prevención de dichas amenazas, obteniendo unos resultados.
Los resultados del análisis de riesgos permiten a la Gestión de Riesgos recomendar las medidas apropiadas que deberían adoptarse para conocer, prevenir, impedir, reducir o controlar los riesgos identificados y así reducir al mínimo su potencialidad o sus posibles perjuicios. MAGERIT interesa a todos aquellos que trabajan con información digital y sistemas informáticos para tratarla. Si dicha información, o los servicios que se prestan gracias a ella, son valiosos, MAGERIT les permitirá saber cuánto valor está en juego y les ayudará a protegerlo.
Conocer el riesgo al que están sometidos los elementos de trabajo es, simplemente, imprescindible para poder gestionarlos. Con MAGERIT se persigue una aproximación metódica que no deje lugar a la improvisación, ni dependa de la arbitrariedad del analista. El análisis y gestión de los riesgos es un aspecto clave del Real Decreto 311/2022, de 3 de mayo, por el que se regula el Esquema Nacional de Seguridad en el ámbito de la Administración Electrónica que tiene la finalidad de poder dar satisfacción al principio de proporcionalidad en el cumplimiento de los principios básicos y requisitos mínimos para la protección adecuada de la información.
En esta línea presentamos este documento, en el que resaltamos los aspectos fundamentales del método Magerit, el cual confiamos que sea de utilidad para todos los que nos vemos involucrados en hacer frente a los retos planteados en este proceso de cambio.
El análisis del riesgo
Un análisis de riesgos TIC es recomendable en cualquier Organización que dependa de los sistemas de información para el cumplimiento de su misión.
En particular en cualquier entorno donde se practique la tramitación electrónica de bienes y servicios, sea en contexto público o privado.
El análisis de riesgos permite tomar decisiones de gestión y asignar recursos con perspectiva de negocio, sean tecnológicos, humanos o financieros.
El análisis de riesgos es una herramienta de gestión que permite tomar decisiones. Las decisiones pueden tomarse antes de desplegar un servicio o con éste funcionando. Es muy deseable hacerlo antes, de forma que las medidas que haya que tomar se incorporen en el diseño del servicio, en la elección de componentes, en el desarrollo del sistema y en los manuales de usuario. Todo lo que sea corregir riesgos imprevistos es costoso en tiempo propio y ajeno, lo que puede ir en detrimento de la imagen prestada por la Organización y puede suponer, en último extremo, la pérdida de confianza en su capacidad. Siempre se ha dicho que es mejor prevenir que curar y aquí se aplica: no espere a que un servicio haga agua; hay que prever y estar prevenido.
Realizar un análisis de riesgos es laborioso y costoso. Levantar un mapa de activos y valorarlos requiere la colaboración de muchos perfiles dentro de la Organización, desde los niveles de gerencia hasta los técnicos. Y no solo es que haya que involucrar a muchas personas, sino que hay que lograr una uniformidad de criterio entre todos pues, si importante es cuantificar los riesgos, más importante aún es relativizarlos. Y esto es así porque típicamente en un análisis de riesgos aparecen multitud de datos. La única forma de afrontar la complejidad es centrarse en lo más importante (máximo impacto, máximo riesgo) y obviar lo que es secundario o incluso despreciable. Pero si los riesgos no están bien ordenados en términos relativos, su interpretación es imposible.
En resumen, un análisis de riesgos no es una tarea menor que realiza cualquiera en sus ratos libres. Es una tarea mayor que requiere esfuerzo y coordinación. Por tanto debe ser planificada y justificada.
La gestión del riesgo
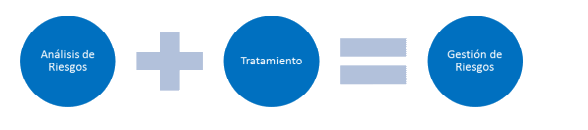
La Gestión de Riesgos implica dos grandes tareas a realizar:
Análisis de riesgos, que permite determinar qué tiene la Organización y estimar lo que podría pasar.
Tratamiento de los riesgos, que permite organizar la defensa concienzuda y prudente, defendiendo para que no pase nada malo y al tiempo estando preparados para atajar las emergencias, sobrevivir a los incidentes y seguir operando en las mejores condiciones; como nada es perfecto, se dice que el riesgo se reduce a un nivel residual que la Dirección asume. Ambas actividades, análisis y tratamiento se combinan en el proceso denominado Gestión de Riesgos.
El análisis de riesgos considera los siguientes elementos:
Activos, que son los elementos del sistema de información (o estrechamente relacionados con este) que soportan la misión de la Organización.
Amenazas, que son cosas que les pueden pasar a los activos causando un perjuicio a la Organización.
Salvaguardas (o contra medidas), que son medidas de protección desplegadas para que aquellas amenazas no causen [tanto] daño.
Con estos elementos se puede estimar:
El impacto: lo que podría pasar.
El riesgo: lo que probablemente pase.
El análisis de riesgos permite analizar estos elementos de forma metódica para llegar a conclusiones con fundamento y proceder a la fase de tratamiento. Informalmente, se puede decir que la gestión de la seguridad de un sistema de información es la gestión de sus riesgos y que el análisis permite racionalizar dicha gestión.
El análisis de riesgos es una aproximación metódica para determinar el riesgo siguiendo unos pasos pautados:
Determinar los activos relevantes para la Organización, su interrelación y su valor, en el sentido de qué perjuicio (coste) supondría su degradación.
Determinar a qué amenazas están expuestos aquellos activos.
Determinar qué salvaguardas hay dispuestas y cuán eficaces son frente al riesgo.
Estimar el impacto, definido como el daño sobre el activo derivado de la materialización de la amenaza
Estimar el riesgo, definido como el impacto ponderado con la tasa de ocurrencia (o expectativa de materialización) de la amenaza Estas valoraciones son teóricas en el caso de que no hubiera salvaguarda alguna desplegada. Una vez obtenido este escenario teórico, se incorporan las salvaguardas del paso 3, derivando estimaciones realistas de impacto y riesgo
Conclusión
Todas las administraciones públicas están obligadas a tener implantado el ENS, por lo que la herramienta para el análisis de riesgo recomendada será Pilar, si bien Pilar no es todo lo amigable que pueden ser otras herramientas, es la que permite exportar el formato de datos al CCN-CERT para informar el estado de la ciberseguridad en cada entidad. Por tal motivo tiene compatibilidad con herramientas como Clara, Lucía.
Por lo que independientemente de que se use Pilar, Excel o una aplicación de un tercero para realizar la gestión del riesgo. La metodología está clara que tendrá que ser Magerit.
Aquí hay unas guías técnicas al respecto de Magerit:
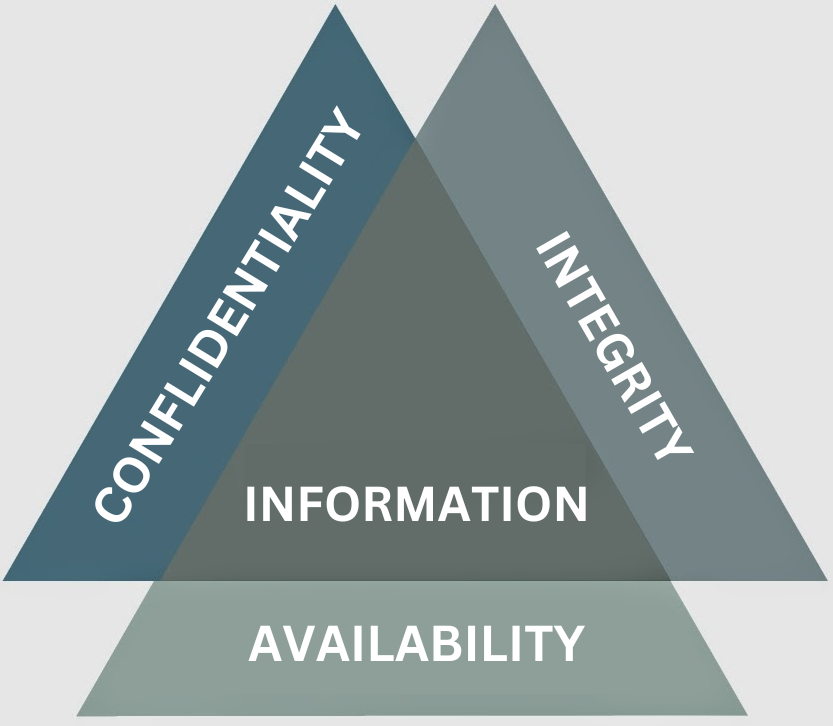
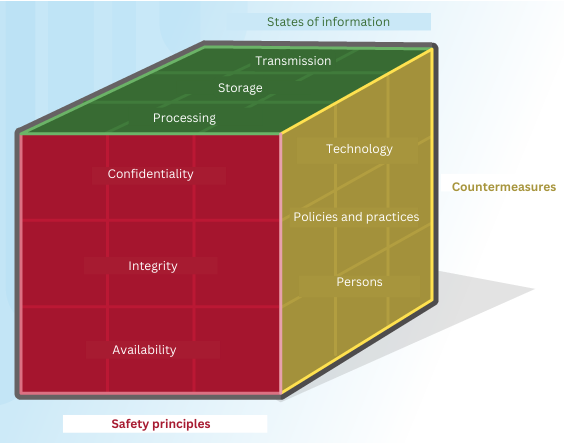
Necesitamos comprender los objetivos centrales de la seguridad, que son proporcionar protección de disponibilidad, integridad y confidencialidad (tríada CID) para activos críticos. En otros framerworks como el ENS, hay que tener en cuenta con el ENS, añade la trazabilidad y la autenticidad (CITAD). Cada activo requerirá distintos niveles de este tipo de protección, como veremos en los siguientes apartados. Todos los controles, mecanismos y salvaguardas de seguridad se implementan para proporcionar uno o más de estos tipos de protección, y todos los riesgos, amenazas y vulnerabilidades se miden por su capacidad potencial de comprometer uno o todos los principios de CID o CITAD.
La protección de disponibilidad garantiza la confiabilidad y el acceso oportuno a los datos y recursos para individuos autorizados. Los dispositivos de red, las computadoras y las aplicaciones deben proporcionar la funcionalidad adecuada para funcionar de manera predecible con un nivel de rendimiento aceptable. Deberían poder recuperarse de las interrupciones de manera segura y rápida para que la productividad no se vea afectada negativamente. Deben existir los mecanismos de protección necesarios para proteger contra amenazas internas y externas que podrían afectar la disponibilidad y productividad de todos los componentes de un sistema.
Como muchas cosas en la vida, asegurar la disponibilidad de los recursos necesarios dentro de una organización parece más fácil de lograr de lo que realmente es. Las redes tienen tantas piezas que deben permanecer en funcionamiento (enrutadores, conmutadores, servidores DNS, servidores DHCP, proxies, firewalls). El software tiene muchos componentes que deben ejecutarse de manera saludable (sistema operativo, aplicaciones, software antimalware). Hay aspectos mentales ambientales que pueden afectar negativamente las operaciones de una organización (incendios, inundaciones, problemas eléctricos), posibles desastres naturales y robos o ataques físicos. Una organización debe comprender completamente su entorno operativo y sus debilidades de disponibilidad para que se puedan implementar las contramedidas adecuadas.
Integridad
La integridad se mantiene cuando se garantiza la exactitud y confiabilidad de la información y los sistemas y se evita cualquier modificación no autorizada. El hardware, el software y los mecanismos de comunicación deben funcionar en conjunto para mantener y procesar los datos correctamente y moverlos a los destinos previstos sin alteraciones inesperadas. Los sistemas y la red deben protegerse de interferencias y contaminación externas.
Los entornos que aplican y brindan este atributo de seguridad garantizan que los atacantes o los errores de los usuarios no comprometan la integridad de los sistemas o los datos. Cuando un atacante inserta un virus, una bomba lógica o una puerta trasera en un sistema, la integridad del sistema se ve comprometida. Esto, a su vez, puede dañar la integridad de la información contenida en el sistema mediante la corrupción, la modificación maliciosa o el reemplazo de datos con datos incorrectos. Controles de acceso estrictos, detección de intrusos y hashing pueden combatir estas amenazas.
Los usuarios suelen afectar un sistema o la integridad de sus datos por error (aunque los usuarios internos también pueden cometer actos maliciosos). Por ejemplo, los usuarios con un disco duro lleno pueden eliminar inadvertidamente los archivos de configuración bajo la suposición errónea de que eliminar un archivo por ejemplo de la carpeta Windows. O, por ejemplo, un usuario puede insertar valores incorrectos en una aplicación de procesamiento de datos que termina cobrando al cliente 2000€ en lugar de 200€. La modificación incorrecta de los datos guardados en las bases de datos es otra forma común en que los usuarios pueden corromper los datos accidentalmente, un error que puede tener efectos duraderos.
La seguridad debe optimizar las capacidades de los usuarios y brindarles solo ciertas opciones y funcionalidades, por lo que los errores se vuelven menos comunes y menos devastadores. Los archivos críticos para el sistema deben estar restringidos para que los usuarios no puedan verlos ni acceder a ellos. Las aplicaciones deben proporcionar mecanismos que verifiquen valores de entrada válidos y razonables. Las bases de datos deben permitir que solo las personas autorizadas modifiquen los datos, y los datos en tránsito deben protegerse mediante encriptación u otros mecanismos.
Confidencialidad
La confidencialidad garantiza que se aplique el nivel necesario de secreto en cada cruce de datos procesamiento y evita la divulgación no autorizada. Este nivel de confidencialidad debe prevalecer mientras los datos residen en sistemas y dispositivos dentro de la red, a medida que se transmiten y una vez que llegan a su destino.
Los atacantes pueden frustrar los mecanismos de confidencialidad mediante la supervisión de la red, la navegación por los hombros, el robo de archivos de contraseñas, la ruptura de esquemas de cifrado y la ingeniería social. La ingeniería social es cuando una persona engaña a otra para que comparta información confidencial, por ejemplo, haciéndose pasar por alguien autorizado para tener acceso a esa información. La ingeniería social puede tomar muchas formas. Se puede utilizar cualquier medio de comunicación uno a uno para realizar ataques de ingeniería social.
Los usuarios pueden divulgar información confidencial de manera intencional o accidental al no cifrarla antes enviándolo a otra persona, siendo víctima de un ataque de ingeniería social, compartiendo los secretos comerciales de una empresa o no teniendo especial cuidado para proteger la información confidencial al procesarla .
La confidencialidad se puede proporcionar cifrando los datos a medida que se almacenan y transmiten, haciendo cumplir control de acceso y clasificación de datos, y capacitando al personal en los procedimientos adecuados de protección de datos.
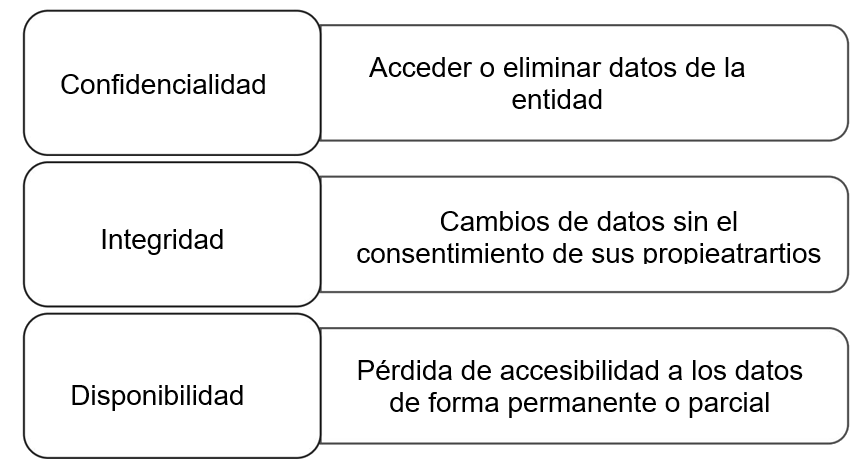
La disponibilidad, la integridad y la confidencialidad son principios fundamentales de la seguridad. Debe comprender su significado, cómo los proporcionan los diferentes mecanismos y cómo su ausencia puede afectar negativamente a una organización.
Seguridad Equilibrada
En realidad,cuando se trata de la seguridad de la información, por lo general solo se hace desde el punto de vista de mantener los secretos en secreto (confidencialidad). Las amenazas a la integridad y la disponibilidad pueden pasarse por alto y solo tratarse después de que se hayan comprometido adecuadamente. Algunos activos tienen un requisito de confidencialidad crítico (secretos comerciales de la empresa), algunos tienen requisitos de integridad críticos (valores de transacciones financieras) y algunos tienen requisitos de disponibilidad críticos (servidores web de comercio electrónico). Muchas personas entienden los conceptos de la tríada CID, pero es posible que no aprecien completamente la complejidad de implementar los controles necesarios para brindar toda la protección que cubren estos conceptos. A continuación se proporciona una breve lista de algunos de estos controles y cómo se asignan a los componentes de la tríada CID:
Disponibilidad
Conjunto redundante de discos económicos (RAID)
Agrupación en clústeres
Balanceo de carga
Datos y líneas eléctricas redundantes
Copias de seguridad de datos y software
Rotura de disco
Integridad
Hashing (datos integridad)
Gestión de la configuración (integridad del sistema)
Control de cambios (integridad del proceso)
Control de acceso (físico y técnico)
Firma digital de software
Confidencialidad
Cifrado de datos en reposo (disco completo, cifrado de base de datos)
Cifrado de datos en tránsito (IPSec, SSL, PPTP, SSH)
Control de acceso (físico y técnico)
Términos clave
Disponibilidad El acceso confiable y oportuno a los datos y recursos es proporcionado a las personas autorizadas.
Integridad Se proporciona precisión y confiabilidad de la información y los sistemas y se evita cualquier modificación no autorizada.
Confidencialidad El nivel necesario de secreto se hace cumplir y no está autorizado se impide la divulgación.
Definiciones de seguridad
Las palabras “vulnerabilidad”, “amenaza”, “riesgo” y “exposición” a menudo se intercambian, aunque tienen significados diferentes. Es importante comprender la definición de cada palabra y las relaciones entre los conceptos que representan, ya que es fundamental a la hora de definir un plan de riesgos.
Una vulnerabilidad es la falta de una contramedida o una debilidad en una contramedida que está en su lugar. Puede ser una debilidad humana, de software, de hardware o de procedimiento que se puede explotar. Una vulnerabilidad puede ser un servicio que se ejecuta en un servidor, aplicaciones o sistemas operativos sin parches, un punto de acceso inalámbrico sin restricciones, un puerto abierto en un firewall, seguridad física laxa que permite que cualquier persona ingrese a una sala de servidores o administración de contraseñas no aplicada en servidores y estaciones de trabajo. .
Una amenaza es cualquier peligro potencial asociado con la explotación de una capacidad de vulnerabilidad. La amenaza es que alguien, o algo, identifique una vulnerabilidad específica y la use contra la empresa o el individuo. La entidad que se aprovecha de una vulnerabilidad se denomina agente de amenaza. Un agente amenazante podría ser un intruso que acceda a la red a través de un puerto en el firewall, un proceso que acceda a los datos de una manera que viole la política de seguridad, un tornado que destruya una instalación o un empleado que cometa un error no intencional que podría exponer información confidencial. .
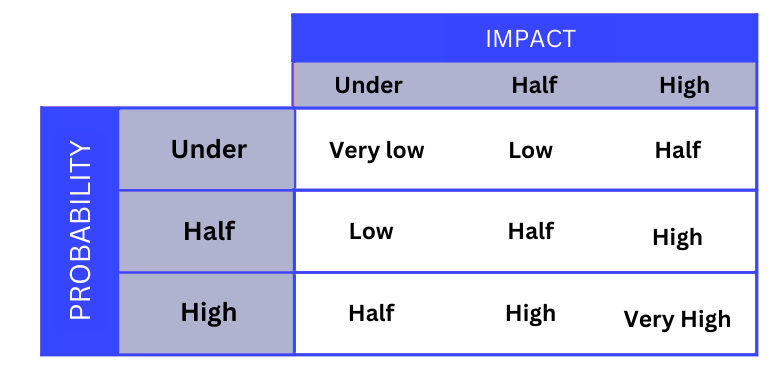
Un riesgo es la probabilidad de que un agente amenazante explote una vulnerabilidad y de que tenga un impacto en el negocio correspondiente. En las siguientes imágenes se puede entender como evaluar la probabilidad e impacto de una amenaza.
Si un firewall tiene varios puertos abiertos, existe una mayor probabilidad de que un intruso use uno para acceder a la red de forma no autorizada.
Si los usuarios no están informados sobre los procesos y procedimientos, existe una mayor probabilidad de que un empleado cometa un error involuntario que pueda destruir los datos. Si no se implementa un sistema de detección de intrusos (IDS) en una red, existe una mayor probabilidad de que un ataque pase desapercibido hasta que sea demasiado tarde.
El riesgo vincula la vulnerabilidad, la amenaza y la probabilidad de explotación con el impacto empresarial resultante.
Una exposición es una instancia de estar expuesto a pérdidas. Una vulnerabilidad expone una organización a posibles daños. Si la administración de contraseñas es laxa y las reglas de contraseñas no se aplican, la empresa está expuesta a la posibilidad de que las contraseñas de los usuarios se capturen y utilicen de manera no autorizada.
Si una empresa no hace inspeccionar su cableado y no implementa medidas proactivas de prevención de incendios, se expone a incendios potencialmente devastadores.
Se implementa un control o contramedida para mitigar (reducir) el riesgo potencial. A la contramedida puede ser una configuración de software, un dispositivo de hardware o un proceso que elimine una vulnerabilidad o que reduzca la probabilidad de que un agente de amenazas pueda explotar una vulnerabilidad.
Los ejemplos de contramedidas incluyen administración de contraseñas sólidas, firewalls, un guardia de seguridad, mecanismos de control de acceso, encriptación y capacitación en seguridad.
Si una empresa tiene un software antimalware pero no mantiene las firmas actualizadas, se trata de una vulnerabilidad. La empresa es vulnerable a los ataques de malware. La amenaza es que aparezca un virus en el entorno e interrumpa la productividad. La probabilidad de que un virus aparezca en el medio ambiente y cause daños y el daño potencial resultante es el riesgo. Si un virus se infiltra en el entorno de la empresa, se ha explotado una vulnerabilidad y la empresa está expuesta a pérdidas. Las contramedidas en esta situación son actualizar las firmas e instalar el software antimalware en todas los ordenadores. Las relaciones entre riesgos, vulnerabilidades, amenazas y contramedidas en la imagen anterior.
La aplicación de la contramedida correcta puede eliminar la vulnerabilidad y la exposición y, por lo tanto, reduce el riesgo. La empresa no puede eliminar el agente amenazante, pero puede protegerse y evitar que este agente amenazante aproveche las vulnerabilidades del entorno.
Mucha gente pasa por alto estos términos básicos con la idea de que no son tan importantes como las cosas más atractivas en la seguridad de la información. Pero encontrará que, a menos que un equipo de seguridad tenga un lenguaje acordado, la confusión se apoderará rápidamente. Estos términos abarcan los conceptos básicos de seguridad y, si se confunden de alguna manera, entonces las actividades que se implementan para hacer cumplir la seguridad se confunden comúnmente.
Tipos de control
Hasta aquí hemos cubierto los objetivos de seguridad (disponibilidad, integridad, confidencialidad) y la terminología utilizada en la industria de la seguridad (vulnerabilidad, amenaza, riesgo, control). Estos son componentes fundamentales que deben entenderse si la seguridad va a tener lugar de manera organizada. El siguiente problema fundamental que abordaremos son los tipos de control que se pueden implementar y su funcionalidad asociada.
Los controles se implementan para reducir el riesgo que enfrenta una organización, y vienen en tres sabores principales: administrativo, técnico y físico.
Los controles administrativos se conocen comúnmente como “controles blandos” porque están más orientados a la gestión. Ejemplos de controles administrativos son la documentación de seguridad, la gestión de riesgos, la seguridad del personal y la capacitación.
Los controles técnicos (también llamados controles lógicos) son componentes de software o hardware, como en firewalls, IDS, encriptación, identificación y mecanismos de autenticación.
Y los controles físicos son elementos que se implementan para proteger las instalaciones, el personal y los recursos. Ejemplos de controles físicos son los guardias de seguridad, las cerraduras, las cercas y la iluminación.
Estos tipos de control deben implementarse para brindar una defensa en profundidad, que es el uso coordinado de múltiples controles de seguridad en un enfoque en capas, como se muestra la siguiente imagen.
Un sistema de defensa de múltiples capas minimiza la probabilidad de penetración y compromiso exitosos porque un atacante tendría que atravesar varios tipos diferentes de mecanismos de protección antes de obtener acceso a los activos críticos. Por ejemplo, la empresa A puede tener los siguientes controles físicos que funcionan en un modelo en capas:
Muro
Barrera
Puertas exteriores
Videovigilancia
Guardia de seguridad
Molino de acceso
Puertas internas cerradas
Sala de servidores cerrada
Entonces, las diferentes categorías de controles que se pueden usar son administrativos, técnicos, y físico. Pero, ¿qué hacen realmente estos controles por nosotros? Necesitamos comprender las diferentes funcionalidades que cada tipo de control puede proporcionarnos en nuestra búsqueda para proteger nuestros entornos.
Las diferentes funcionalidades de los controles de seguridad son preventivas, detectivas, correctivas, disuasorias, recuperatorias y compensatorias. Al tener una mejor comprensión de las diferentes funcionalidades de control, podrá tomar decisiones más informadas sobre qué controles se utilizarán mejor en situaciones específicas. Las seis funcionalidades de control diferentes son las siguientes:
Disuasión Pretende disuadir a un atacante potencial
Preventivo Destinado a evitar que ocurra un incidente
Correctivo Repara componentes o sistemas después de que ha ocurrido un incidente
Recuperación Destinado a devolver el medio ambiente a las operaciones regulares
Detective Ayuda a identificar las actividades de un incidente y potencialmente un intruso
Controles de compensación que proporcionan una medida alternativa de control
Una vez que comprenda completamente lo que hacen los diferentes controles, puede usarlos en las ubicaciones correctas para riesgos específicos, o simplemente puede colocarlos donde se vean más bonitos.
Al mirar una estructura de seguridad de un entorno, es más productivo usar un modelo preventivo y luego utilizar mecanismos de detección, recuperación y corrección para ayudar a respaldar este modelo, de forma que se puede personalizar a las necesidades de cada organización.
Lo que se pretende con estas técnicas es básicamente, detener cualquier problema antes de que comience, pero debe poder reaccionar rápidamente y combatir el problema si lo encuentra. No es factible prevenirlo todo; por lo tanto, lo que no puede prevenir, debe poder detectarlo rápidamente. Es por eso que los controles preventivos y de detección siempre deben implementarse juntos y deben complementarse entre sí. Para llevar este concepto más allá: lo que no puede prevenir, debe poder detectarlo, y si detecta algo, significa que no pudo prevenirlo y, por lo tanto, debe tomar medidas correctivas para asegurarse de que realmente es prevenido la próxima vez. Por lo tanto, los tres tipos trabajan juntos: preventivo, detectivo y correctivo.
A modo de ejemplo, “Un cortafuegos es un control preventivo, pero si un atacante supiera que está instalado, podría ser un elemento disuasorio”. Detengámonos aquí. No hagas esto más difícil de lo que tiene que ser. Cuando intente asignar el requisito de funcionalidad a un control, piense en la razón principal por la que se implementaría el control. Un cortafuegos trata de evitar que suceda algo malo, por lo que es un control preventivo.
Los registros de auditoría se realizan después de que se produjo un evento, por lo que es detectable. Se desarrolla un sistema de respaldo de datos para que los datos puedan ser recuperados; por lo tanto, este es un control de recuperación. Las imágenes de computadora se crean para que, si el software se corrompe, se puedan cargar; por lo tanto, este es un control correctivo.
Un tipo de control con el que algunas personas luchan es un control de compensación. Miremos a algunos ejemplos de controles de compensación para explicar mejor su función. Si su empresa necesitaba implementar una fuerte seguridad física, podría sugerirle a la gerencia que se empleen guardias de seguridad. Pero después de calcular todos los costos de los guardias de seguridad, su empresa podría decidir usar un control de compensación (alternativo) que brinde una protección similar pero que sea más asequible, como en una cerca. En otro ejemplo, supongamos que es un administrador de seguridad y está a cargo del mantenimiento de los firewalls de la empresa de comunicaciones.
La gerencia le dice que cierto protocolo que sabe que es vulnerable a la explotación debe permitirse a través del firewall por razones comerciales. La red debe estar protegida por un control de compensación (alternativo) perteneciente a este protocolo, que puede configurar un servidor proxy para ese tipo de tráfico específico para garantizar que se inspeccione y controle correctamente.
Por lo tanto, un control de compensación es solo un control alternativo que brinda una protección similar a la del control original, pero debe usarse porque es más asequible o permite la funcionalidad comercial específicamente requerida.
Existen varios tipos de controles de seguridad y todos deben trabajar juntos. La complejidad de los controles y del entorno en el que se encuentran pueden hacer que los controles se contradigan o dejen brechas en la seguridad. Esto puede introducir agujeros inesperados en la protección de la empresa que los implementadores no entienden completamente. Una empresa puede tener controles de acceso técnico muy estrictos y todos los controles administrativos necesarios, pero si a cualquier persona se le permite acceder físicamente a cualquier sistema en la instalación, entonces existen claros peligros de seguridad en el entorno. Juntos, estos controles deben funcionar en armonía para proporcionar un entorno saludable, seguro y productivo.
Marcos de seguridad
Hasta el momento este punto sabemos lo que necesitamos lograr (disponibilidad, integridad, confidencialidad) y conocemos las herramientas que podemos utilizar (controles administrativos, técnicos, físicos) y sabemos cómo hablar sobre este tema (vulnerabilidad, amenaza, riesgo, control). Antes de pasar a cómo desarrollar un programa de seguridad para toda la organización, primero exploremos lo que no se debe hacer, lo que se conoce como seguridad a través de la oscuridad. El concepto de seguridad a través de la oscuridad supone que tus enemigos no son tan inteligentes como tú y que no pueden resolver algo que crees que es muy complicado. Un ejemplo no técnico de seguridad a través de la oscuridad es la vieja práctica de poner una llave de repuesto debajo de un felpudo en caso de que no pueda entrar a la casa. Asumes que nadie sabe acerca de la llave de repuesto y, mientras no lo hagan, se puede considerar segura. La vulnerabilidad aquí es que cualquiera podría acceder fácilmente a la casa si tiene acceso a esa llave de repuesto oculta, y el atacante experimentado (en este ejemplo, un ladrón) sabe que existen este tipo de vulnerabilidades y toma las medidas adecuadas para buscarlas. afuera.
En el ámbito técnico, algunos proveedores trabajan bajo la premisa de que dado que el código de su producto está compilado, esto proporciona más protección que los productos basados en código fuente abierto porque nadie puede ver sus instrucciones de programación originales. Pero los atacantes tienen a su disposición una amplia gama de herramientas de ingeniería inversa para reconstruir el código original del producto, y hay otras formas de descubrir cómo explotar el software sin realizar ingeniería inversa, como fuzzing, entradas de validación de datos, etc. El enfoque adecuado de la seguridad es asegurarse de que el software original no contenga fallas, no asumir que poner el código en un formato compilado proporciona el nivel necesario de protección.
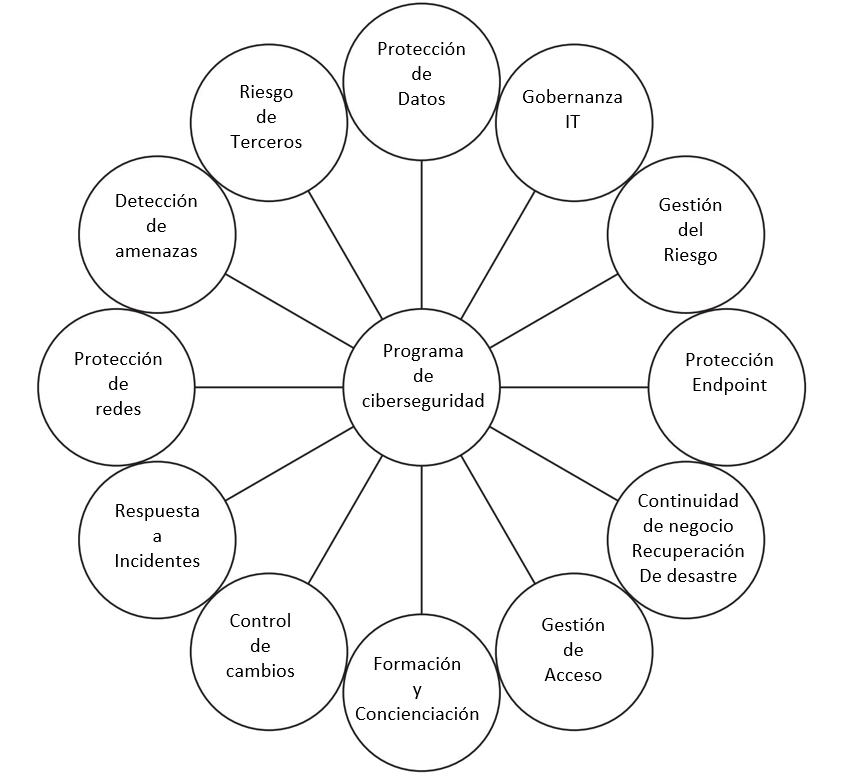
Un programa de seguridad es un marco compuesto por muchas entidades: lógicas, administrativas y mecanismos de protección física, procedimientos, procesos comerciales y personas que trabajan juntas para proporcionar un nivel de protección para un entorno. Cada uno tiene un lugar importante en el marco, y si uno falta o está incompleto, todo el marco puede verse afectado. El programa debería funcionar en capas: una capa proporciona soporte para la capa superior y protección para la capa inferior. Debido a que un programa de seguridad es un marco, las organizaciones pueden conectar diferentes tipos de tecnologías, métodos y procedimientos para lograr el nivel de protección necesario para su entorno.
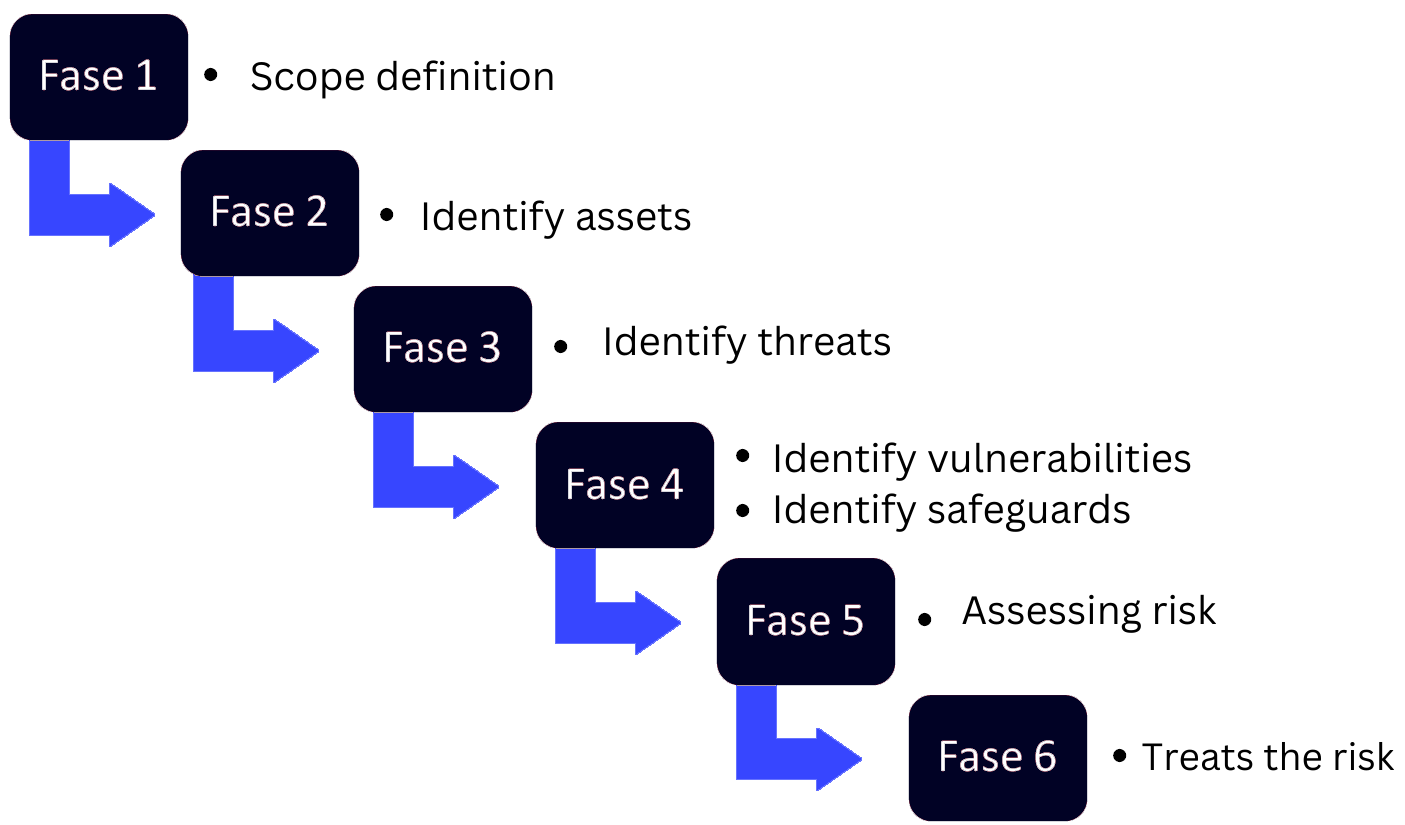
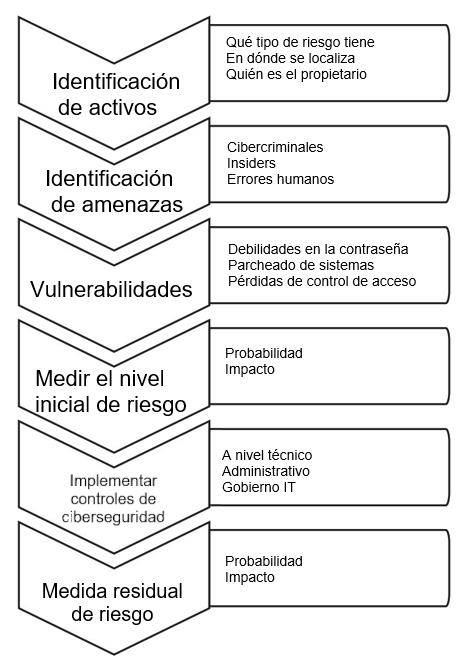
Uno de los procedimientos que estos marcos suelen incluir por hacer es un análisis de riesgos. En el mismo hay que definir alcance al que afecta dicho análisis (todas las sedes, una sola oficina, etc), identificar activos (personal, contratos, nóminas, bases de datos, proveedores, impresoras, dispositivos informáticos, dispositivos de almacenamientos, etc), identificar amenazas (fuegos, cortes de luz, baja de un empleado, red inoperativa, etc), identificar las vulnerabilidades y qué salvaguardas se aplican, evaluar el riesgo y tratarlo. Se puede resumir en la siguiente captura.
Conclusión
Tal como hemos visto, no podemos hablar de riesgos IT, sin mencionar la triada CID, y sin hacer mención a una serie de controles. Los controles a su vez fueron compilados en marcos normativos como el ENS, ISO 27001, Cobit, NIST, SOC, Contoles CIS. Cada uno tomó una serie de controles, los categorizó y creo su propia normativa, por ejemplo PCI-DSS para el sector financiero, HIPPA para el sector de salud en los Estados Unidos, o a nivel nacional Esquema Nacional de Seguridad para Administración Pública.
Un marco de gestión de riesgos de IT es un sistema de normas, directrices y prácticas recomendadas que ayudan a gestionar los riesgos de ciberseguridad y mantener las regulaciones del sector. Los marcos presentan un método estandarizado y bien documentado para:
Realizar evaluaciones de riesgos que comprueben las prioridades de tu empresa e identifiquen las lagunas en los controles de seguridad.
Realizar un análisis de riesgos sobre las lagunas en los control existentes.
Priorizar las acciones y las futuras inversiones en seguridad basándose en el análisis de riesgos.
Ejecutar esas estrategias mediante la aplicación de una serie de controles de seguridad y prácticas recomendadas.
Medir y puntuar la madurez del programa de seguridad a lo largo del proceso.
La persona responsable de la ejecución del marco de gestión de riesgos de seguridad informática varía de una empresa a otra. Las organizaciones más grandes suelen tener un Chief Information Officer o un Director de Riesgos para gestionar el proceso y trabajar con su equipo de TI para ejecutarlo. Las organizaciones más pequeñas pueden tener a un responsable de TI que supervise el proyecto.
Independientemente del tamaño de la empresa, es esencial que varias partes interesadas participen en la creación del marco. Por ejemplo, el consejo de administración y los directores de la empresa tendrán un papel crucial:
Identificar qué riesgos pueden exponer a la organización
Establecer la formación continua de los empleados
Gestionar el presupuesto necesario para mitigar los riesgos actuales y futuros
¿Por qué necesita mi empresa un marco de seguridad?
Los marcos de ciberseguridad se han convertido en un elemento básico para las empresas que quieren cumplir con la normativa de ciberseguridad estatal, industrial o internacional. Pero más allá de la ley, los marcos de seguridad ayudan a las organizaciones a priorizar las acciones de una manera flexible, repetible y rentable para proteger su negocio.
Un marco de gestión de riesgos de IT proporcionará cinco beneficios principales a tu organización:
-Ahorro de tiempo: Un marco de trabajo te permite mapear cuál es tu estatus de ciberseguridad. A partir de ahí, puedes identificar las lagunas que guiarán una conversación con las partes involucradas de la empresa, sabiendo dónde estás y dónde deberías estar.
Aplicable universalmente: La mayor parte del contenido incluido en un marco de gestión de riesgos de seguridad de TI se aplica universalmente. Por ejemplo, independientemente de tu sector o ubicación, tu empresa probablemente maneja datos sensibles. Dado que casi todas las empresas comparten este elemento, esto significa que puedes beneficiarte de un marco que comparte acciones específicas sobre la gestión de datos sensibles.
Aprobado por la comunidad: No tienes que empezar de cero cuando se trata de tu marco de gestión de riesgos informáticos. Los marcos más fiables y adoptados son desarrollados mediante relaciones de colaboración entre múltiples personas con experiencia en diversos sectores. Este conocimiento colectivo de diferentes áreas garantiza que, sea cual sea el marco que elijas, ya ha sido probado y su éxito demostrado.
Proporciona consistencia: Los marcos de gestión de riesgos de TI proporcionan coherencia a la hora de abordar las necesidades de seguridad en la empresa. Sin un marco, las partes interesadas en la ciberseguridad la empresa pueden actuar de formas diferentes. Esto no sólo causa ineficacia, sino que también te pone en riesgo de cometer errores y crear lagunas imprevistas en la ejecución.
Simplifica la seguridad: Un marco publicado facilita la explicación de cómo la seguridad gestiona las amenazas y los riesgos, incluso a las personas dentro de la empresa menos versadas en seguridad. La ciberseguridad afecta a todo el mundo dentro de tu organización, por lo que tener un lenguaje común es útil.
Introducción al control de riesgos.
Todas las organizaciones se enfrentan a una serie de riesgos a la hora de desarrollar su actividad y, por tanto, a la hora de utilizar sus servicios. El regulador y las agencias de valoración están empezando a tener en cuenta el análisis de los procesos de gestión del riesgo de las empresas a la hora de evaluar la salud de las mismas.
Hoy, es indudable que una correcta gestión del riesgo supone una ventaja competitiva respecto a la competencia, especialmente en la coyuntura económica actual donde la confianza es uno de los aspectos más valorados entre los clientes de una entidad. Contar con procesos para mitigar riesgos no hace sino aumentar esta confianza.
En el campo de la gestión de los servicios de TI, los riesgos han de ser gestionados para asegurar la disponibilidad de los sistemas y evitar la pérdida de datos confidenciales entre otros contratiempos.
Contar con una estrategia para la gestión de los riesgos se vuelve esencial en el desarrollo de la estrategia de gestión de servicios. De hecho, ITIL lo incluye como parte del diseño del servicio, ya que, desde el momento que se concibe éste, es necesario plantear los diferentes riesgos a los que se enfrentará el servicio y las alternativas para minimizar el efecto negativo de los mismos. Por tanto, es durante la definición de nuevo servicio donde han de considerarse los procesos necesarios para gestionar el riesgo.
En la actualidad, la gestión del riesgo se lleva a cabo bajo un enfoque más holístico y continuista, adoptando lo que se ha llamado Enterprise Risk Management (ERM), gestión del riesgo integral. El concepto de ERM aparece en 2003, cuando la Casualty Actuarial Society (CAS) lo define como una disciplina a través de la cual las organizaciones de cualquier industria monitorizan, controlan, explotan y financian los riesgos provenientes de cualquier fuente con el propósito de aumentar, en el corto y largo plazo, el valor ofrecido a los stakeholders. Este enfoque incluye metodologías y procesos utilizados por las organizaciones de todas las industrias para gestionar los riesgos y optimizar las oportunidades que les permita alcanzar sus objetivos.
La gestión del riesgo comprende las fases de identificación, seguimiento y priorización, según se define en la norma ISO 31000. Para contrarrestarlo, es necesario monitorizar y controlar la probabilidad y el impacto de que se dé la causa desencadenante del riesgo.
La norma ISO 31000.
Aunque los riesgos son de muy diversa índole, dependiendo del ámbito empresarial de la organización que los enfrenta, la norma ISO 31000 propone unas pautas estandarizadas para intentar gestionarlo. Fue publicada como estándar el 13 de noviembre de 2009, pretendiendo ser aplicable y adaptable para cualquier tipo de empresa pública o privada, asociación o incluso para la actividad laboral de empresas constituidas por autónomos. Además de esta norma, se publicó la llamada guía 73, que busca unificar el vocabulario utilizado en los procesos de gestión de riesgos.
Esta norma se divide en tres grandes bloques:
Principios para la gestión del riesgo:
Crear valor para contribuir a la consecución de los objetivos de la empresa.
Integración con los procesos de la organización.
Ayudar a la toma de decisiones al aportar información sobre los posibles escenarios.
Minimizar la incertidumbre.
Función sistemática, estructurada y adecuada para contribuir a la obtención de resultados fiables.
Basada en la mejor información disponible en cada momento.
Alineada con el contexto interno y externo de la propia empresa.
Debe contar con los factores humanos y culturales de la organización.
Transparente a la hora de mostrar la información y participación de todos los interesados en la gestión del mismo.
Dinámica, iterativa y sensible al cambio.
Contribuir a la mejora continua de la empresa.
Estructura de soporte:
La gestión del riesgo debe contar con el apoyo de la alta dirección. Se desarrolla iterativamente en ciclos que pretenden diseñar la mejor estructura de soporte, implantar esta estructura de la manera más eficiente para gestionar el riesgo y monitorizar las actividades de gestión para mejorar continuamente la estructura propuesta. Proceso de gestión de riesgos: la gestión de riesgos incluye las etapas de identificar, analizar, evaluar y tratar riesgos. Constantemente, debe existir una comunicación y consulta continua con las diferentes áreas de la organización, así como un seguimiento y revisión.
Sin embargo, esta norma sólo pretende marcar unas directrices, pero no pretende implementar un modelo de gestión del riesgo uniforme entre las diferentes empresas. El diseño e implementación de un plan para la gestión de riesgos y un marco de trabajo para su ejecución necesita considerar las variaciones específicas de cada industria, particularmente sus objetivos, contexto, estructura, operaciones, procesos, proyectos, productos, servicios o activos.
Gestión de riesgos en servicios de TI.
ITIL define el proceso de gestión de riesgos orientándolo a la gestión de los servicios de TI, formando parte del plan de continuidad del servicio (ITSCM). Su objetivo es determinar la probabilidad de un fallo con la configuración actual del servicio, así como la capacidad de soporte necesaria en la organización.
El análisis de los riesgos debe llevarse a cabo durante la fase de diseño del servicio, para identificar los riesgos en los que se puede incurrir debido a la indisponibilidad de los componentes de la infraestructura, y los riesgos, debidos a la pérdida de confidencialidad e integridad por errores en el servicio.
El objetivo de la gestión de los riesgos en un servicio de IT debe ser identificar los activos, las amenazas y las vulnerabilidades que conforman el riesgo, y establecer las contramedidas necesarias.
El riesgo también está definido por el nivel de aceptación de la organización, que puede ser más o menos propensa a mitigar o asumir un determinado nivel de riesgo.
El seguimiento del riesgo se basa generalmente en la probabilidad e impacto de un evento, y las contramedidas son implementadas, si su coste puede ser justificado, para reducir el impacto del evento o para disminuir las probabilidades de que suceda.
Previo a la identificación de los riesgos se debe estudiar el impacto que un mal funcionamiento del servicio puede producir en la organización.
El análisis del impacto (Business Impact Analysis, BIA) identifica:
Los servicios más importantes para la organización y el modo en que pueden afectar al negocio, como una pérdida de ingresos, un aumento de los costes o un daño reputacional.
Cómo el impacto puede elevarse tras la interrupción del servicio y los momentos del día o del año durante los cuales el impacto es mayor.
El personal y las habilidades necesarias para mantener el negocio de manera aceptable.
El tiempo asumible para la recuperación del servicio.
La prioridad a la hora de recuperar diferentes servicios afectados.
El análisis de los riesgos y el impacto de los mismos suele representarse gráficamente enfrentando el impacto y el tiempo de interrupción del servicio.
La gestión de los riesgos debe realizarse siguiendo metodologías estándar, como la metodología MoR (Management of Risk) explicada en los volúmenes de ITIL. Los procesos incluidos en esta gestión del riesgo incluyen:
Identificación: de las amenazas y oportunidades de una actividad que puede impactar en la consecución de sus objetivos.
Evaluación: entender los efectos de red de las amenazas y oportunidades identificadas para una actividad.
Planear: preparar una respuesta específica que reduzca las amenazas y maximice las oportunidades.
Implementar: acciones para la gestión de los riesgos, monitorizar su efectividad y tomar acciones correctivas cuando las respuestas no cumplen con las expectativas.
Uno de los entregables que debe aportar un plan para la gestión de riesgos debe ser un perfil de riesgos que permita entender fácilmente el impacto de cada una de las posibles situaciones a las que se enfrenta un servicio.
Para este perfil, se puede construir una matriz donde enfrentar la posibilidad de que se dé un evento con el impacto del mismo sobre el negocio. De este modo, es posible priorizar las medidas que puedan paliar aquellos riesgos con alta probabilidad de suceder y con un alto impacto sobre el negocio.
Ejemplos típicos de medidas que pueden ser adoptadas para reducir el riesgo son:
Aumento de la resiliencia del sistema.
Subcontratar la prestación de servicios a más de un proveedor.
Equipos en redes aisladas para ser utilizados en caso de fallo en las redes principales.
En la gestión de riesgos, es necesario establecer, de común acuerdo con el Service Owner, ya sea para un servicio, software, hardware, tanto RTO como el RPO (Recovery Time Objective y Recovery Point Objective).
El RTO es el tiempo que pasará una infraestructura antes de estar disponible nuevamente. Para reducir el RTO, se requiere que la infraestructura (tecnológica, logística, física) esté disponible en el menor tiempo posible pasado el evento de interrupción.
El RPO marca cuando la infraestructura, ya operativa nuevamente, comenzará a hacerse evidente. Básicamente, RPO indica lo que la organización está dispuesta a perder en cantidad de datos. Para reducir un RPO es necesario aumentar el sincronismo de réplica de datos.
Metodología Magerit.
Magerit es la metodología de análisis y gestión de riesgos elaborada por el Consejo Superior de Administración Electrónica. Su objetivo es estudiar los riesgos propios de un sistema de información y su entorno, concienciando a los responsables de las organizaciones de la existencia de los mismos y la necesidad de gestionarlos, y ayudando a descubrir y planificar las respuestas necesarias para controlar estos riesgos.
Para ello, evalúa el impacto que una violación en la seguridad tiene para la organización, señala los riesgos existentes, las amenazas y la vulnerabilidad del sistema frente a las mismas. El resultado son recomendaciones sobre las medidas adecuadas para conocer, prevenir, impedir, reducir o controlar estos riesgos que han sido identificados.
Magerit identifica dos actividades principales:
Análisis de riesgos:
Permite determinar cuáles son los activos de la organización, cuáles son las amenazas y, finalmente, las contramedidas para mitigarlas. Con ello, se obtiene el impacto (lo que podría pasar) y el riesgo (lo que probablemente pase).
Dentro de este esquema, los activos son los recursos del sistema de información o asociados al mismo, como servicios, aplicaciones informáticas, equipos informáticos, soportes de información, equipamiento auxiliar, redes de comunicaciones, instalaciones y personas.
Los activos han de valorarse. No hay que confundir valor y coste. El activo tendrá valor si es utilizado para algo, si no puede prescindirse de él sin más. En general, se habla de un valor propio, intrínseco del activo, y de un valor acumulado que tiene en cuenta el valor de los activos que dependen de otro.
Para valorar un activo, cabe analizar diferentes dimensiones del mismo: autenticidad (daño ocasionado por no conocer quién accede al activo), confidencialidad (daño provocado si se desvela información gestionada por el activo), integridad (daño producido por contar con datos corruptos) y disponibilidad (daño causado por no poder utilizar un activo).
En este modelo, las amenazas representan todo aquello que puede ocurrir y afectar a un activo. Para valorarlas, es necesario determinar la degradación, la intensidad con la se perjudica el activo, y la frecuencia, cada cuánto cabe esperar que se dé la amenaza. La degradación suele expresarse como una fracción del valor del activo y la frecuencia se establece como una tasa anual.
La degradación se relaciona directamente con el impacto y la frecuencia con el riesgo. El impacto refleja el daño posible, mientras que el riesgo refleja el daño probable. Las medidas que se tomen para atenuar el riesgo deben ir encaminadas a disminuir la degradación o a disminuir la frecuencia.
Gestión de riesgos:
Permite organizar las medidas defensivas para reducir los riesgos a los que se enfrenta la organización. El riesgo se debe reducir hasta el nivel asumido por la dirección de la empresa. Se ha de llegar a unos niveles de impacto y riesgo residual o despreciable. El hecho de que exista un nivel residual indica que, ciertamente, existe un riesgo, pero el coste de las medidas necesarias para mitigarlo no compensa el valor del activo al que afecta ese riesgo. Las medidas que se toman como respuesta a los riesgos pueden ser:
Técnicas (aplicaciones, equipos y comunicaciones)
Físicas (entorno de trabajo)
Organizacionales (prevención de incidencias)
Políticas de personal (formación permanente)
Es lógico pensar que el coste de estas medidas no debe ser superior al coste de los activos que protegen. EL riesgo cae precipitadamente con pequeñas inversiones, para poco a poco reducirse esta relación entre disminución del riesgo y aumento de la inversión. A partir de un determinado punto, seguir reduciendo mínimamente el riesgo supone un gasto muy alto en medidas. Finalmente, es importante destacar que la decisión sobre los valores residuales no es una decisión técnica sino una decisión de la dirección de la empresa.
Pilar, software de gestión de riesgos.
La gestión de riesgos debe entenderse como una serie de procesos adicionales que forman parte de una organización. Las metodologías permiten estandarizar estos procesos y definir los flujos de información necesarios. Contar con las herramientas tecnológicas que soporten estos procesos de gestión de riesgos y sean capaces de gestionar toda la información necesaria es fundamental para poder implementar con éxito un plan de gestión de riesgos.
La metodología Magerit viene acompañada de la herramienta PILAR, acrónimo de “Procedimiento Informático-Lógico para el Análisis de Riesgos”. PILAR ha sido desarrollado por el Centro Nacional de Inteligencia siguiendo los pasos establecidos por la metodología Magerit.
Incluye los siguientes procesos:
Caracterización de los activos: identificación, clasificación, dependencias y valoración.
Caracterización de las amenazas.
Evaluación de las medidas de mitigación.
Asimismo, incluye catálogos de elementos que permiten homogeneidad en el análisis de los tipos de activo, las diferentes dimensiones de la valoración, los criterios utilizados para la valoración y un catálogo de amenazas.
Cuenta con un motor de cálculo de riesgos y una biblioteca de elementos. La herramienta se encarga de estimar el impacto y el riesgo de los activos presentándolo de manera muy visual para poder realizar análisis sobre el mismo. Los resultados se pueden mostrar como informes RTF, gráficos y tablas. Además, calcula calificaciones de seguridad según estándares de la industria, como la norma UNE-ISO/IEC 17799:2002, de sistemas de gestión de la seguridad. Con todo ello, PILAR es capaz de analizar los riesgos, calcular los riesgos residuales y establecer un plan de mejora para cumplir con la normativa existente.
Conclusiones
Concluyendo, un marco de gestión de riesgos de IT es esencial para proteger la empresa de los riesgos cibernéticos y mejorar su eficacia en la gestión de servicios de TI. Los marcos más fiables son desarrollados mediante colaboración entre expertos en diferentes sectores, garantizando que ya han sido probados y demostrado su éxito.
Sin un marco, las partes interesadas en la ciberseguridad pueden actuar de formas diferentes, causando ineficacia y riesgo de errores y lagunas en la ejecución. Además, contar con una estrategia para la gestión de riesgos es esencial en la estrategia de gestión de servicios. La norma ISO 31000 y la guía 73 proporcionan pautas estandarizadas para la gestión de los riesgos
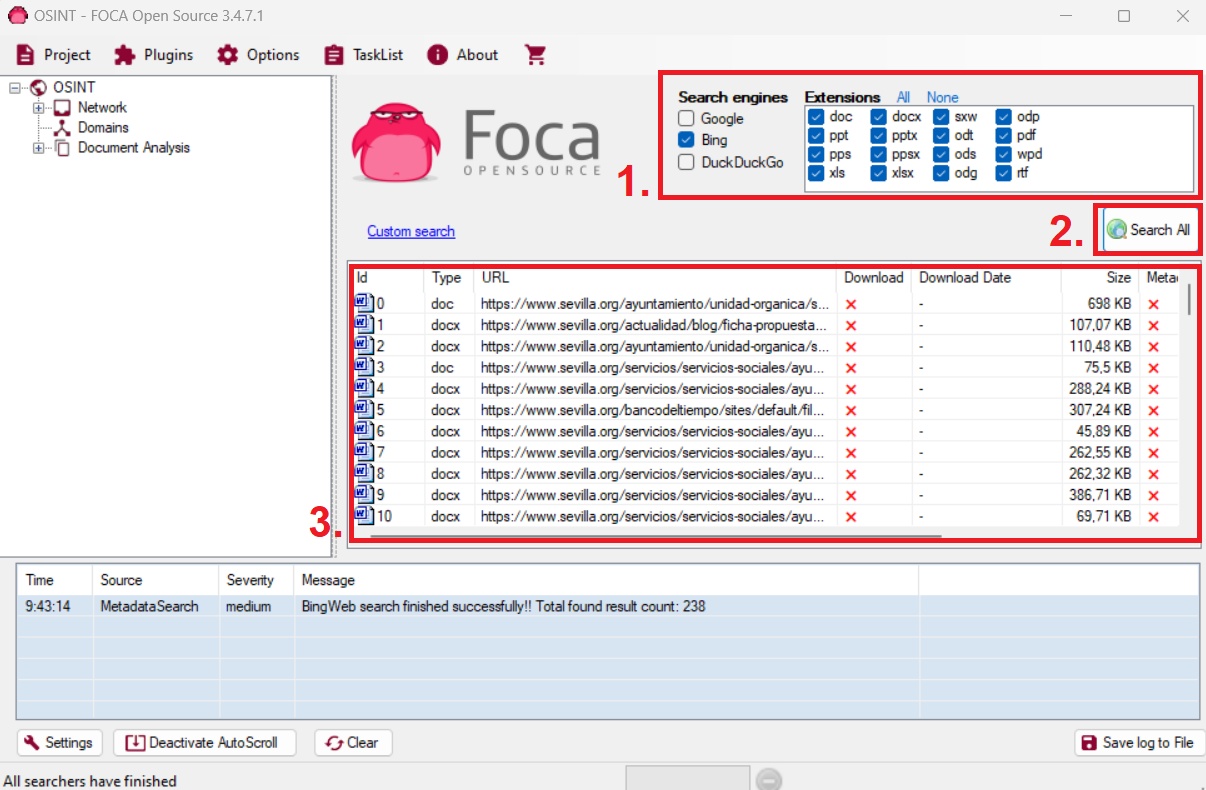
En esta lección se explicará como funcionan tres de las herramientas más conocidas de OSINT, y se verán con ejemplos prácticos los usos que se les puede dar. Estas herramientas son Google Dorking, Shodan y FOCA.
Google Dorking
Google dorking es una técnica que nos permite hacer búsquedas avanzadas en con el motor de búsqueda de Google. Estas búsquedas se realizan mediante una sintaxis avanzada y pueden usarse en plataformas como Bing, Yahoo o DuckDuckGo.
El dorking es una forma de enumeración pasiva con la que puedes encontrar información sensible como documentos privados, credenciales de inicio de sesión, emails o incluso información de cuentas bancarias.
Operadores
Para realizar una búsqueda avanzada usando dorking es necesario conocer los operadores y sus funciones. A continuación se mostrará una tabla con los distintos operadores y veremos algunos ejemplos de uso.td>@gmail.com
Operador
Descripción
Ejemplo
” “
El texto entre comillas dobles debe aparecer tal cual en el resultado.
“hackrocks”
–
Excluye de la búsqueda el término que va después del signo “-”.
-windows
+
Incluye en la búsqueda el término que va después del signo “+”.
hackrocks +windows
Se usa como comodín para indicar que puede tener cualquier valor.
#
Busca un hashtag.
#hacking
@
Busca en redes sociales.
@hackrocks
OR
Devuelve uno de los términos de búsqueda que se usen.
“linux” OR “windows”
|
Realiza la misma función que el operador OR.
“linux” | “windows”
AND
Devuelve todos los términos de búsqueda que se usen.
“linux” AND “windows”
&
Realiza la misma función que el operador AND.
“linux” & “windows”
()
Se utiliza para agrupar operadores.
ordenador (“linux” OR “windows”)
cache:
Muestra la página en caché.
cache:hackrocks.com
inurl:
El término de búsqueda debe estar en la url del resultado.
inurl:login.php
site:
Muestra todos los resultados indexados sobre un sitio web
El término de búsqueda debe estar en el título del resultado.
intitle:login
intext:
El contenido del resultado debe tener el término de búsqueda.
intext:credentials
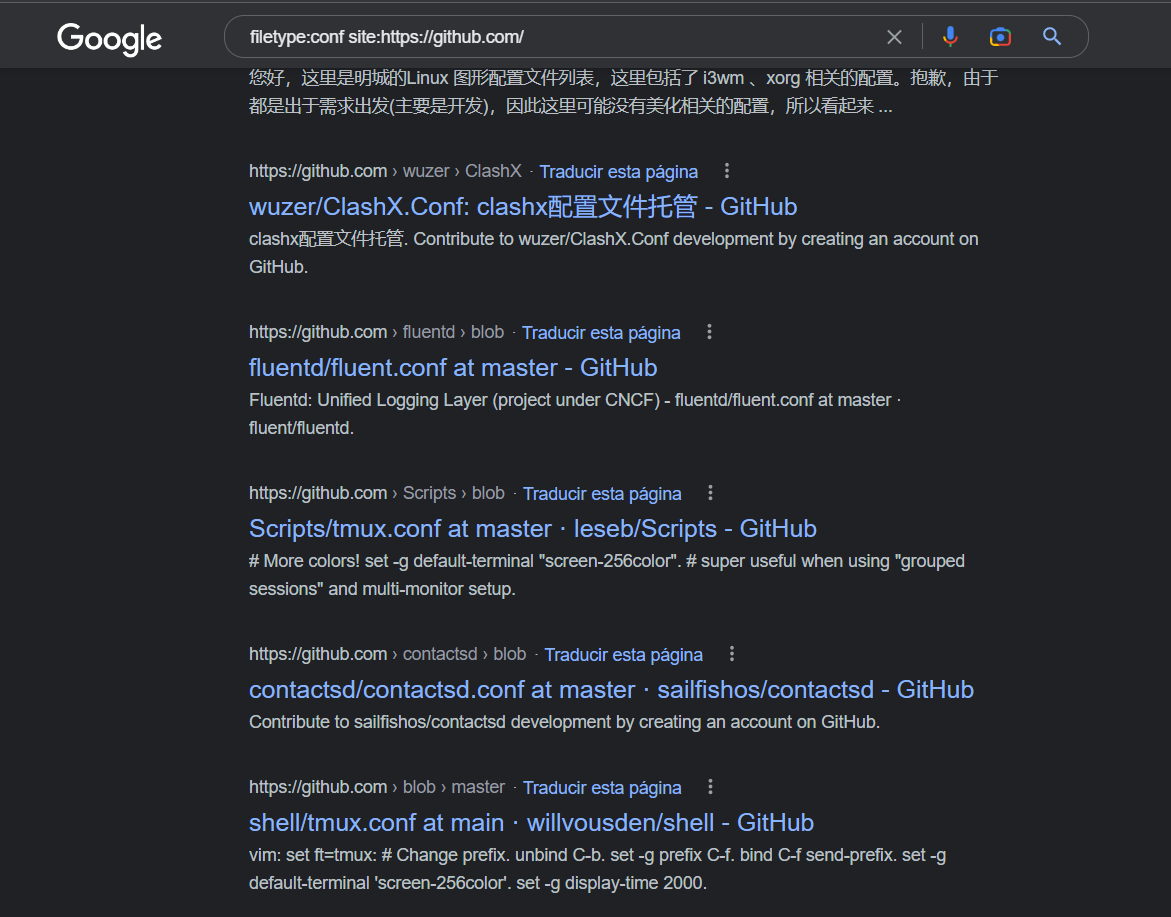
PoC: filetype:
Este operador es muy útil porque puedes usarlo junto a otros como site, para buscar archivos con la extensión que se indique en un sitio web específico. A continuación se muestra un ejemplo de uso en el que se busca un archivo .conf, que puede contener credenciales o información de un servidor, en repositorios de github.
Otro uso puede ser encontrar ficheros de backups de bases de datos o simplemente buscar un pdf con información sensible.
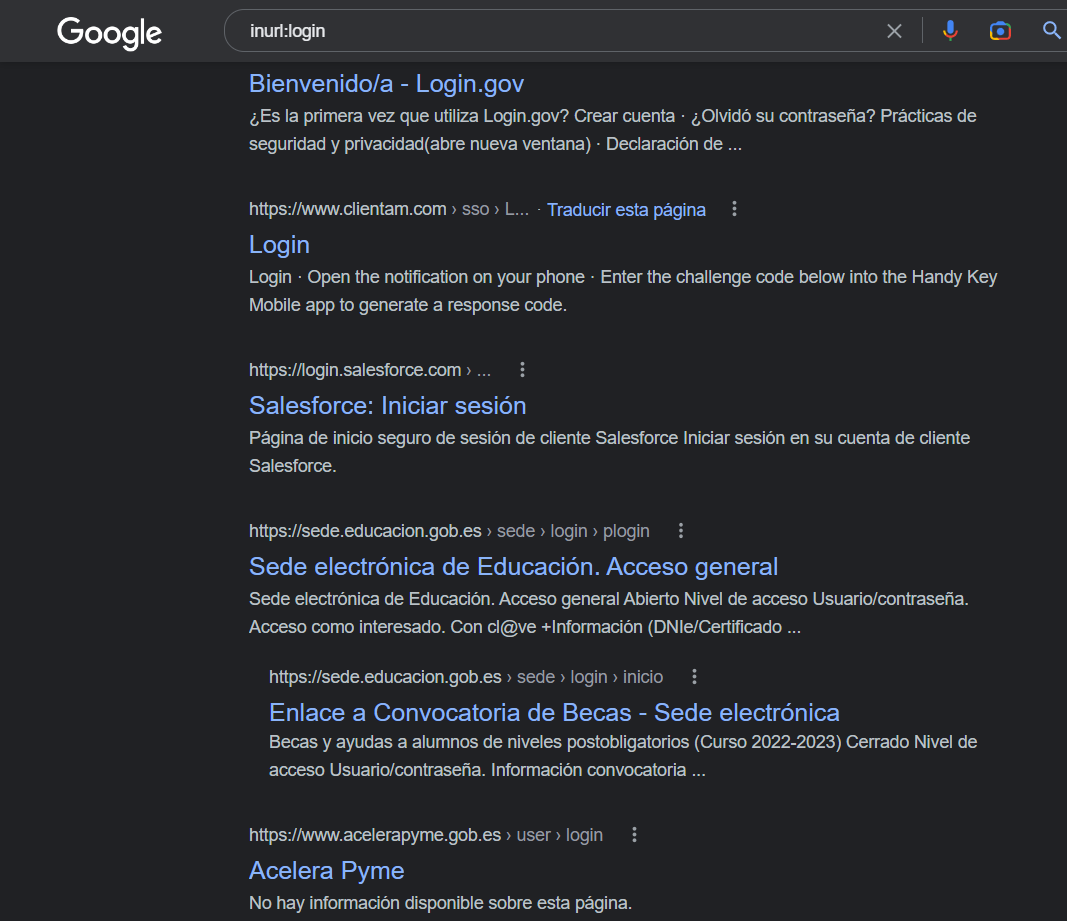
PoC: inurl:
Como se ha indicado en la tabla anterior, este operador sirve para encontrar un resultado que tenga el término de búsqueda indicado en la url y, al igual que en el ejemplo anterior, se puede combinar con otros operadores para obtener resultados mejores. Este operador, al igual que intitle: e intext:, se puede usar con all al principio (allinurl:) si se quiere buscar más de una palabra.
Uno de los muchos casos en los que es útil inurl: es para buscar formularios de login:
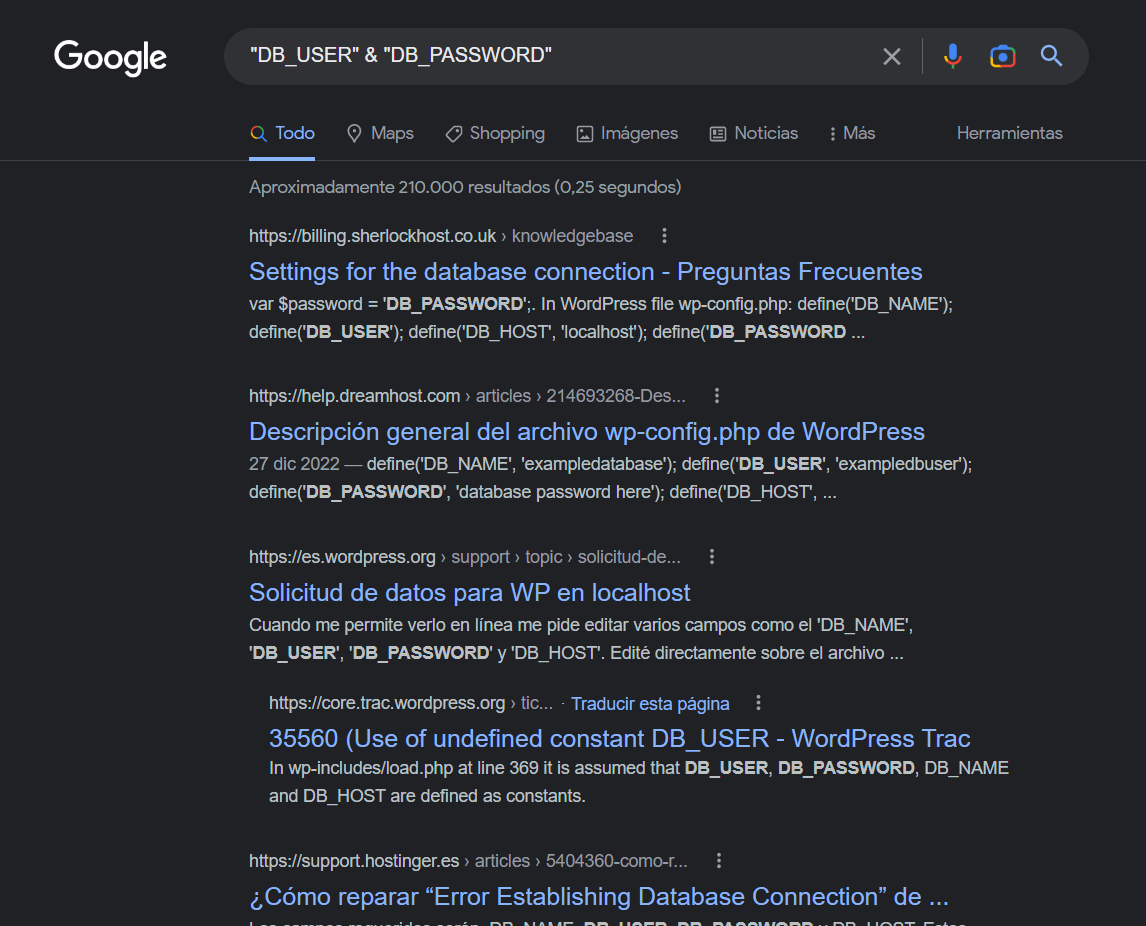
PoC: ” “
Es el operador más básico que hay, pero no por ello el menos útil. El término de búsqueda que se introduzca debe aparecer en el resultado sin ningún cambio. Puede ser útil para buscar información sobre un término muy específico como puede ser el nombre de una persona o de una empresa.
En la siguiente imagen se muestra un ejemplo de como buscar con ” ” y AND un usuario y contraseña de una base de datos.
Shodan
Shodan es un motor de búsqueda que, a diferencia de otros como Google, en vez de buscar sitios web, busca dispositivos conectados a Internet. Es posible crear una cuenta gratis en Shodan, pero tiene varias limitaciones como un número máximo de 50 búsquedas.
Con la ayuda de una amplia variedad de filtros, podemos encontrar una gran cantidad de dispositivos de interés, acompañado de información como direcciones IP, dominios o ubicaciones.
Filtros
La tabla a continuación muestra una lista con algunos de los filtros más útiles de Shodan. Si quieres ver la lista con todos los filtros disponibles puedes hacerlo accediendo al siguiente enlace.
Filtro
Utilidad
Ejemplo
after/before:
Filtra los resultados por fechas.
before:12/11/2022
country:
Filtra los resultados por un código de dos dígitos que identifica a un país.
country:spain
city:
Obtiene resultados de una ciudad.
city:sevilla
geo:
Busca por latitud/longitud.
geo:37.38283,-5.97317
hostname:
Busca el nombre de un host o dominio específico.
hostname:hackrocks.com
net:
Busca resultados en un rango de IP o en un segmento de red.
net:199.4.1.0/24
os:
Filtra por sistema operativo.
os:ubuntu
port:
Permite filtrar por un número de puerto.
port:80
Conociendo los filtros que nos ofrece Shodan, podemos utilizarlos para enumerar dispositivos que pueden entrar en nuestro objetivo y son potencialmente vulnerables. En el siguiente apartado veremos una prueba de concepto para conocer como usar Shodan.
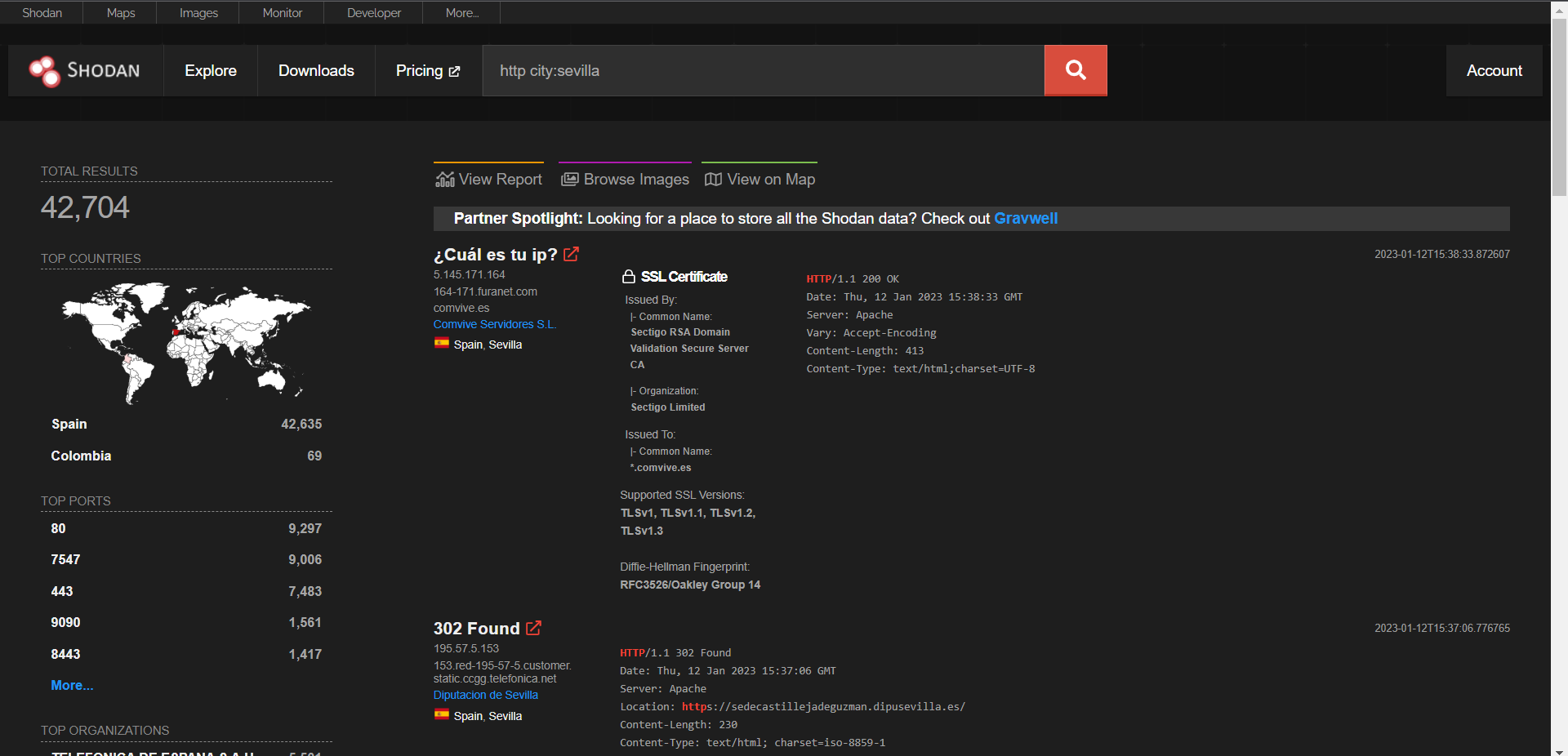
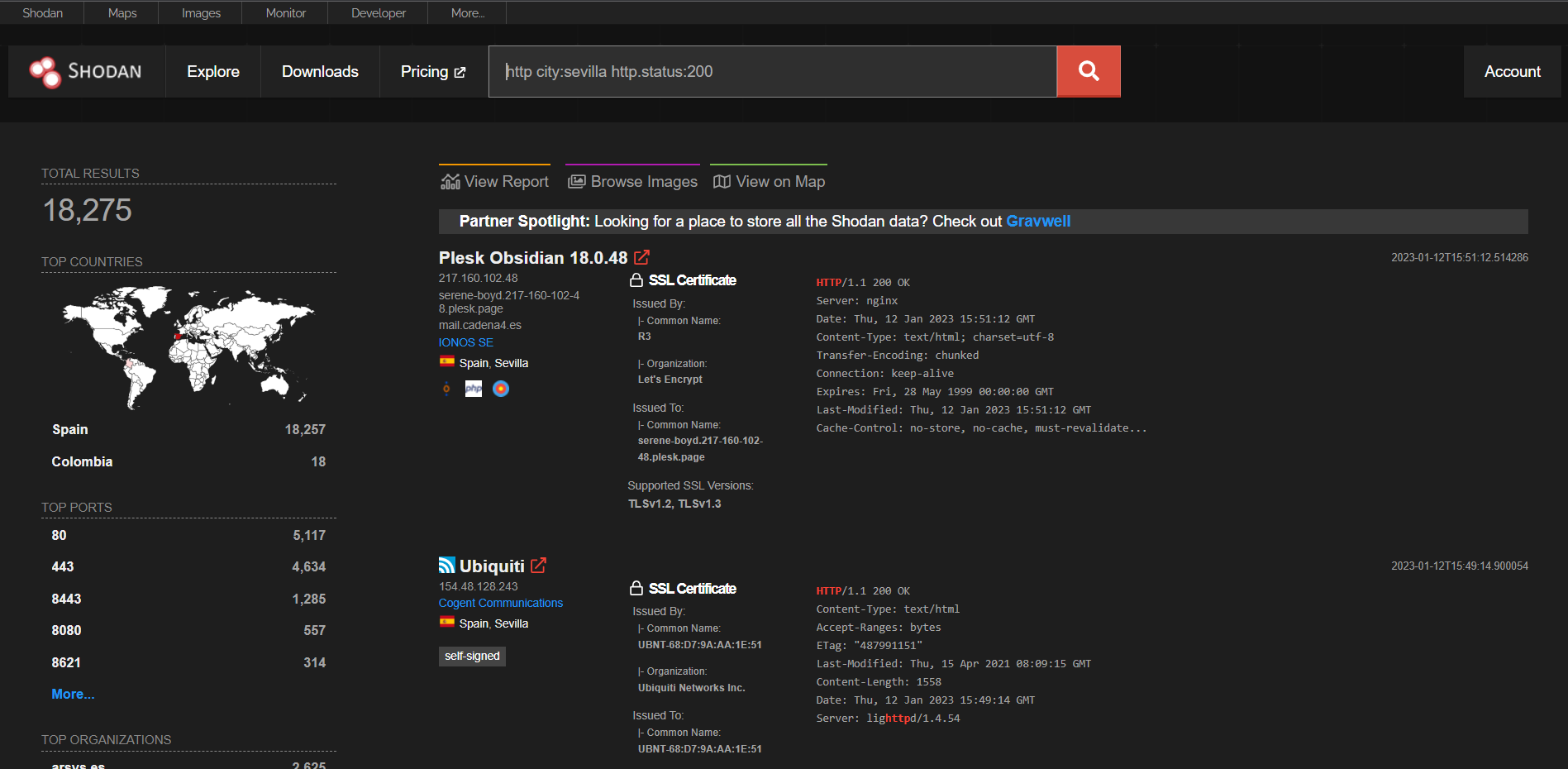
PoC: Enumerando servidores http en Sevilla
En esta prueba, tenemos como objetivos enumerar servidores http que estén ubicados en Sevilla. Usando el filtro city: visto en la tabla anterior podemos hacer la siguiente búsqueda: “http city:sevilla“.
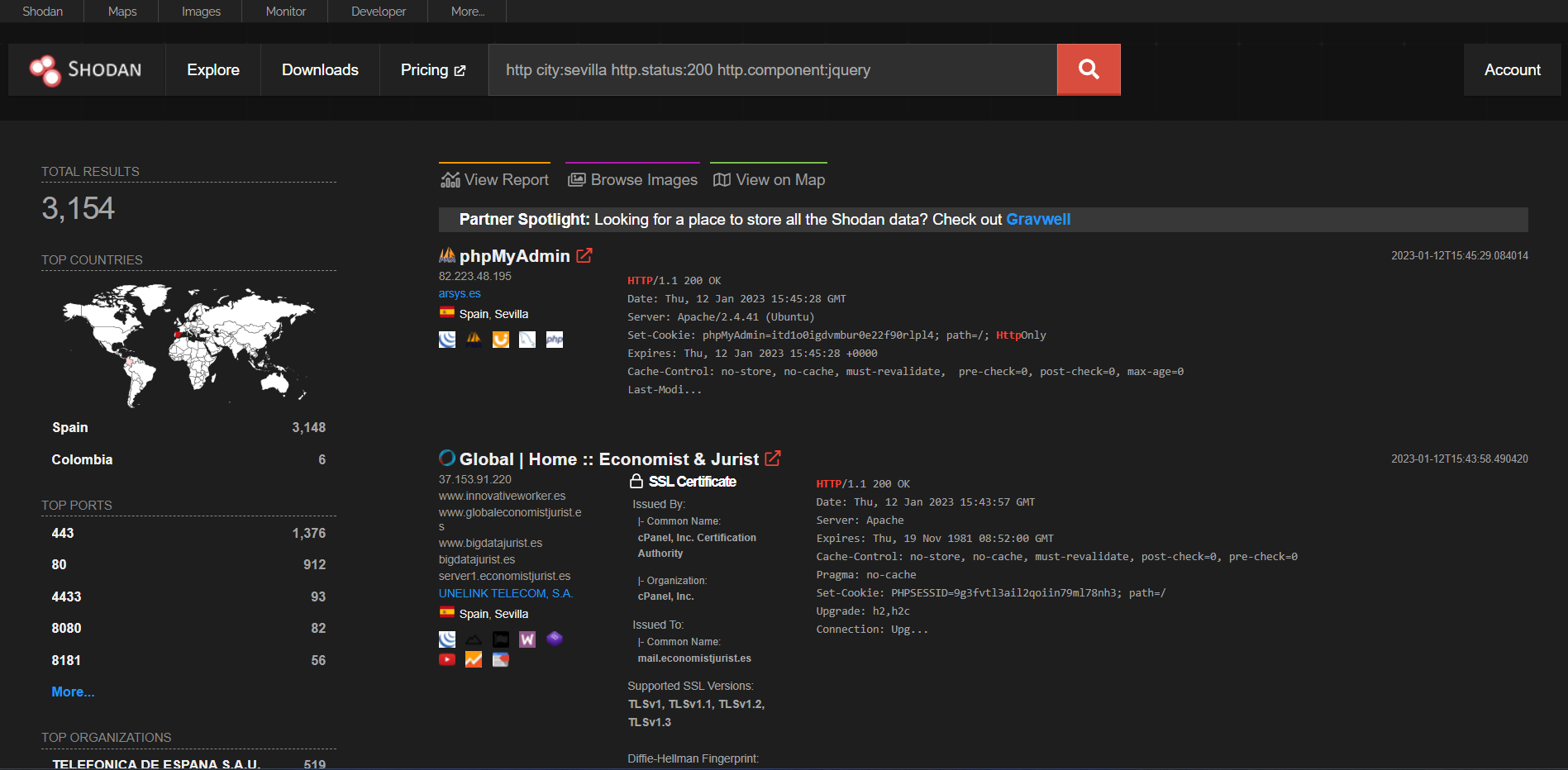
Como se puede observar en la imagen, se obtiene un total de 42704 resultados de los cuales encontramos información como la dirección IP, el dominio, el servidor que utiliza o el certificado SSL.
También podemos ver que uno de los resultados tiene un código 302, que significa que ha sido trasladado a otra ubicación. Para solucionar esto se puede usar el filtro http.status: y buscar únicamente los servidores con código 200.
Al aplicar este filtro, la búsqueda nos devuelve únicamente servidores que respondan correctamente y, como podemos observar, el número de resultados se ha reducido de forma notable.
Por último, si se quiere buscar un servidor que utilice una tecnología en específico, como podría ser jquery, se puede usar el filtro http.component
A partir de aquí y con la ayuda de más filtros podemos obtener una lista de servidores potencialmente vulnerables.
FOCA
FOCA es una herramienta utilizada para extraer metadatos de archivos. Los metadatos de un archivo es la información no visual de un archivo que proporciona un contexto adicional a este, como pueden serlo el autor del archivo, emails, el sistema operativo usado o, en el caso de las imágenes, incluso la ubicación en la que se ha tomado esa imagen.
Además FOCA es capaz de obtener todos los archivos disponibles en un sitio web que se le indique y obtener sus metadatos, lo que facilita mucho el trabajo de enumeración.
Para que todo esto se entienda mejor, se hará de nuevo una prueba de concepto en la que se extraeran los metadatos de los archivos del sitio web del ayuntamiento de Sevilla.
PoC: Extrayendo metadatos de los archivos de un sitio web
En esta prueba se extraerán los metadatos que se encuentran ocultos en los archivos de la página web del ayuntamiento de Sevilla. En FOCA hay que crear un nuevo proyecto, eligiendo un nombre para el proyecto y poniendo en el apartado domain website la url del objetivo.
Lo siguiente es elegir el motor de búsqueda que va a usar FOCA y los tipos de archivo que se quiere encontrar, en este caso se ha utilizado bing como motor de búsqueda y que se obtengan todos los tipos de archivo. Una vez elegido esto, se hace click en Search All para iniciar la búsqueda.
Para extraer los metadatos de estos archivos, hay que dar click derecho en uno de ellos y hacer click primero en Download All, y una vez descargados los archivos en Extract All Metadata.
Una vez completado este proceso, podemos observar en el panel de la izquierda todos los datos ocultos que ha conseguido encontrar FOCA. Encontramos mucha información interesante como usuarios de los sistemas, softwares utilizados, emails, o incluso sistemas operativos. Con estos datos recopilados es posible, por ejemplo, idear ataques de fuerza bruta o buscar vulnerabilidades conocidas de los softwares o sistemas operativos encontrados.
Conclusiones
En esta lección hemos visto el potencial de las herramientas más utilizadas en OSINT mediante algunos ejemplos prácticos, recomendamos investigar más acerca de ellas para aprovecharlas al máximo, ya que no se puede cubrir todo en una única lección.
También es recomendable aprender a usar otras herramientas con las que contrastar información, ya que se pueden obtener resultados distintos de ellas, por ejemplo, dos programas de extracción de metadatos pueden mostrar distintos datos de un mismo archivo.
Recordamos que el fin de aprender a usar estas herramientas, es para usarlas en entornos de pentesting.
Internet cuenta con mas de 2500 millones de usuarios a nivel mundial, cualquiera de ellos puede publicar algo en internet, la proliferación de las redes sociales en estos últimos años ha hecho que el número de información se haya visto incrementado exponencialmente.
Google almacena información de 30 billones de páginas web, lo que supone más de 1.000 terabytes de información.
Facebook tiene 2.100 millones de usuarios, 80 millones de páginas y 440.000 millones de fotos subidas a su página.
Twitter tiene más de 1300 millones de usuarios activos que escriben diariamente más de 500 millones de tweets.
Sin embargo, no hay que olvidarse de la cantidad de datos disponibles también en la Deep Web aunque no se cuenta con cifras exactas y puede ser mas relevante la información que encontremos que con métodos convencionales
OSINT son las siglas en inglés de Open Source Intelligence y se refiere a un conjunto de técnicas y herramientas utilizadas para recopilar información pública, analizar datos y relacionarlos para convertirlos en conocimiento útil.
Usamos OSINT para tomar toda la información disponible de cualquier fuente pública sobre una empresa, individuo o cualquier otra cosa que queramos investigar y convertir toda esa acumulación de datos en inteligencia que nos ayude a lograr resultados oportunos de manera más eficiente.
OSINT se utiliza en muchos campos: finanzas, tecnología, policía, militar (donde se originó), marketing, etc. Si nos centramos en el ámbito técnico y más concretamente en la ciberseguridad, encontramos varios usos de este:
Se utiliza en la etapa de reconocimiento de un pentesting: Descubrir hosts en una organización, información de Whois, encontrar subdominios, información de DNS, encontrar ficheros de configuración, passwords, etc…
Se utiliza para tests de ingeniería social: Buscar toda la información sobre un usuario (en redes sociales, documentos, etc) y ser consciente de la información que hay disponible.
Prevención de ciberataques: Obtener información que nos alerte de posibles amenazas a nuestra organización o posibles ciberataques.
Marketing: es muy útil para obtener más información sobre el público potencial de un producto y personalizar las comunicaciones
Habilidades OSINT
Las habilidades OSINT son las capacidades y los conocimientos necesarios para recopilar, analizar y utilizar información de fuente abierta para una variedad de propósitos.
Obtenga información sobre los diferentes tipos de código abierto, incluidos los sitios web públicos, las redes sociales y otros recursos en línea.
Saber cómo acceder y utilizar varias herramientas y técnicas OSINT, como motores de búsqueda, analisis de redes sociales y de metadatos.
Desarrollar la capacidad de analizar e interpretar datos de fuentes abiertas, incluida la identificación de patrones, tendencias y correlaciones.
Crear una red de contactos y recursos que puedan proporcionar información y conocimientos valiosos.
Capacidad para presentar hallazgos y conclusiones de manera clara, concisa y convincente.
Fases del Proceso OSINT
El proceso OSINT consta de las siguientes fases:
Requisitos: es la fase en la que se establecen todos los requerimientos que se deben cumplir, es decir, aquellas condiciones que deben satisfacerse para conseguir el objetivo o resolver el problema que ha originado el desarrollo del sistema OSINT.
Identificar fuentes de información relevante: consiste en especificar, a partir de los requisitos establecidos, las fuentes de interés que serán recopiladas. Hay que tener presente que el volumen de información disponible en Internet es prácticamente inabordable por lo que se deben identificar y concretar las fuentes de información relevante con el fin de optimizar el proceso de adquisición.
Adquisición: etapa en la que se obtiene la información a partir de los orígenes indicados.
Procesamiento: consiste en dar formato a toda la información recopilada de manera que posteriormente pueda ser analizada.
Análisis: es la fase en la que se genera inteligencia a partir de los datos recopilados y procesados. El objetivo es relacionar la información de distintos orígenes buscando patrones que permitan llegar a alguna conclusión significativa.
Presentación de inteligencia: consiste en presentar la información obtenida de una manera eficaz, potencialmente útil y comprensible, de manera que pueda ser correctamente explotada
Tipos de recopilaciones
Recopilación pasiva
La recopilación pasiva a menudo implica el uso de plataformas de inteligencia de amenazas (TIP) para combinar una variedad de fuentes de amenazas en una única ubicación de fácil acceso.
Recopilación activa
La recopilación activa es el uso de una variedad de técnicas para buscar información o conocimientos específicos. Para los profesionales de seguridad, este tipo de trabajo de recolección generalmente se realiza por una de dos razones:
Una alerta recopilada pasivamente ha puesto de manifiesto una amenaza potencial y se requiere una mayor comprensión.
El enfoque de un ejercicio de recopilación de inteligencia es muy específico, como un ejercicio de prueba de penetración.
Herramientas
Hay multitud de herramientas y servicios útiles a la hora de implementar un sistema OSINT. A continuación se mencionan algunos de ellos:
Buscadores habituales: Google, Bing, Yahoo, Ask. Permiten consultar toda la información que indexan. Así mismo, permiten especificar parámetros concretos (Hacking con buscadores: por ejemplo «Google Hacking» o «Bing Hacking») de manera que se pueden realizar búsquedas con mucha mayor precisión que la que utilizan los usuarios habitualmente.
Algunos ejemplos son los siguientes:
Operador
Ejemplo de búsqueda en Google
Propósito
site
site:wikipedia.org
Buscar resultados dentro de un sitio específico
related
related:wikipedia.org
Buscar sitios relacionados
cache
cache:wikipedia.org
Buscar la versión del sitio en caché
intitle
intitle:wikipedia
Buscar en el título de la página
inurl
inurl:wikipedia
Buscar una palabra contenida en una URL
filetype:env
filetype:pdf
Buscar por tipos de archivo específicos
intext
intext:wiki
Buscar en el texto del sitio web solamente
“”
“Wikipedia”
Buscar palabra por coincidencia exacta
+
jaguar + car
Buscar más de una palabra clave
–
jaguar speed -car
Excluir palabras de la búsqueda
OR
jaguar OR car
Combinar dos palabras
how to Wikipedia
Operador de comodín
imagesize
imagesize:320×320
Búsqueda de imágenes por tamaño
@
@wikipedia
Buscar en redes sociales
#
#wiki
Buscar hashtags
$
camera $400
Buscar un precio
..
camera $50..$100
Buscar dentro un rango de precios
Buscadores especializados:
Shodan: Permite entre otras cosas localizar ordenadores, webcams, impresoras, etc. basándose en el software, la dirección IP, la ubicación geográfica, etc. Mediante este servicio es posible localizar información de interés
Knowem: es una herramienta que permite comprobar si un nombre de usuario está disponible en más de 550 servicios online. De este modo, se puede saber los servicios que utiliza un usuario en concreto, ya que habitualmente la gente mantiene dicho nombre para todos los servicios que utiliza. Además, disponen de una API que permite automatizar las consultas.
Tineye: es un servicio que, partiendo de una imagen, indica en qué sitios web aparece. Es similar a la búsqueda por imagen que incorpora Google Imágenes.
Buscadores de información de personas: permiten realizar búsquedas a través de diferentes parámetros como nombres, direcciones de correo o teléfonos. A partir de datos concretos localizan a usuarios en servicios como redes sociales, e incluyen posibles datos relacionados con ellos como números de teléfono o fotos. Algunos de los portales que incorporan este servicio son: Spokeo, Pipl, 123people o Wink.
Herramientas de recolección de metadatos:
Metagoofil: permite la extracción de metadatos de documentos públicos (pdf, doc, xls, ppt, docx, pptx, xlsx). A partir de la información extraída se pueden obtener direcciones de correo electrónico del personal de una empresa, el software utilizado para la creación de los documentos y por tanto poder buscar vulnerabilidades para dicho software, nombres de empleados, etc.
FOCA: es un software de código abierto que permite a los usuarios analizar metadatos para determinar si una pagina web contiene documentos corruptos, soporta archivos tipo DOC,ODT,ODS,SVG y PPT
Servicios para obtener información a partir de un dominio:
Spiderfoot es una herramienta de reconocimiento que consulta automáticamente más de 100 fuentes de datos públicas. Las usa para recopilar información sobre direcciones IP, nombres de dominio, direcciones de correo electrónico, nombres y más.
Otras herramientas de interés:
GoBuster: Es una herramienta que por fuerza bruta es capaz de encontrar los subdominios de una web proporcionada por el usuario.
Theharvester : esta herramienta obtiene emails, subdominios, host, nombres de empleados, puertos abiertos, etc. a través de diferentes servicios como Google, Bing, LinkedIn y Shodan.
SiteDigger: al igual que GooScan permite automatizar búsquedas. Busca en la caché de Google para identificar vulnerabilidades, errores, problemas de configuración, etc.
Palantir: es una empresa que tiene como cliente a diferentes servicios del Gobierno de Estados Unidos (CIA, NSA y FBI) y que se centra en el desarrollo de software contra el terrorismo y el fraude, mediante la gestión y explotación de grandes volúmenes de información.
Maltego: permite visualizar de manera gráfica las relaciones entre personas, empresas, páginas web, documentos, etc. a partir de información pública.Para usar Maltego, se requiere el registro del usuario, el registro es gratuito. Una vez que los usuarios se registran pueden usar esta herramienta para crear la huella digital del objetivo en Internet.
Conclusión
Saber cómo extraer inteligencia de código abierto es una habilidad importante para cualquier persona involucrada en la ciberseguridad.
El factor más importante para el éxito de cualquier iniciativa de inteligencia de código abierto es la presencia de una estrategia clara: una vez que sepas lo que estás tratando de lograr y hayas establecido los objetivos en consecuencia, identificar las herramientas y técnicas más útiles será mucho más realizable.
Ya sea que esté protegiendo su red corporativa o investigando vulnerabilidades, cuanto más sepa sobre su huella digital, mejor podrá verla desde la perspectiva de un atacante.
Armado con este conocimiento, puede continuar desarrollando mejores estrategias de defensa y ataque.
Riesgos Cibernéticos y el Ciclo de vida del ataque
Prepararse para manejar incidentes requiere una planificación cuidadosa, una planificación más allá de la creación de un plan de respuesta a incidentes, manuales de estrategias y pruebas anuales o semestrales. Con tiempo y recursos limitados, tiene sentido centrar la atención en áreas en las que es probable que ocurran eventos de ciberseguridad. Saber dónde enfocarse se obtiene respondiendo las siguientes preguntas:
¿Qué riesgos invitan a los atacantes a la red?
¿Qué vectores de ataque es probable que se utilicen?
Dos herramientas importantes diseñadas para responder a estas preguntas son laevaluación del riesgo y elciclo de vida del ataque de ciberseguridad desarrollado por Mandiant.
La evaluación de riesgos establece los riesgos presentes en el entorno en el que es probable que ocurran eventos ciberseguridad.
El ciclo de vidade un ataque de ciberseguridad describe el proceso que siguen los atacantes cuando buscan violar entidades y robar, modificar o destruir activos.
La evaluación y el análisis del riesgo de ciberseguridad implica varios elementos clave. Analizando adecuadamente riesgos para los activos digitales de la entidad requiere evaluar las amenazas y vulnerabilidades que es probable que estas amenazas exploten y analizar cada una en términos de la probabilidad de un ataque exitoso y el impacto para la entidad.
Ver estos riesgos en términos del ciclo de vida del ataque, anteriormente conocido como Kill Chain, genera un contexto en términos de las amenazas de un vector de ataque. Piense en ello como colocar el ciclo de vida del ataque encima de la evaluación de riesgos. Un actor de amenazas explota una vulnerabilidad para obtener un punto de apoyo inicial dentro de la entidad. Luego busca formas de explotar otros sistemas, aumentando sus privilegios, hasta alcanzar el objetivo. Priorizar el plan de respuesta a incidentes y los libros de jugadas asociados en torno a estos escenarios mejora la planificación y la preparación para posibles incidentes.
Documentación de riesgos cibernéticos
Evaluar los riesgos de ciberseguridad requiere seis actividades clave. Los primeros cuatro son la identificación de activos, la identificación de amenazas, la identificación de vulnerabilidades y la evaluación del riesgo inicial para los activos digitales en la entidad. El quinto paso es identificar los controles de seguridad, a veces denominados medidas, destinados a reducir los riesgos cibernéticos. El sexto paso mide el riesgo residual, el riesgo que permanece una vez que se identifica un control de seguridad cibernética y se mide la efectividad en la reducción del riesgo.
A continuación, dejamos un esquema de cómo se podría medir el riesgo:
Análisis de amenazas
Las amenazas, tanto los actores de amenazas como los escenarios de amenazas, son personas, grupos y eventos que aprovechan las debilidades de los sistemas de información de una organización para llevar a cabo actos dañinos. Estos actos apuntan a la confidencialidad, integridad y disponibilidad de los activos digitales.
Los ataques de ciberseguridad están dirigidos contra uno o más de los pilares que se muestran en imagen anterior. Ataques como la violación de un Ayuntamiento tienen como objetivo la confidencialidad de los datos. Los datos son accesibles por personas no autorizadas, ya sea que solo accedan o se eliminen.
Los ataques contra la integridad de los datos se producen cuando un actor de amenazas cambia los datos sin que los propietarios de los datos detecten estos cambios. Incluso cuando se detecta una brecha, estos ataques siguen siendo problemáticos, porque a veces es imposible saber qué datos cambiaron no siempre es una tarea fácil. Las operaciones del día a día requieren los datos precisos, por lo que cuando la integridad se ve comprometida, el rendimiento de los servicios se ve afectado.
Los ataques de disponibilidad incluyen ataques de denegación de servicio diseñados para bloquear servidores y otros dispositivos de red. Cuando las redes dejan de estar disponibles, los ingresos y las obligaciones contractuales pueden estar en riesgo. El ransomware es otro tipo de ataque de disponibilidad. Estos son comunes como se puede ver leyendo las noticias a diario. Siempre hay una gran empresa u organización víctima de este tipo de ataque.
Muchas veces, estos intentos tienen éxito cuando los atacantes explotan con éxito a los usuarios finales que, sin darse cuenta, lanzan malware diseñado para cifrar bases de datos y otros repositorios importantes.
Los atacantes esperan que las entidades víctimas paguen un rescate para desbloquear los datos. Si no se paga el rescate, los atacantes amenazan con destruir los datos. Es importante saber que existen copias de seguridad con integridad y que están listas para fines de restauración; de lo contrario, las organizaciones objetivo tienen opciones limitadas.
El último ejemplo de amenazas a la disponibilidad se incluye en los planes de continuidad del negocio y recuperación ante desastres. Eventos como inundaciones, terremotos y ataques terroristas provocan interrupciones en las operaciones comerciales y fuerzan la recuperación de las operaciones de IT en otros sitios geográficos de respaldo. Afortunadamente estas situaciones no suelen darse en España.
Los actores y escenarios de amenazas provocan incidentes que varían en clasificación desde molestos hasta perjudiciales. En casos severos, las amenazas provocan la pérdida de ingresos significativos durante varios años.
Medición de la gravedad del riesgo
El riesgo se mide utilizando dos parámetros: probabilidad de que el riesgo sea explotado e impacto para la entidad si es explotado. Cada uno tiene sus propias consideraciones para la medición.
Probabilidad
La probabilidad establece las probabilidades de que una amenaza explote una vulnerabilidad. Esto se basa en varios factores:
¿Qué tan conocida es la vulnerabilidad públicamente?
¿Cuáles son las probabilidades de que los actores de amenazas conozcan y puedan encontrar la vulnerabilidad en el entorno de las organizaciones?
¿Qué habilidades o recursos especiales se requieren para administrar con éxito el exploit?
¿Vale la pena el esfuerzo por la vulnerabilidad?
Estas preguntas se utilizan para comprender y medir las vulnerabilidades en términos de probabilidad. Sin datos estadísticos significativos y herramientas actuariales, la probabilidad puede ser subjetiva. Estos tipos de evaluación de riesgos se conocen como cualitativos. El análisis utilizado para desarrollar la medición del riesgo no utiliza mediciones estadísticas. El uso de dichas herramientas permite que la evaluación de riesgos sea cuantitativa. Siempre que sea posible, una combinación de los dos tipos produce resultados en los que los beneficios superan los costos. Tanto las evaluaciones de riesgo cualitativas como cuantitativas utilizan una escala de uno a cinco, indicando cinco que la vulnerabilidad tiene una alta probabilidad de ser explotada.
Impacto
El impacto mide el daño causado a la entidad si se explota con éxito una vulnerabilidad.
Un exploit que otorga a un atacante acceso root a un sistema GNU/Linux o un administrador del sistema (SA) acceso a una base de datos SQL son exploits de alto impacto. Este acceso le da a un actor de amenazas la capacidad de hacer cualquier cosa que elija con el sistema y sus datos. Comprender el impacto es una función de varios factores:
Los datos que procesa el sistema.
Los privilegios expuestos a través del exploit.
Capacidad para detectar el exploit o los movimientos del atacante después.
Proximidad a datos de misión crítica.
Los tres primeros se explican por sí mismos. Si el exploit en cuestión existe en un sistema de salud (imagina un hospital por ejemplo o centro de salud). Los sistemas que procesan la información del paciente son entornos de alto impacto. Las cuentas de administrador tienen un alto impacto si los atacantes obtienen acceso a ellas. Otra consideración relacionada con el impacto es la detección. Si un atacante obtiene acceso, lo que le permite ejecutar comandos de PowerShell, por ejemplo, y las herramientas de detección no están presentes para detectar su uso, podría existir una situación de alto impacto. El último elemento, la proximidad a los datos de misión crítica, considera en qué parte del ciclo de vida del ataque el exploit introducidor por el atacante.
¿El atacante solo necesita encontrar una debilidad más para violar los datos de destino? Estas características se consideran al evaluar el impacto. El impacto también se mide muchas veces usando una escala de uno a cinco, donde cinco indica el mayor impacto.
La siguiente imagen muestra un mapa de calor, un ejemplo que usa la escala de uno a cinco para las calificaciones de probabilidad e impacto gestionado por Pilar utilizando metodología Magerit:
Usando el mapa de calor, un riesgo con un impacto muy alto y una probabilidad muy alta se considera muy alto. Los riesgos con calificaciones muy bajas en ambas categorías se Consideran muy bajos. Cualquier otra combinación de probabilidad e impacto se encuentra en algún punto intermedio.
Revisar la evaluación de riesgos
Una vez que se completa la evaluación de riesgos, se muestra visualmente el plan para planificar y anticipar cómo podría ocurrir una infracción. En la siguiente imagen, se muestra un ejemplo abreviado de un registro de riesgo producido durante la evaluación con la herramienta Pilar, vemos como muestra un riesgo alto, medio y bajo:
El alto riesgo documentado durante la evaluación indica que los empleados son susceptibles a los ataques de phishing. Una forma de reducir el nivel de riesgo es identificar un control de ciberseguridad. Para combatir a los usuarios finales vulnerables que son el objetivo de los ataques de phishing, un control de capacitación y concienciación identificado en el ENS se alinearía con este riesgo. La cantidad de reducción de riesgo, si la hay, depende de la madurez del proceso de control. Los controles inmaduros tienden a operar de manera ineficaz y, por lo tanto, no logran reducir la cantidad de riesgo. Durante la planificación de la respuesta a incidentes, el equipo se concentraría en prepararse para los ataques lanzados a través de correos electrónicos dirigidos a los empleados. Los libros de jugadas que describen las acciones necesarias para combatir las campañas de phishing, el malware y los ataques de ransomware son áreas de enfoque clave para las sesiones de práctica.
El riesgo medio ilustra las vulnerabilidades que los ataques de por ejemplo otros gobiernos y los ciberdelincuentes pueden explotar en aplicaciones web. Éste permite el acceso al entorno de una entidad. El equipo de respuesta a incidentes debe planificar ataques exitosos contra servidores web y comprender los libros de jugadas relevantes para contener un ataque de este tipo.
El bajo riesgo muestra que la entidad hace un trabajo efectivo manteniendo un inventario de activos de hardware y software. El equipo de respuesta a incidentes no tiene que dedicar tanto tiempo a planificar las respuestas debido a la pérdida de activos.
Estos tres ejemplos ilustran cómo el equipo de respuesta a incidentes puede analizar Escenarios en los que se inician eventos, incidentes y violaciones: riesgos críticos y altos primero, luego moderados según sea necesario y, finalmente, riesgos bajos. Es probable que los riesgos bajos no formen parte de la planificación de escenarios y que solo ciertos riesgos moderados/medios, dependiendo de la superposición con los riesgos críticos y altos, sean, por ejemplo, el riesgo medio debido a la explotación de aplicaciones web mal configuradas. Si existiera un alto riesgo debido a que se estaban usando bibliotecas de código desactualizadas, el riesgo de configuración podría ser redundante y no necesario para la planificación de incidentes. Los elementos del registro de riesgos deben evaluarse individualmente, pero deben tenerse en cuenta cuando estén presentes vectores de ataque comunes.
El ciclo de vida del ciberataque Mandiant
Un aspecto importante de la preparación de respuesta a incidentes es la planificación del juego. Los equipos deportivos profesionales y aficionados se preparan para los oponentes antes de las competencias. El propósito es comprender qué hace bien el adversario y qué debilidades se pueden explotar son piezas clave del rompecabezas. El ciclo de vida de un ciberataque creado por Mandiant, ilustra los pasos que realizan los atacantes contra las entidades, organizaciones, empresas, etc.
Romper el ciclo de vida
Se puede pensar que el ciclo de vida del ataque tiene tres fases:
El primero comienza con el reconocimiento inicial y termina una vez que se establece un punto de apoyo dentro de la red objetivo.
El segundo es un proceso iterativo de aumento de privilegios, realización de reconocimiento interno, movimiento lateral y mantenimiento de la persistencia.
La última fase es terminar el trabajo.
Fase uno
Los ataques que experimentan las entidades en el entorno actual no son golpes rápidos, en muchos casos.
Este conjunto inicial de actividades está diseñado para recopilar la mayor cantidad de información posible sobre el objetivo. Los atacantes a menudo saben más sobre la red de la que planean aprovecharse que las personas que trabajan diariamente en el sitio de la red objetivo.
Reconocimiento
Existen muchos métodos para llevar a cabo el reconocimiento. Existen herramientas de código abierto para que las utilicen los piratas informáticos, pero gran parte de la información recopilada está disponible públicamente. A continuación se enumeran las formas comunes en que los atacantes recopilan datos para usarlos contra sus objetivos y los beneficios de esta información:
Shodan: Los atacantes pueden ver los puertos y servicios expuestos de nuestros servidores.
DNS: Se puede realizar un reconocimiento sobre los dominios y subdominios de nuestra entidad u organización.
Osint: Los atacantes pueden comprender la entidad, el personal, la tecnología utilizada y los problemas de personal.
Recolección de correos: Una lista de objetivos en la entidad puede dar lugar a campañas masivas de Phishing que intentan explotar a un usuario final y obtener acceso
Dos formas comunes en las que las entidades se ven comprometidas son a través de ataques de phishing y la explotación de dispositivos mal configurados (más sobre esto en la siguiente sección). Los ataques exitosos son el resultado de una amplia inteligencia recopilada antes de que se lance cualquier método de ataque activo.
Compromiso inicial
Si un atacante puede engañar a los usuarios finales para que los dejen entrar en el entorno, se pueden eludir todos los controles de seguridad en el perímetro e internamente. Aprovechar configuraciones defectuosas en dispositivos expuestos a Internet es otra forma en que los atacantes intentan infiltrarse en las redes. Los actores de amenazas de hoy tienen la ventaja de contar con vastos recursos para aprovechar la inteligencia recopilada durante la etapa de reconocimiento. Si el método elegido es un ataque de phishing, los atacantes sabrán todo lo posible sobre el objetivo, tanto personal como profesional, para aumentar las posibilidades de éxito.
Establecer un punto de apoyo
Una vez dentro, se utiliza software malicioso para establecer un punto de apoyo en el entorno.
Los ataques de phishing exitosos conducen al control sobre un dispositivo de usuario final o credenciales robadas.
La explotación de aplicaciones web, por ejemplo, le da al adversario un nivel de acceso privilegiado que es útil. El objetivo requiere colocar una puerta trasera en el sistema, para que los atacantes puedan entrar y salir.
Fase dos
Esta fase es iterativa. En primer lugar, se cumplen los requisitos de escalada de privilegios. Estos privilegios se utilizan para realizar un reconocimiento del entorno interno y moverse lateralmente hacia el objetivo, manteniendo la persistencia. Cuando se presentan oportunidades para escalar aún más los privilegios, o se presentan privilegios a otros entornos, estas credenciales se utilizan para ejecutar nuevamente el reconocimiento interno, seguir moviéndose a través de la red y mantener la persistencia. Este ciclo continúa hasta que se logra la misión.
Elevación de privilegios
Una vez dentro, los atacantes quieren escalar los privilegios, primero investigando la máquina comprometida, para ver si existe alguna forma de escalar. La higiene ciberseguridad juega un papel en la limitación de la capacidad de los atacantes para aumentar los privilegios. Si las cuentas administrativas o de servicio predeterminadas son omnipresentes en el entorno, no es difícil para los grupos maliciosos comprometer una de estas cuentas para obtener privilegios elevados.
Reconocimiento interno
El reconocimiento interno consiste en investigar las conexiones a la máquina comprometida inicialmente y/o la máquina que actualmente controla a los atacantes. Es posible usar Nmap para descubrir conexiones. Depende de si el atacante piensa que existen capacidades de detección para alertar a la entidad del escaneo.
Mover lateralmente
Una vez que un atacante ingresa y mapea una disposición del terreno, es hora de moverse. La intención es encontrar credenciales con la capacidad de ingresar a los sistemas que albergan los datos a los que se dirige el atacante. Esto incluye acceder a máquinas que son literalmente movimientos laterales, lo que significa que no se produce una elevación de credenciales, y encontrar máquinas en las que existan credenciales elevadas.
Mantener la presencia
Los ataques se llevan a cabo durante varios meses o años. Algunas estadísticas informan un retraso de siete meses o más antes de la detección de intrusiones. Esto significa que los actores de amenazas van y vienen. Lo hacen mediante la implementación de una puerta trasera, lo que permite el acceso cuando existe el tiempo para continuar el ataque.
Una forma sencilla es mediante conexiones inversas. Los atacantes también usan rootkits, otras formas por ejemplo es dejando puertas traseras en los sistemas como otra forma de mantener la persistencia. Si las capacidades de monitoreo son inmaduras, habilitar este servicio facilita la reconexión y no son detectadas por la organización.
Fase tres: completa la misión
Esta es una fase de un solo paso. Una vez que el atacante ha encontrado lo que está buscando, lo siguiente es eliminar, cambiar o destruir los datos. Si el atacante quiere robar datos, los mueve por medios irregulares y en incrementos lo suficientemente pequeños como para no causar alarma.
Cómo ayuda esto
Usando lo anterior, el equipo de respuesta a incidentes desarrolla escenarios de amenazas. Lograr esto requiere pensar en varios puntos clave.
Los atacantes apuntando a la entidad.
Los métodos utilizados para realizar el ataque y completar la misión.
Debilidades que explota.
Debilidades similares dentro de la entidad.
Acciones disponibles para reducir la probabilidad de éxito.
Vincule la evaluación de riesgos y la cadena letal.
Dos formas comunes en las que se lanzaron ataques en los últimos años fueron a través de la explotación de los usuarios finales a través de ataques de phishing y la explotación de las debilidades de configuración en las aplicaciones web. Estos vectores de ataque representan las formas en que los atacantes ingresan inicialmente y establecen un punto de apoyo en las entidades. Estos riesgos, si son altos o medios, requieren un seguimiento y una evaluación constantes. La medición del nivel de riesgo de la vulnerabilidad del usuario final y la protección de las aplicaciones web para los cambios mantienen a la entidad alerta y enfocada en las formas comunes en que comienzan los eventos, incidentes e infracciones.
Formación y concienciación a los usuarios finales
Los ataques de phishing se utilizan para ingresar y establecer un punto de apoyo para el atacante o para liberar ransomware. A partir del ataque a Anthem, 2015 se convirtió en un año de grandes filtraciones, debido a ataques de phishing. Estos ataques se dirigieron a entidades sanitarias y capturó muchos titulares. El ataque de Anthem comenzó con un ataque de phishing selectivo bien diseñado dirigido a una persona con credenciales elevadas. El correo electrónico que inició la cadena de eventos llevó al objetivo a un dominio malicioso.
En España, llevamos años recibiendo ciberataques en varios sectores, si bien los titulares los ocupan las estafas del CEO o algún ransomware que ha cifrado algún Ayuntamiento, este tipo de ciberataque más sofisticado y dirigido no suele ocupar los titulares, pero no significa que no se esté dando. Lamentablemente la implantación del ENS va muy lenta y cuenta con el poco interés político, falta de medios y recursos, que de alguna forma convierten las entidades públicas españolas en blancos fáciles de todo tipo de organizaciones que podemos englobar como “atacantes”.
Conclusión
La planificación de respuestas a eventos de ciberseguridad es muy similar a la planificación de juegos en deportes o la planificación de batallas militares. Teniendo en cuenta cómo atacan los adversarios en función de sus métodos preferidos y qué debilidades existen en los sistemas de información, el equipo se centra en acciones específicas para aumentar la eficacia del programa de respuesta a incidentes.
Comprender qué riesgos existen para los activos es imprescindible. Discutir estos riesgos en términos de cómo los atacantes sofisticados se acercan a los objetivos ayuda al equipo a construir un programa integral destinado a prepararse para manejar eventos con el potencial de ocurrir.
Evidentemente, hace falta un equipo que esté al día, entrenado y con tiempo para investigar, aprender y estar siempre al día en este tipo de cosas. Eventos como el evento sevillano SecAdmin que se realiza una vez al año en el mes de noviembre en Sevilla son sitios clave para mantener a los equipos de respuesta de incidentes al día e informado de las últimas tendencias en ciberataques.
Disponer de bajos recursos, un equipo que no esté actualizado y sobre todo sin tiempo para probar, testear, hace que no funcione bien. En España, muchas veces se tiene la idea que un equipo de respuesta a incidentes es un equipo dormido, que no hace nada hasta que suenan las alarmas. Si esto fuera así, entonces ese equipo ha fracasado antes de empezar. No tendrá ensayado los procedimientos, no tendrá definido los roles y responsabilidades, y ante un incidente correrán de un sitio a otro sin mitigar ni solucionar nada.
Ya hemos hablando un poco y definido en qué consiste ese plan, quién lo debe llevar a cabo. Ahora vamos a centrarnos en los requisitos necesarios.
¿Toda organización puede tener su plan de respuesta a incidentes?
Requisitos previos
Antes de construir el programa de respuesta a incidentes, deben existir capacidades específicas. Como mínimo, estos deben incluir la adopción de un marco elegido; una comprensión de los activos que la entidad debe enfocarse en proteger; documentación de los riesgos a la confidencialidad, integridad y disponibilidad de los activos; y seguridad de que existen todas las capacidades de protección fundamentales.
Ejemplos de estas capacidades incluyen:
Procesos de control de acceso y restricción de privilegios elevados
Protección contra el uso indebido de datos en movimiento, en uso y en reposo
Endurecimiento de herrajes, en base a estándares establecidos
Comprensión y gestión de vulnerabilidades
Existencia de protecciones de redes de comunicación y control (cortafuegos, etc)
Estableciendo las funciones de identificación y protección
La ciberseguridad es una función que siempre supone un coste, es decir, no se ve como un motor de ingresos para una organización. Rara vez se nota el programa de seguridad de la información cuando las cosas van bien. Los líderes de seguridad informática deben justificar continuamente los gastos de un programa y la necesidad de empleados a tiempo completo, etc. Es posible que una empresa nunca vea valor en la ciberseguridad hasta que se evite o mitigue con éxito una crisis. Lo más probable es que se culpe a la seguridad cuando se produce un incidente.
A pesar de estos desafíos, la seguridad informática debe superar estos desafíos para proteger los activos de una entidad. El primer paso es definir el programa de ciberseguridad a través del Esquema Nacional de Seguridad (ENS).
Programa de ciberseguridad definido
Para lograr el objetivo de la respuesta a incidentes, que es mitigar el impacto de eventos, incidentes y quiebres de seguridad, todo el programa de ciberseguridad debe operar de manera efectiva, no solo los programas de respuesta y recuperación. El programa debe estar impulsado por un propósito y una misión, comunicados a todos los miembros del equipo de ciberseguridad, que, a su vez, deben estar alineados y trabajar hacia los mismos objetivos.
La ciberseguridad protegerá incansablemente la información de nuestros usuarios mediante el establecimiento de capacidades efectivas y fundamentales de identificación de amenazas y la protección con capacidades de detección, respuesta y recuperación en caso de incidente.
Después de establecer el propósito y la misión, el programa se evalúa y mide para determinar la madurez y eficacia del estado actual. Medir el estado actual impulsa la hoja de ruta para cumplir con la misión. Usando un horizonte temporal de tres años, los objetivos anuales impulsan el programa. Crear responsabilidad sobre quién, qué, dónde, cuándo y cómo lograr los objetivos del programa; formación de subprogramas; y lograr la alineación con la misión de la organización.
Un enfoque programático
La construcción de programas de ciberseguridad conduce a acciones de medición y mejora que continúan año tras año. El pensamiento de dominio podría conducir a centrarse en competencias y enfoques únicos para ciertas capacidades. La implementación de firewalls administrados por un ingeniero de seguridad podría hacer que algunos sientan que el perímetro de la red está suficientemente protegido. No se requiere ningún esfuerzo adicional para esta subcategoría. Los programas son continuos. Las iteraciones, ciclos o sprints (los términos no importan) ocurren con hitos definidos. Una vez que se cumplen esos hitos, se crean otros nuevos.
En términos de un programa de ciberseguridad, la esperanza es que los hitos se vuelvan más incrementales a medida que el programa madura.
Identificación de programas
La subcategoría Tecnología de protección encaja lógicamente en un programa de protección de red. El líder del programa y el equipo deben concentrarse en garantizar que se implemente la tecnología fundamental. Las personas y los componentes del proceso mantienen los dispositivos configurados de acuerdo con las prácticas líderes seguras.
Los programas muy maduros rastrean métricas específicas y analizan cada una de acuerdo con criterios establecidos por la entidad, como los siguientes: ¿Se bloqueó el tráfico de manera incorrecta? ¿Se perdió el tráfico malicioso? ¿Se realizaron cambios de configuración sin aprobación o se encontraron configuraciones inseguras?
Estos datos se utilizan durante los ejercicios anuales de planificación y presupuesto para identificar mejoras en las personas, los procesos y la tecnología, para que el programa sea más efectivo. En un ambiente centrado en el programa, este ritual ocurre anualmente, para asegurar que el programa se mantenga encaminado para satisfacer las necesidades de la organización.
La siguiente imagen ilustra ejemplos de programas que las entidades pueden crear propuestas por el NIST.
Aquí en España, podemos encontrar el marco de referencia del ENS. Si se comparan los ítems, veremos que coinciden en su mayoría. Hay que recordar entonces que un programa de respuesta a incidentes es un componente esencial de un programa de ciberseguridad. Cada componente de framework sirve para hacer que los demás sean mejores y capaces de cumplir con los objetivos de la organización de ciberseguridad. Como se describió anteriormente un programa de respuesta a incidentes no cumplirá sus objetivos si los programas como la gestión de acceso, la protección de datos, la protección de la información y todos los demás no siguen una gestión de programa eficaz.
¿Cómo apoya cada programa la respuesta a incidentes?
La respuesta a incidentes, como programa, es vital para una entidad para que el daño de los ataques sea limitado. La respuesta a incidentes no es un programa independiente. Sin programas efectivos que lo respalden, existen capacidades limitadas para detectar, contener, erradicar y recuperarse rápidamente de las infracciones.
La siguiente imagen muestra ejemplos de cómo cada programa contribuye a la respuesta a incidentes.
Conclusiones
Antes de actuar según el deseo de crear el mejor programa de respuesta a incidentes de su clase, es necesario establecer las capacidades descritas en las funciones de identificación y protección del framework elegido, posiblemente el ENS. Estas funciones por ejemplo del ENS, como parte de los programas de ciberseguridad que respaldan el programa de respuesta a incidentes, deben ser fundamentalmente efectivas. Sin gobernanza, gestión de riesgos, gestión de activos, protección de red, gestión de amenazas, gestión de acceso, control de cambios, capacitación y concienciación, y continuidad del negocio/recuperación ante desastres, es casi imposible que el programa de respuesta a incidentes sea efectivo.
Cada uno de los programas descritos ejecuta actividades clave requeridas para que la respuesta a incidentes sea efectiva. Sin estos, el potencial de respuesta a incidentes para satisfacer las necesidades de la entidad es muy limitado.