Esta es otra área donde se usan mucho las funciones de hashes. Las blockchains como Bitcoin, Ethereum, NEO o TRON hacen uso de contratos inteligentes para potenciar distintas aplicaciones. Estas aplicaciones son manejadas por un contrato público entre partes. Sin embargo, muchos de estos datos son muy sensibles, o simplemente es demasiada información para ser almacenada en una blockchain. Por lo que la mejor forma de solventar estos escenarios es a través de funciones de hash. De esta manera, todo el contrato es público pero información enlazada o que se quiere mantener privada no es publicada. Estos datos pueden incluir nombres, direcciones, direcciones de monederos, datos de terceros participantes. Es decir; información privilegiada y solo de interés entre partes.
Los hashes también son usados para versionar los contratos. Es decir, un contrato público tiene un hash único que viene dado por lo que dice el contrato. Si el contrato es modificado, el contrato anterior es terminado y se genera uno nuevo con un nuevo hash. De esta manera el hash determina el contrato correcto a usar dentro de aplicación descentralizado facilitando su control. Otro uso de las hash en contratos inteligentes es; para marcar la validez y autenticidad del mismo. Un ejemplo puede ser; un contrato hecho para la venta de una casa con un pago hecho en criptomonedas. La realización del contrato y su hash serán testigos inalterables de venta realizada entre las partes.
¿Para qué sirven estos códigos?
Como estos códigos representan un valor único para cada documento, sus usos pueden verse en infinidad de operaciones:
Firma electrónica: asegura la identificación de un documento de forma inequívoca y la no modificación del mismo después de la firma. El hash antes de la firma y el que se genera después de la misma deben coincidir lo que supone un gran beneficio para la seguridad de la operación.
Antivirus: para saber si un archivo es malicioso (malware) utilizan, de forma exclusiva, los códigos hash.
Gestor de contraseñas: servicios como Google, a la hora de guardar nuestras contraseñas, lo hacen mediante código hash en un texto que no sea plano, lo cual le dará más seguridad y privacidad a nuestras claves.
Criptomonedas: se utiliza en todas las operaciones derivadas de la tecnología blockchain. Poder crear seguridad, privacidad y transacciones fiables gracias a los hash es una clara ventaja.
Tipos de hash más usados
La actualización constante en el mundo tecnológico es algo prácticamente obligatorio. Es por ello por lo que la creación de código hash ha ido desarrollando diferentes sistemas para mejorar, sobre todo, en seguridad.
A continuación, vamos a ver los tipos de hash más utilizados en nuestros tiempos:
MD5 (Message-Digest Algorithm 5) → su función principal es detectar que ningún archivo haya sido modificado
MySQL → es un software creado por Oracle con el que se pueden gestionar bases de datos
SHA → permite dificultar la obtención de una cadena de origen con el mismo contenido que la cadena de salida, evitando así el duplicado de datos y la inseguridad de los archivos.
¿Hashing?
¿Qué podemos hacer con el hashing?
Hashing se utiliza para 2 propósitos principales en ciberseguridad. Para verificar la integridad de los datos, o para verificar contraseñas.
Hashing para verificación de contraseña
La mayoría de las aplicaciones web necesitan verificar la contraseña de un usuario en algún momento. Almacenar estas contraseñas en texto sin formato sería malo. Probablemente hayas visto noticias sobre empresas a las que se les filtró su base de datos. Esto como imaginarás puede ser un problema para aquellas personas que les gusta usar la misma contraseña para todo, incluso para sus operaciones bancarias, por lo que una filtración de este tipo para ellos, puede ser muy malo, porque pueden perder acceso a todas sus cuentas de redes sociales, y más en cuestión de horas. Si quieres saber si tu contraseña también está comprometida, puedes ir a este sitio: https://haveibeenpwned.com/, seguro que si tienes una cuenta en twitter te sorprenderás.
Esta es la tendencia de estos últimos años, hay bastantes violaciones de seguridad y filtrado de contraseñas de texto sin formato.
Si te gusta el mundo del pentesting, es posible que conozcas el diccionario más famoso llamado “rockyou.txt” que viene en cualquier distribución de Kali Linux. Es un diccionario que está compuesto por una lista de palabras con contraseñas. El origen de este archivo viene de una empresa que hizo widgets para MySpace. Almacenaron sus contraseñas en texto sin formato y la empresa tuvo una violación de seguridad, un ataque. Por lo que el archivo txt contiene más de 14 millones de contraseñas (aunque es poco probable que algunas hayan sido contraseñas de usuario. Si las pones por orden de longitud verás a los que me refiero).
Otro caso en el que Adobe tuvo una violación de datos notable, pero fue ligeramente diferente. Las contraseñas estaban cifradas, en lugar de texto claro y el cifrado que se utilizó no era seguro. Esto significaba que las contraseñas se podían recuperarse con relativa rapidez. Si desea leer más sobre esta filtración, mira la siguiente publicación de Sophos es este enlace:
Otro caso que de alguna forma, nos afectó a todos, es la de Linkedin, también tuvo una violación de datos. Linkedin usó SHA1 como verificación de contraseñas, que es bastante rápido de calcular usando GPU.
Aquí es donde entra en juego el hashing. ¿Qué sucede si, en lugar de almacenar la contraseña, solo almacena el hash de la contraseña? Esto significa que nunca tendrá que almacenar la contraseña del usuario, y si su base de datos se filtró, un atacante tendría que descifrar cada contraseña para averiguar cuál era. Eso suena bastante útil.
Solo hay un problema con esto. ¿Qué pasa si dos usuarios tienen la misma contraseña? Como una función hash siempre convertirá la misma entrada en la misma salida, almacenará el mismo hash de contraseña para cada usuario. Eso significa que, si alguien descifra ese hash, ingresa en más de una cuenta. También significa que alguien puede crear una “rainbow” para romper los hashes.
Una tabla arcoíris o “rainbow” en inglés, es una tabla de búsqueda de hashes a textos, por lo que puede averiguar rápidamente qué contraseña tenía un usuario a partir del hash. Una tabla de arcoíris intercambia el tiempo necesario para descifrar un hash por espacio en el disco duro, pero se necesita tiempo para crearla. Aquí hay un ejemplo rápido para que pueda tratar de entender cómo son.
Hash
Clave
02c75fb22c75b23dc963c7eb91a062cc
zxcvbnm
b0baee9d279d34fa1dfd71aadb908c3f
11111
c44a471bd78cc6c2fea32b9fe028d30a
asdfghjkl
d0199f51d2728db6011945145a1b607a
basketball
dcddb75469b4b4875094e14561e573d8
000000
e10adc3949ba59abbe56e057f20f883e
123456
e19d5cd5af0378da05f63f891c7467af
abcd1234
e99a18c428cb38d5f260853678922e03
abc123
fcea920f7412b5da7be0cf42b8c93759
1234567
Los sitios web como Crackstation utilizan internamente enromes tablas de arco iris para proporcionar un descifrado rápido de contraseñas para hashes sin “salt”. Hacer una búsqueda en una lista ordenada de hash es bastante rápido, mucho más rápido que intentar descifrar el hash.
Protección contra las tablas del arco iris
Para protegernos contra las tablas de arcoíris, agregamos lo que se le llama comúnmente, “granitos de sal”, salt en inglés, a las contraseñas. La salt se genera aleatoriamente y se almacena en la base de datos, única para cada usuario. En teoría, podría usar la misma salt para todos los usuarios, pero eso significa que las contraseñas duplicadas aún tendrían el mismo hash, y aún se podría crear una tabla de arco iris con contraseñas específicas con esa salt.
La salt se agrega al inicio o al final de la contraseña antes de que se convierta en hash, y esto significa que cada usuario tendrá un hash de contraseña diferente incluso si tienen la misma contraseña. Las funciones hash como bcrypt y sha512crypt manejan esto automáticamente. Ya que las salt no necesitan mantenerse en privado.
Los hashes en los sistemas operativos
Los hashes de contraseña de estilo Unix son muy fáciles de reconocer, ya que tienen un prefijo. El prefijo le indica el algoritmo hash utilizado para generar el hash. El formato estándar es $format$rounds$salt$hash.
Las contraseñas de Windows se codifican mediante NTLM, que es una variante de md4. Son visualmente idénticos a los hashes md4 y md5, por lo que es muy importante usar el contexto para calcular el tipo de hash.
En Linux, los hash de contraseña se almacenan en /etc/shadow. Este archivo normalmente solo es legible por root. Solían almacenarse en /etc/passwd y todos podían leerlos. Por tal motivo se separaron estos archivos en dos partes el /etc/shadow y el /etc/passwd.
md5crypt, utilizado en cosas de Cisco y sistemas Linux/Unix más antiguos
$2$, $2a$, $2b$, $2x$, $2y$
Bcrypt (Popular para aplicaciones web)
$6$
sha512crypt (predeterminado para la mayoría de los sistemas Linux/Unix)
En Windows, los hashes de contraseña se almacenan en la SAM. Windows intenta evitar que los usuarios normales los descarguen, pero existen herramientas como mimikatz para poder hacerlo, o pwdump. Es importante destacar que los hashes que se encuentran allí se dividen en hashes NT y hashes LM.
Un gran lugar para encontrar más formatos de hash y prefijos de contraseña es la página de ejemplo de Hashcat, disponible aquí.
Para otros tipos de hash, normalmente tendrá que ir por longitud, codificación o alguna investigación sobre la aplicación que los generó. Nunca subestimes el poder de la investigación.
Comprobando la integridad
El hash se puede utilizar para comprobar que los archivos no se han modificado. Si ingresas los mismos datos, siempre obtendrás los mismos datos. Si cambia incluso un solo bit, el hash cambiará mucho. Esto significa que puede usarlo para verificar que los archivos no hayan sido modificados o para asegurarse de que se hayan descargado correctamente. También puede usar hash para encontrar archivos duplicados, si dos imágenes tienen el mismo hash, entonces son la misma imagen.
HMAC
HMAC es un método de uso de una función hash criptográfica para verificar la autenticidad e integridad de los datos. Por ejemplo hay VPN que usan HMAC-SHA512 para la autenticación de mensajes, que puede ver en la salida del terminal. Se puede usar un HMAC para garantizar que la persona que creó el HMAC sea quien dice ser (autenticidad) y que el mensaje no se haya modificado ni dañado (integridad). Utilizan una clave secreta y un algoritmo hash para producir un hash.
Conclusión
Como hemos visto, la criptografía juega un papel fundamental en muchos órdenes de nuestra vida, sobre todo en la protección de contraseñas y la privacidad de la información.
Actualmente es muy importante, quizás hace 20 años el resguardo de datos no era tan fundamental, pero actualmente, sí lo es. Prácticamente, proveedores de servicios como Google Drive, Mega, y en general, cualquier proveedor de almacenamiento en la nube, utiliza la criptografía para resguardar la información de sus clientes.
Es por ello que, la mayoría de estos proveedores utilizan el SSL para resguardar el envío que ocurre entre servidor y usuario; una vez que la información se encuentra en sus bases de datos, estos utilizan diferentes tipos de criptografía, para evitar que terceros puedan acceder a ella. Asimismo, estas plataformas en cuestión poseen cifrado en su codificación, para evitar que agentes externos puedan tener acceso a enlaces o líneas de código delicadas.
Incluso, los discos duros y memorias externas poseen tecnología de cifrado, pero esta sólo ocurre cuando se resguarda una carpeta con contraseña en la base de datos del disco o en la memoria; de esta forma, en lugar de guardarse la contraseña como fue escrita, esta se cifra mediante hash, para evitar que algún programa externo la pueda obtener.
No hay actividad que se realice el día de hoy que no use la criptografía. Por lo que convierte esta ciencia en algo fundamental para proteger la seguridad de la información.
Ahora que tienes los conceptos de criptografía es hora de que conozcas algunas palabras que encontrarás seguido dentro de la ciberseguridad, relacionado con la criptografía. Muchas veces te podrás encontrar con palabras como:
Plaintext: Son los datos antes de ser cifrado, texto sin formato, a menudo texto, pero no siempre, ya que podría ser una fotografía u otro archivo en su lugar.
Encoding: Esta NO es una forma de encriptación, solo una forma de representación de datos como base64 o hexadecimal. Inmediatamente reversible.
Hash: El hash es el resultado de una función hash. Hashing también se puede usar como un verbo, “to hash”, que significa producir el valor hash de algunos datos.
Brute Force: Atacar la criptografía probando cada contraseña diferente o cada clave diferente en español, “fuerza bruta”.Cryptanalysis: atacar la criptografía al encontrar una debilidad en las matemáticas subyacentes.
Hablando de Hash
¿Qué es una función hash?
Un hash es el resultado de una función hash, la cual es una operación criptográfica que genera identificadores únicos e irrepetibles a partir de una información dada. Los hashes son una pieza clave en la tecnología blockchain y tiene una amplia utilidad.
El nombre de hash se usa para identificar una función criptográfica muy importante en el mundo informático. Estas funciones tienen como objetivo primordial codificar datos para formar una cadena de caracteres única. Todo ello sin importar la cantidad de datos introducidos inicialmente en la función. Estas funciones sirven para asegurar la autenticidad de datos, almacenar de forma segura contraseñas, y la firma de documento electrónicos.
Las funciones hash son ampliamente utilizadas en la tecnología blockchain con el fin de agregar seguridad a las mismas. El Bitcoin, es un claro ejemplo de cómo los hashes pueden usarse para hacer posible la tecnología de las criptomonedas.
Una función hash toma algunos datos de entrada de cualquier tamaño y crea un resumen o “resumen” de esos datos. La salida tiene un tamaño fijo. Es difícil predecir cuál será la salida para cualquier entrada y viceversa. Los buenos algoritmos hash serán (relativamente) rápidos de calcular y lentos de revertir (pasar de la salida y determinar la entrada). Cualquier pequeño cambio en los datos de entrada (incluso un solo bit) debería causar un gran cambio en la salida.
La salida de una función hash normalmente son bytes sin formato, que luego se codifican. Las codificaciones comunes para esto son base 64 o hexadecimal. Descifrarlos no te dará nada útil.
¿Por qué debería importarme?
El Hashing se usa muy a menudo en ciberseguridad. Cuando iniciaste sesión en este portal, se usó una función hash para verificar tu contraseña. Cuando iniciaste sesión en tu ordenador, también se usó una función hash para verificar tu contraseña. Interactúas indirectamente con hashes más de lo que crees, principalmente en el contexto de las contraseñas.
Historia de las funciones Hash
La aparición de la primera función hash data del año 1961. En ese entonces, Wesley Peterson creó la función Cyclic Redundancy Check (Comprobación de Redundancia Cíclica). Fue creada para comprobar cómo de correctos eran los datos transmitidos en redes (como Internet) y en sistema de almacenamiento digital. Fácil de implementar y muy rápida, ganó aceptación y es hoy un estándar industrial. Con la evolución de la informática y los computadores, estos sistemas se fueron especializando cada vez más.
Esto permitió crear nuevas y mejores funciones hash entre las que se pueden destacar:
MD2: es una de las primeras funciones hash criptográficas. Creada por Ronald Rivest, en el año de 1989. Con un alto nivel de eficiencia y seguridad para el momento, era fundamental en la seguridad de Internet. Su consecuente evolución llevó a la creación de la función hash MD5. La cual es aún usada en ambientes donde la seguridad no es una alta prioridad.
RIPEMD: es una función hash criptográfica creada por el proyecto europeo RIPE en el año de 1992. Su principal función era la de sustituir al estándar del momento, la función hash MD4. En la actualidad aún se considera muy seguro, especialmente en sus versiones RIPEMD-160, RIPEMD-256 y RIPEMD-320.
SHA: el estándar actual de hashes criptográficos. Creada por la NSA en 1993, como parte de su proyecto interno para autentificar documentos electrónicos. SHA y sus derivadas son consideradas las funciones hash más seguras hasta el momento. Es de especial interés, SHA-256 por ser fundamental en la tecnología que hizo posible el Bitcoin.
Funciones Hash – ¿Cómo funcionan?
Las funciones hash funcionan gracias a una serie de complejos procesos matemáticos y lógicos. Estos procesos, son trasladado a un software de ordenador con el fin de usarlos desde el propio ordenador. Desde allí, podemos tomar cualquier serie de datos, introducirlos en la función y procesarlos. Con esto se busca obtener una cadena de caracteres de longitud fija y única para los datos introducidos. A la vez que se hace prácticamente imposible realizar el proceso contrario. Es decir, es prácticamente imposible obtener los datos originales desde un hash ya formado. Esto gracias a que el proceso de creación de hashes, es un proceso de un solo sentido.
Un ejemplo sencillo y de la vida diaria de este proceso sería; la realización de un pastel. Cada uno de los ingredientes del pastel, sería el equivalente a la entrada de datos. El proceso de preparación y cocción del pastel, sería el proceso de codificación de dichos datos (ingredientes) por la función. Al finalizar, obtenemos un pastel con características únicas e irrepetibles dadas por los ingredientes del mismo. Mientras que el proceso contrario (llevar al pastel a su estado de ingredientes inicial), es prácticamente imposible de realizar.
Un ejemplo visual del proceso se puede mostrar usando las funciones MD5 y SHA-256, en dos casos de uso distintos.
YourString
En Sevilla el cielo es azul
MD5 HASH
65767deb8910279f82dc925a5c48d478
YourString
En Sevilla el cielo es azul.
MD5 HASH
c72fe934e8e43e653b15b129530ab8cd
Una explicación más cercana
Observando ambos casos de uso podemos notar lo siguiente:
La primera entrada de datos, da como resultado un hash único, para los casos de MD5 y SHA-256. Resultados que están ajustados a la realidad de cada una de esas funciones. En la segunda entrada se ha realizado una pequeña modificación en el texto. Esta, aunque es mínima, alteró completamente el resultado de los hashes para MD5 y SHA-256.
Esto prueba que los hashes serán únicos en todo caso. Lo que nos permite estar seguros, de que ningún actor malicioso podrá forzar hashes de forma sencilla. Aunque lograr esto no sea imposible, un ciberdelincuente podría pasar cientos de años procesando datos para lograr su cometido.
Son estas dos observaciones las que nos dan la seguridad de usar este método en distintas áreas sensibles. Certificados digitales, firmas únicas de documentos sensibles o secretos, identificación digital y almacenamiento de claves, son algunos casos de uso. Pero no se detiene allí, puesto que la flexibilidad y seguridad de esta tecnología la hace idónea en muchas áreas.
Características de las funciones de hash
Entre las principales características de las funciones hash, se pueden mencionar las siguientes:
Son fáciles de calcular. Los algoritmos de hash son muy eficientes y no requieren de gran potencia de cálculo para ejecutarse.
Es compresible. Esto quiere decir que, sin importar el tamaño de la entrada de datos, el resultado siempre será una cadena de longitud fija. En el caso de SHA-256, la cadena tendrá una longitud de 64 caracteres.
Funcionamiento tipo avalancha. Cualquier mínimo cambio en la entrada de datos, origina un hash distinto a la entrada de datos original.
Resistencia débil y fuerte a colisiones. Hace referencia a que es imposible calcular un hash, que permita encontrar otro hash igual. Mejores conocidos como pre-imagen y segunda preimagen, es el concepto base de la seguridad de los hashes.
Son irreversibles. Tomar un hash y obtener los datos que dieron origen al mismo, en la práctica no puede ser posible. Esto es uno de los principios que hacen a los hashes seguros.
Nivel de seguridad de las funciones hash
Las actuales funciones hash tienen un alto nivel de seguridad, aunque esto no significa que sean infalibles. Un buen ejemplo de esto es; la función hash MD5. En principio, las especificaciones de la misma prometían una seguridad muy alta. Su uso se extendió en Internet por la necesidad de un sistema de hash para mantener su seguridad. Pero en el año 1996, se pudo romper la seguridad de la función. Con ello quedó obsoleta y se recomendó abandonar su uso.
Por otro lado, funciones como RIPEMD-160 ySHA-256, son tan complejas que su seguridad aún está garantizada. Por ejemplo, para SHA-256 se calcula que para romper su seguridad harían falta miles de años usando supercomputadores actuales. Lo mismo aplica en el caso de RIPEMD-160 y sus consecuentes evoluciones. Esto significa que ambas funciones aún brindan un alto nivel de seguridad y pueden utilizarse sin problemas.
Pero pese a que estas funciones son muy seguras, no significa que no se investiguen y desarrollen otras más opciones. Esta constante evolución nos dice que siempre tendremos a disposición herramientas seguras para usar, en cualquier caso.
¿Qué es una colisión de hash?
Una colisión hash es cuando 2 entradas diferentes dan la misma salida. Las funciones hash están diseñadas para evitar esto lo mejor que pueden, especialmente para poder diseñar (crear intencionalmente) una colisión. Debido al efecto casillero, las colisiones no son evitables. El efecto de casillero es básicamente, hay un número determinado de valores de salida diferentes para la función hash, pero puede darle cualquier tamaño de entrada. Como hay más entradas que salidas, algunas de las entradas deben dar la misma salida. Si tiene 128 palomas y 96 casilleros, algunas de las palomas tendrán que compartir casilla.
MD5 y SHA1 han sido atacados y se han vuelto técnicamente inseguros debido a colisiones de hash. Sin embargo, ningún ataque ha provocado una colisión en ambos algoritmos al mismo tiempo, por lo que, si usa el hash MD5 Y el hash SHA1 para comparar, verá que son diferentes. El ejemplo de colisión MD5 está disponible en https://www.mscs.dal.ca/~selinger/md5collision/ y los detalles de la colisión SHA1 están disponibles en https://shattered.io/. Debido a esto, no debe confiar en ninguno de los algoritmos para cifrar contraseñas o datos.
Las funciones hash en el mundo Blockchain
Difícil no hablar del blockchain en los tiempos que corres, gracias a que son rápidos, eficientes, económicos computacionalmente y únicos, las funciones de hash son muy usadas en la tecnología blockchain. Cuando Satoshi Nakamoto publicó su whitepaper de Bitcoin, explicó el porque y como uso de SHA-256 y RIPEMD-160 en Bitcoin. Desde entonces, la tecnología blockchain ha evolucionado mucho, pero las bases siguen siendo las mismas. Hacer uso de criptografía fuerte y hashes para que la tecnología sea muy segura, privada e incluso anónima.
De todos los usos de las funciones de hash en blockchain se pueden destacar los siguientes casos:
Creación de la dirección (Address Wallet): Las direcciones de los monederos de criptomonedas, son una representación segura de las claves públicas de la cartera. Las claves públicas, por lo general son muy largas y complejas. Es por esta razón; que las blockchains utilizan funciones de hash para derivar una dirección más corta. Este proceso se usa en varias ocasiones para acortar la dirección y agregar una capa extra de seguridad. En Bitcoin, el proceso de crear una dirección de monedero, usa las funciones hash RIPEMD-160 y SHA-256. Ambas son usadas para mejorar la seguridad del proceso y hacer que las mismas sean únicas e irrepetibles.
Proceso de Minería: El proceso de minería, es otra etapa importante de la tecnología blockchain donde se usan las funciones hash. En Bitcoin, la minería hace un uso intensivo de cálculo de hashes SHA-256 de forma distribuida en cada uno de sus nodos. Los mineros, son los responsables de calcular millones de hashes para crear nuevos bloques Bitcoin. El proceso también se usa para verificar las transacciones que se hacen en la red.
Si bien el proceso de calcular hashes es muy rápido, su uso intensivo dificulta el proceso drásticamente. Esto lleva a los mineros a usar un alto poder de cómputo para resolver los acertijos Bitcoin. Al resolverlos, los mineros son recompensados con 6,25 BTC por bloque.
Siguiendo con la trayectoria bélica, la II Guerra Mundial fue otro de los escenarios donde la criptografía fue protagonista. Se construyeron varias máquinas de cifrado, como las máquinas Enigma y Lorentz en Alemania. Hubo otras, como Púrpura y Jade en Japón.
Por su popularidad e importancia en la historia se va a ahondar más en el cifrado de la máquina Enigma. Esta máquina se utilizó durante la Segunda Guerra Mundial para cifrar y descifrar los mensajes que se intercambiaban durante la guerra.
En la foto se muestra un ejemplar de máquina Enigma. Como puede verse, es parecida a una máquina de escribir. Está compuesta por un tablero de clavijas, el teclado, un panel luminoso en el que aparece iluminada la letra a la que se corresponde cifrada la tecla pulsada, además de los modificadores y rotores.
Es una máquina que realiza varias operaciones para el cifrado de cada carácter, lo que hace que el número de combinaciones posibles sea ciertamente elevado. Además, se utilizaba una clave de cifrado que cambiaba cada 8 horas, lo que complicaba aún más su criptoanálisis.
Alan Turing, considerado uno de los padres de la computación, junto a otros expertos, fueron protagonistas en el proceso de criptoanálisis de la máquina Enigma para descifrar los códigos nazis. Fue en Bletchley Park donde construyeron la llamada “bomba de Turing” y junto a su potencia y algunos fallos en el uso de Enigma fue posible descifrar los mensajes de los alemanes en la Segunda Guerra Mundial. Se estima que este hecho fue capaz de acortar en 2 o 3 años la duración de la guerra.
Otra de las técnicas usadas durante la Segunda Guerra Mundial fue la utilización de lenguas poco extendidas para ocultar de esta forma los mensajes secretos. En particular se usó el idioma de los indios navajos. Se estima que lo hablaban únicamente unos 4000 indios, por lo que era una lengua bastante desconocida y difícil de entender por el resto del mundo. El código estaba hecho a de palabras o frases en idioma navajo, que luego era traducido al inglés.
Éstos son algunos de los aspectos más destacables de la historia de la criptografía, aunque obviamente hay muchos más que no se han reflejado aquí en pro de no extenderse demasiado. El alumno interesado puede investigar más por su cuenta.
Todos estos hechos forman parte de lo que se llama la criptografía precientífica, la cual tenía en cierta medida una componente artística. Es a partir de que Shannon en 1949 propusiera sus postulados cuando se empieza a hablar de la criptografía científica. Estos aspectos se estudiarán con más detalle en el resto de esta asignatura.
SEGURIDAD CRIPTOGRÁFICA
En relación a la seguridad criptográfica se puede distinguir entre los siguientes conceptos:
Incondicional (teórica). El sistema es seguro frente a atacantes con tiempo y recursos computacionales ilimitados. Actualmente el único sistema conocido que cumple estas características es el cifrado de Vernam.
Computacional (práctica). Es seguro frente a atacantes con tiempo y recursos computacionales limitados. Un ejemplo de este tipo de sistemas es RSA.
Seguridad probable. No se puede demostrar su seguridad pero el sistema no ha sido violado. Un ejemplo es el algoritmo DES.
Seguridad condicional. Los demás sistemas. Por ejemplo, los algoritmos clásicos, que eran seguros mientras que un atacante no tenía medios para romperlos. Una de las diferencias entre la criptografía clásica y la moderna es que la primera ofrecía sistemas con seguridad probable mientras que, a día de hoy, con los avances en el criptoanálisis y la capacidad cada vez mayor de los sistemas computacionales es necesario que la seguridad sea matemáticamente demostrable.
CRIPTOANÁLISIS
Como se comentó el criptoanálisis persigue romper el cifrado y obtener ilegítimamente el mensaje original a partir del criptograma.
Antiguamente, para preservar la seguridad de los mensajes intercambiados, el funcionamiento del procedimiento criptográfico se escondía para evitar que los atacantes conocieran el método y pudieran emplearlo para leer los mensajes. La desventaja que tiene este método es que, si el algoritmo de cifrado fuese revelado, filtrado o se utilizase ingeniería inversa, un atacante podría tomar ventaja de esto y comprometer el mensaje original.
Para evitar esto en el S XIX se enunció el principio de Kerckhoffs, que dice lo siguiente:
“El atacante tiene pleno conocimiento del método de cifrado con excepción de la clave”.
Esto da un vuelvo al concepto anterior. De hecho, a día de hoy se garantiza la seguridad de los algoritmos de cifrado al hacerlos públicos y retar a que se rompan. De este modo la seguridad reside únicamente en la clave de cifrado y no en el ocultismo del modo de funcionamiento del algoritmo.
Los ataques pueden clasificarse en función a varios criterios. La primera clasificación diferencia entre los ataques pasivos y los activos.
Los ataques pasivos son aquellos en los que el atacante monitoriza el canal de comunicación (ataque a la confidencialidad) pero no interviene sobre la información.
Ataques activos. A diferencia de los anteriores, en este caso el atacante intenta modificar la información intercambiada, añadiendo, borano o alterando los mensajes enviados (esto supone un ataque a la confidencialidad, integridad y autenticidad).
Otra clasificación es la siguiente:
Ataque sobre texto cifrado únicamente. En este ataque pasivo el atacante solo tiene acceso al criptograma. Tiene un conocimiento mínimo del mensaje original (como el idioma). Un buen método de cifrado no debería ser vulnerable a este ataque.
Ataque sobre texto claro conocido. En este caso el atacante conoce una porción del texto claro, así como su correspondiente texto cifrado. Partiendo de esta información el atacante tiene como objetivo el deducir la clave o descifrar una nueva fracción del texto claro.
Ataque adaptativo. Este ataque es una variante del anterior. En este caso el atacante puede obtener nuevo texto cifrado en función de otros criptogramas obtenidos anteriormente. Todos los textos cifrados corresponden a textos claros de su propia elección. Aunque este escenario no es muy realista tiene interés teórico.
La eficacia de un ataque criptoanalítico se mide por varios factores:
Cantidad de pares texto claro y texto cifrado necesarios.
Tiempo para criptoanálisis.
Probabilidad de éxito del ataque.
EJEMPLO DE CRIPTOANÁLISIS
Un ejemplo de criptoanálisis se encuentra en el libro “El escarabajo de oro”, escrito por Edgar Alan Poe en 1843. Este libro explica detalladamente cómo se puede romper un procedimiento de cifrado mediante técnicas estadísticas. La obra relata una historia en la que se debe descifrar un mensaje secreto para encontrar la localización de un tesoro escondido.
El criptograma que aparece en el libro es el siguiente:
53‡‡†305))6;4826)4‡.)4‡);806;48†8¶
60))85;1‡(;:‡8†83(88)5†;46(;8896?;
8)‡(;485);5†2:‡(;49562(5-4)8¶8
;4069285);)6†8)4‡‡;1(‡9;48081;8:8‡1;48
†85;4)485†528806*81(‡9;48;(88;4(‡?34
;48)4‡;161;:188;‡?;
Vamos a ver de qué manera es posible criptoanalizar este criptograma.
Realizando un análisis de frecuencias se sabe que la letra más usada en la lengua inglesa es la letra “e”.
Analizando el criptograma se puede ver que el carácter más repetido es el “8”, por tanto se hace la asociación e → 8. De esta forma se sustituyen todas las apariciones de 8 en el criptograma por la letra “e”. El texto quedaría como sigue:
Para continuar se tiene en cuenta que la palabra “the” es la más habitual en el idioma inglés. Por tanto, se debe buscar en el criptograma el patrón 8, siendo * cualquier carácter. Se ve que en el criptograma aparece 7 veces repetido el patrón “;48”, de lo cual se deduce la siguiente asociación
t → ; h → 4 e → 8
En el criptograma se puede ver “;(88;4”. Tenemos todos los caracteres correspondientes excepto “(“. Como la “h” la asociamos a “4”, se deduce que el “(” no es “h”. Entonces se reduce a “;(88”. Esto encaja con la palabra “tree”, lo cual relaciona
r->(
Sustituyendo se obtiene: “the tree thrh the”. De donde se deduce la palabra “trough” que da lugar a las
asociaciones o → ‡ u → ? g
->3
Buscando en el texto se encuentra 83(88) egree. Asociando la palabra degree se obtiene una nueva letra d → +
Luego se ve la combinación 46 (; 88. Sustituyendo se obtiene th rtee*, lo cual sugiere la palabra “thirteen” y que permite obtener más asociaciones i → 6 n → *
De “5good” se deduce a → 5 Sustituyendo los símbolos en el criptograma se obtiene el texto original:
“A good glass in the bishop’s hostel in the devil’s seat forty-one degrees and thirteen minutes northeast and by north main branch seventh limb east side shoot from the left eye of the death’s-head a bee line from the tree through the shot fifty feet out.”
Lo cual nos lleva a la localización del tesoro ☺
CONDICIONES DE SECRETO PERFECTO
En 1949 Shannon enunció las condiciones de secreto perfecto, las cuales reflejan en forma matemática la seguridad de un sistema criptográfico. Estas condiciones se basan en dos hipótesis fundamentales
La clave se utilizará solamente una vez.
El atacante sólo tiene acceso al criptograma.
Tomando esto como base, se dice que un sistema criptográfico cumple las condiciones de secreto perfecto si el texto claro X es estadísticamente independiente del criptograma Y, para todos los posibles textos claros y todos los posibles criptogramas.
Matemáticamente se expresa como P(X = x | Y = y) = P(X = x)
Esto refleja que el valor tomado por la variable X es el mismo con o sin el conocimiento de la variable Y. Dicho de otra manera, el criptograma no aporta información sobre el texto claro a un criptoanalista, independientemente de los recursos y tiempo de los que disponga.
Shannon, conocido como padre de la teoría de la información, introdujo el concepto de entropía. Ésta mide la incertidumbre de una fuente de información y es un concepto bastante usado en criptografía. Basándose en la entropía, Shannon determinó cuál era la longitud mínima de la clave para que se pudieran dar las condiciones de secreto perfecto. El resultado es que la longitud de la clave tiene que ser al menos tan larga como la longitud del texto claro. Esto es, K >= M, siendo K la longitud de la clave y M la del mensaje original.
CIFRADORES ADITIVOS
Los cifradores aditivos módulo L verifican las condiciones de cifrado perfecto.
Dado un alfabeto {0, 1, …, L-1} para el texto claro y criptograma, sea X el texto claro, Y el texto cifrado, Z la clave, M la longitud del texto claro, N la longitud del criptograma y K la longitud de la clave.
Debe darse que M=K=N.
La clave Z debe elegirse de forma aleatoria.
La transformación de cifrado se realiza aplicando una operación XOR entre cada elemento del texto claro y la clave.
A cada texto claro X le puede corresponder, con igual probabilidad, cualquiera de los LM posibles criptogramas. Por tanto, la información aportada por el criptograma sobre el texto claro es nula, esto es, X e Y son estadísticamente independientes.
CONCLUSIONES
La criptografía está relacionada códigos secretos, con cómo cifrar y descifrar mensajes de modo que sólo el destinatario pueda acceder al mensaje, de modo que se proteja la información.
La criptografía tiene origen alrededor del S. V a. C. y ha ido evolucionando a lo largo del tiempo, dando lugar a sistemas cada vez más sofisticados. Ha habido muchos sistemas criprotográficos a lo largo de la historia y en este capítulo se han repasado algunos de los más importantes, analizando su funcionamiento y características, así como los puntos débiles que los pueden hacer sucumbir ante un ataque criptoanalítico.
Se han repasado también conceptos relativos al criptoanálisis y las condiciones de secreto perfecto así como el funcionamiento de los cifradores aditivos un repaso de cuáles son las aplicaciones más importantes de la criptografía.
Bienvenido a este curso de criptografía. La criptografía es un método de protección de la información y las comunicaciones mediante el uso de códigos, de modo que solo aquellos a quienes está destinada la información puedan leerla y procesarla. El prefijo «cripta-» significa «oculto» o «bóveda» – y el sufijo «-grafía» significa «escritura».
En informática, la criptografía se refiere a técnicas de comunicación e información seguras derivadas de conceptos matemáticos y cálculos basados en reglas llamados algoritmos, para transformar los mensajes en formas difíciles de descifrar.
Estos algoritmos deterministas se utilizan para la generación de claves criptográficas, firma digital, verificación para proteger la privacidad de los datos, navegación web en Internet y comunicaciones confidenciales como transacciones con tarjetas de crédito y correo electrónico.
Haciendo un poco de historia
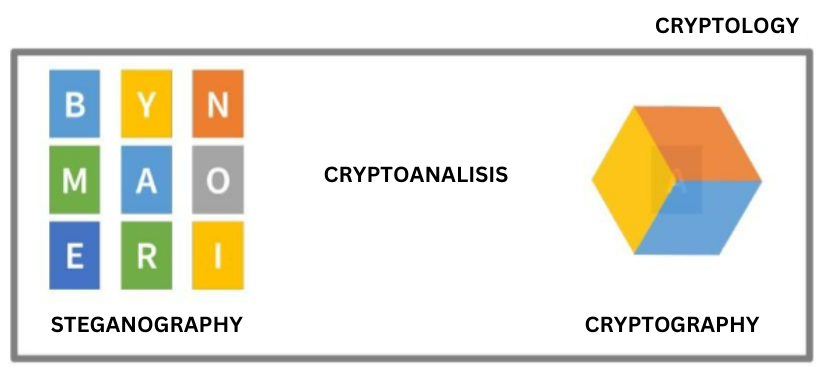
El término criptología proviene del griego krypto: ‘oculto’ y logos: ‘palabra’. Es la ciencia de la escritura secreta (criptografía), de la escritura oculta (esteganografía) y de su revelación no autorizada (criptoanálisis). Por lo que podemos representar estos tres términos como en la siguiente imagen.
Como ves, la criptología engloba a la criptografía y al criptoanálisis:
La criptografía diseña algoritmos de cifrado para proteger la información.
El criptoanálisis intenta romper dichos métodos de cifrado para recuperar la información original.
Existe otro término no menos importante que también debes manejar y son los criptogramas:
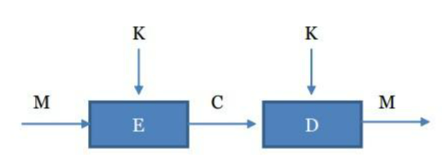
Los elementos que forman parte de un criptosistema son:
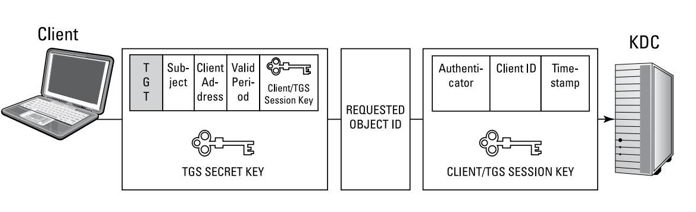
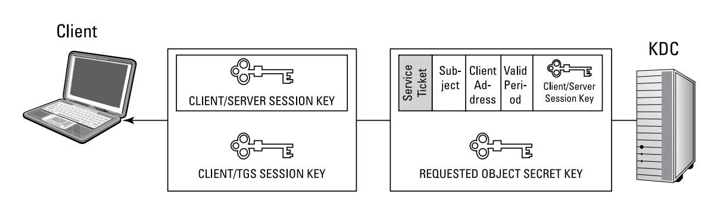
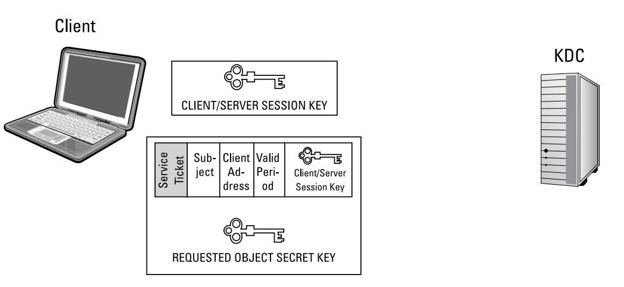
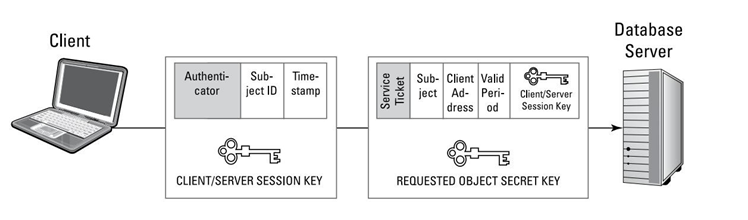
M: que representa el mensaje o texto en claro, que por sí solo es legible o interpretable por cualquier que tenga acceso a él.
C: que representa al criptograma, esto es el texto cifrado que se trasmitirá por el canal de comunicación, el cual por definición es inseguro y por ello es necesario cifrar la información.
E: que representa la función de cifrado que se aplica al texto en claro. La letra E proviene del inglés Encrypt.
D: que representa la función de descifrado que se aplica al texto cifrado para recuperar el texto en claro. La letra D proviene del inglés Decrypt.
K: que representa la clave empleada para cifrar el texto en claro M, o bien para descifrar el criptograma C. En los sistemas modernos de cifra asimétrica o de clave pública, estas claves K serán diferentes en ambos extremos.
Hay que destacar que, a pesar de los siglos, los sistemas de cifra clásicos y los modernos o actuales se diferencian muy poco entre sí. En el fondo, hacen las mismas operaciones, si bien los primeros estaban orientados a letras o caracteres, y los segundos lógicamente a bits y bytes. Pero los principios en los que se basan para conseguir su objetivo de enmascarar la información siguen siendo los mismos, la difusión y la confusión.
La difusión pretende difundir las características del texto en claro en todo el criptograma, ocultando así la relación entre el texto en claro y el texto cifrado, y se logra mediante técnicas de cifra por permutación o transposición.
Por su parte, la confusión pretende confundir al atacante, de manera que no le sea sencillo establecer una relación entre el criptograma y la clave de cifrado, y se logra mediante técnicas de cifra por sustitución.
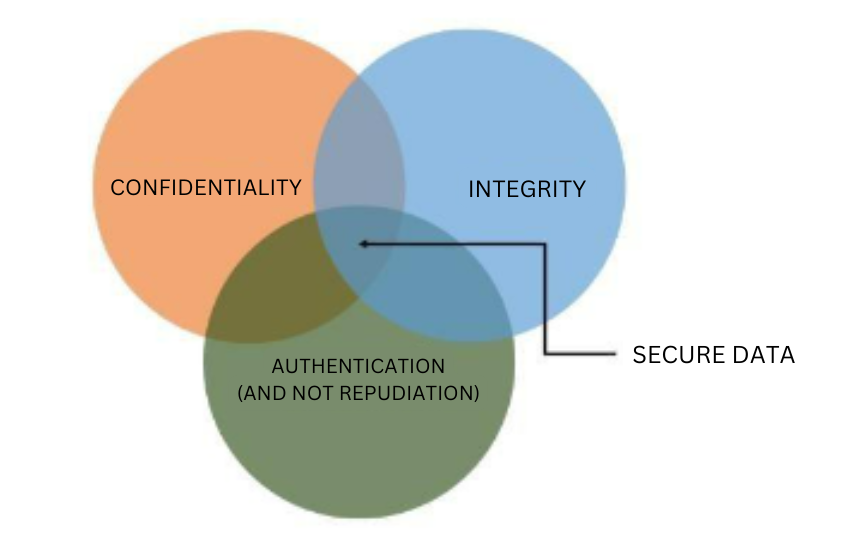
Los cuatro servicios de seguridad que te proporciona la criptografía
La criptografía puede utilizarse para ayudar a proporcionar los siguientes servicios de seguridad:
Confidencialidad: se ocupa de detectar y disuadir la divulgación no autorizada de información, vamos, de mantener los secretos en secreto: tengo información y no quiero que nadie más la descubra a menos que yo se la revele. Los algoritmos de cifrado abordan directamente el problema de la confidencialidad. Estos algoritmos aceptan una clave secreta y luego proceden a cifrar el mensaje original, conocido como texto claro, y lo convierten en una información ininteligible conocida como texto cifrado, de tal manera que sólo el destinatario previsto, y nadie más, puede leerlo.
Integridad: se ocupa de detectar e impedir la modificación no autorizada de la información. Con criptografía se realiza una firma digital de la información y basta que un solo bit de los datos cambie para que la firma sea diferente. Esto permite a las partes que se comunican realizar comprobaciones de integridad con respecto a su información y asegurarse de que nada ha cambiado durante el trayecto o una vez almacenada. Las funciones de hash suelen constituir una pieza clave de las firmas digitales.
Autenticación: es la propiedad de atribuir una identidad al remitente de un mensaje o al autor de una acción. Uno de los métodos criptográficos preferidos para autenticar a las partes es mediante certificados digitales. Se basan en dos bloques de construcción básicos: las funciones de hash y el cifrado de clave pública, que se verán más adelante.
El no repudio asegura que el remitente no puede negar haber enviado el mensaje.
Una de las finalidades de la criptografía es mantener la confidencialidad del mensaje, esto es, garantizar que la información es accesible únicamente para aquellos autorizados a tener acceso. Otra es garantizar la integridad del criptograma, es decir, que éste no sufra ningún tipo de alteración o modificación. Así como garantizar la autenticidad del emisor y receptor, que se refiere a verificar que efectivamente se trata de las personas o entes que envían el mensaje o lo reciben.
FUNDAMENTOS DEL CIFRADO
Históricamente, el primer método utilizado para proteger la información consistía en esconder el texto secreto. Estaba oculto a plena vista. Este método se llama esteganografía.
La esteganografía (del griego στεγανος steganos, “cubierto” u “oculto”, y γραφος graphos, “escritura”) trata el estudio y aplicación de técnicas que permiten ocultar mensajes u objetos, dentro de otros, llamados portadores, de modo que no se perciba su existencia. Es decir, procura ocultar mensajes dentro de otros objetos y de esta forma establecer un canal encubierto de comunicación, de modo que el propio acto de la comunicación pase inadvertido para observadores que tienen acceso a ese canal.
Una forma de diferenciar la esteganografía con la criptografía común es que la criptografía solo cifra los archivos manteniendo el archivo original visible, pero al abrirlo mostrará una secuencia de caracteres que no permitirá su lectura y para ver su contenido original es necesario conocer la clave. En la esteganografía, puede verse un archivo con un formato diferente, y para conocer su contenido original será necesario conocer la clave y el software con el que se ocultó.
Esta ciencia ha suscitado mucho interés en los últimos años, especialmente en el área de seguridad informática, debido a que ha sido utilizada por organizaciones criminales y terroristas. No obstante, no se trata de nada nuevo, pues se lleva empleando desde la antigüedad, y tradicionalmente la han utilizado las instituciones policíacas, militares y de inteligencia, y también criminales o civiles que desean evadir el control gubernamental, especialmente en regímenes tiránicos.
La esteganografía clásica se basaba únicamente en el desconocimiento del canal encubierto utilizado, mientras que en la era moderna también se emplean canales digitales (imagen, video, audio y protocolos de comunicaciones, entre otros) para alcanzar el objetivo. En muchos casos, el objeto contenedor es conocido, y lo que se ignora es el algoritmo de inserción de la información en dicho objeto.
ESTEGANOGRAFÍA CLÁSICA Y MODERNA
Esteganografía “clásica”:Protección basada en desconocer el canal encubierto específico que se está usando. Esteganografía moderna: uso de canales digitales:
Archivo de texto (páginas web, código fuente, etc.)
La esteganografía pura no requiere el intercambio de un cifrado como un stego-key. Se asume que ninguna otra parte tiene conocimiento de la comunicación.
De clave secreta
Aquí la clave secreta (stego) se intercambia antes de la comunicación. Esto es más susceptible a la interceptación. La esteganografía de clave secreta toma un mensaje de cobertura e incrusta el mensaje secreto dentro de él mediante el uso de una clave secreta (stego-key). Solo las partes que conocen la clave secreta pueden revertir el proceso y leer el mensaje secreto.
De clave pública
En este caso se utiliza una clave pública y una clave privada para una comunicación segura. El remitente utilizará la clave pública durante el proceso de codificación y solo la clave privada, que tiene una relación matemática directa con la clave pública, puede descifrar el mensaje secreto.
TÉCNICAS ESTEGANOGRÁFICAS
Existen muchas técnicas para ocultar información. A continuación explicamos las más habituales.
Enmascaramiento
En este caso la información se oculta dentro de una imagen digital usando marcas de agua donde se introduce información, como el derecho de autor, la propiedad o licencias. El objetivo es diferente de la esteganografía tradicional, lo que se pretende es añadir un atributo a la imagen que actúa como cubierta. De este modo se amplía la cantidad de información presentada.
Algoritmos de la compresión de datos
Esta técnica oculta datos basados en funciones matemáticas que se utilizan a menudo en algoritmos de la compresión de datos. La idea de este método es ocultar el mensaje en los bits de datos menos importantes.
Métodos de sustitución
Una de las formas más comunes de hacer esto es alterando el bit menos significativo (LSB). En archivos de imagen, audio y otros, los últimos bits de información en un byte no son necesariamente tan importantes como los iniciales. Por ejemplo, 10010010 podría ser un tono de azul. Si solo cambiamos los dos últimos bits a 10010001, podría ser un tono de azul que es casi exactamente igual.
Esto significa que podemos ocultar nuestros datos secretos en los dos últimos bits de cada píxel de una imagen, sin cambiar la imagen de forma notable. Si cambiamos los primeros bits, lo alteraría significativamente. El método del LSB funciona mejor en los archivos de imágenes que tienen una alta resolución y usan gran cantidad de colores. En caso de archivos de audio, favorecen aquellos que tienen muchos y diferentes sonidos que poseen una alta tasa de bits.
Además, este método no altera en absoluto el tamaño del archivo portador o cubierta (por eso es «una técnica de sustitución»). Posee la desventaja de que el tamaño del archivo portador debe ser mayor al mensaje a embeber; se necesitan 8 bytes de imagen por cada byte de mensaje a ocultar; es decir, la capacidad máxima de una imagen para almacenar un mensaje oculto es de su 12,5%. Si se pretende emplear una mayor porción de bits de la imagen (por ejemplo, no solo el último, sino los dos últimos), puede comenzar a ser percibible al ojo humano la alteración general provocada.
ESTEGANOGRAFÍA SEGÚN EL MEDIO
Dependiendo de la naturaleza del objeto de cobertura (objeto real en el que se incrustan datos secretos), la esteganografía se puede dividir en varios tipos. Exploremos cada uno de ellos.
DOCUMENTOS
La esteganografía de texto oculta información dentro de los archivos de texto. Implica cosas como cambiar el formato de texto existente, cambiar palabras dentro de un texto, generar secuencias de caracteres aleatorias o usar gramáticas libres de contexto para generar textos legibles. Varias técnicas utilizadas para ocultar los datos en el texto son:
Método basado en formato
Generación estadística y aleatoria
Método lingüístico
IMÁGENES
Ocultar los datos tomando el objeto de portada como imagen se conoce como esteganografía de imagen. En la esteganografía digital, las imágenes son una fuente de cobertura ampliamente utilizada porque hay una gran cantidad de bits presentes en la representación digital de una imagen. Hay muchas formas de ocultar información dentro de una imagen. Los enfoques comunes incluyen:
Inserción de bits menos significativa
Enmascaramiento y filtrado
Codificación de patrón redundante
Cifrar y dispersar
Codificación y transformación del coseno
VÍDEO
En la esteganografía de video puede ocultar tipos de datos en formato de video digital. La ventaja de este tipo es que se puede ocultar una gran cantidad de datos en su interior y el hecho de que es un flujo de imágenes y sonidos en movimiento. Puedes pensar en esto como la combinación de esteganografía de imagen y esteganografía de audio. Dos clases principales de video esteganografía incluyen:
Incrustar datos en video sin comprimir y comprimirlos más tarde
Incrustar datos directamente en el flujo de datos comprimidos
AUDIO
En la esteganografía de audio, el mensaje secreto está incrustado en una señal de audio que altera la secuencia binaria del archivo de audio correspondiente. Ocultar mensaje secretos en digital es un proceso mucho más dificil en comparación con otros, como la esteganografía de imágenes. Los diferentes métodos de esteganografía de audio incluyen:
Codificación de bits menos significativos
Codificación de paridad
Codificación de fase
Espectro ensanchado
Este método oculta los datos en archivos de sonido WAV, AU e incluso MP3.
OTROS ARCHIVOS
Uno de los métodos más fáciles de implementar es el de inyección o agregado de bytes al final del archivo. Esta técnica consiste, esencialmente, en agregar o adosar al final de un archivo, de cualquier tipo, otro archivo que será el contenedor del «mensaje a ocultar», también de cualquier tipo. Esta metodología es la más versátil, pues permite usar cualquier tipo de archivo como portador (documentos, imágenes, audio, vídeos, ejecutables, etc) y añadir al final del archivo contenedor el «paquete enviado», que es otro archivo, también de cualquier tipo.
ESTEGANOGRAFÍA EN INTERNET Y REDES SOCIALES
Hoy en día todos (o casi) utilizamos al menos, una red social, como Twitter, Facebook o Instagram, entre otras muchas. Esto convierte a estos canales de comunicación en los transportes ideales de todo tipo de información, un medio de interconexión fácil de usar y con capacidad de llegada a múltiples destinatarios, a cualquier parte del mundo. A través de las redes sociales también es posible enviar información de forma completamente inadvertida. Esto es: utilizando esteganografía informática. No es fácil hacerlo, pues tienen sus propios algoritmos de detección de código oculto, amén de otras técnicas de inserción, como el cambio de resoluciones de imágenes, una vez subidas a la plataforma, etc. Pero esto no quiere decir que sea imposible conseguirlo
ALGUNAS HERRAMIENTAS PARA DESCIFRAR ESTEGANOGRAFÍA
STEGDETECT
Es una herramienta de esteganálisis común. Stegdetect puede encontrar información oculta en imágenes JPEG utilizando esquemas de esteganografía como F5, Invisible Secrets, JPHide y JSteg. También tiene una interfaz gráfica llamada Xsteg. STEGO SUITE
Se compone de tres productos. Stego Watch es una herramienta de esteganografía que busca contenido oculto en archivos de imagen o audio digitales. Stego Analyst es un analizador de archivos de imagen y audio que se integra con Stego Watch para proporcionar un análisis más detallado de los archivos sospechosos y Stego Break es un descifrador de contraseñas diseñado para obtener la contraseña de un archivo que contiene esteganografía.
ILOOK INVESTIGATOR
Es una herramienta de análisis forense utilizada por miles de laboratorios de aplicación e investigadores de todo el mundo para la investigación de imágenes forenses creadas por diferentes utilidades de imágenes.
ENCASE
EnCase cuenta con una herramienta de análisis forense que permite a los investigadores gestionar fácilmente grandes volúmenes de pruebas informáticas y ver todos los archivos relevantes, incluidos los archivos «eliminados», la holgura del archivo y el espacio no asignado.
La solución automatiza eficazmente los procedimientos de investigación básicos, reemplazando procesos y herramientas arcaicos, que requieren mucho tiempo y costes.
En EnCase, los investigadores deben identificar y hacer coincidir el valor hash MD5 de cada archivo sospechoso. Deben importar o construir una biblioteca de conjuntos hash (en este caso, un software de esteganografía) con la función de biblioteca en EnCase. El hash identificará coincidencias de archivos stego. Además, los investigadores deben tener cuidado al crear conjuntos de hash para descubrir esteganografía, para prevenir falsos positivos. Por ejemplo, los investigadores deben utilizar conjuntos de hash seguros para filtrar archivos inofensivos de su investigación
CLASIFICACIÓN DE LOS SISTEMAS CRIPTOGRÁFICOS
La criptografía se divide en dos ramas principales:
Criptografía simétrica o de clave secreta. Lo que la gente asume que es la criptografía: cifrar y descifrar información usando la misma clave secreta. Por esta razón también se conocen como sistemas simétricos. La clave debe ser secreta y conocida tanto por el emisor como por el receptor, y únicamente por ellos. Este es un problema que no resulta tan sencillo de resolver. Para que estos sistemas funcionen correctamente se asume que previamente ambos interlocutores se han puesto de acuerdo en la clave a utilizar o que han hecho uso de alguna metodología de distribución de claves que ha hecho llegar la clave de forma segura a ambos interlocutores. Toda la criptografía desde la antigüedad hasta 1976 se basó exclusivamente en algoritmos simétricos. El cifrado simétrico todavía se utiliza ampliamente, especialmente para el cifrado de datos y la comprobación de la integridad de los mensajes.
Criptografía asimétrica o de clave pública. En 1976, Whitfield Diffie, Martin Hellman y Ralph Merkle introdujeron un tipo de cifrado totalmente diferente y revolucionario. En la criptografía de clave pública, cada usuario posee una pareja de claves: una privada y otra pública, por ello también se denominan sistemas asimétricos. En estos sistemas no es necesario un procedimiento de compartición de clave.
Los algoritmos asimétricos se utilizan para aplicaciones como el cifrado de datos, la firma digital y el acuerdo de claves.
A su vez, los algoritmos de cifrado simétrico se subdividen en dos grupos, cifrado en flujo y cifrado en bloque:
Los algoritmos de cifrado en flujo cifran de uno en uno los caracteres individuales. En los sistemas clásicos generalmente esta transformación se aplicaba sobre los caracteres del alfabeto en el que estaba escrito el mensaje, sin embargo hoy en día normalmente se aplica sobre dígitos binarios (bits), de un mensaje de texto claro, utilizando una transformación de cifrado que varía con el tiempo.EJEMPLOS DE CIFRADORES EN FLUJOLos cifradores en flujo se utilizan a menudo por su velocidad y simplicidad de implementación en hardware y en aplicaciones en las que el texto claro llega en cantidades de longitud desconocida, como una conexión inalámbrica segura o una llamada de teléfono. Se utilizan ampliamente en los protocolos y productos de seguridad actuales. Algunos ejemplos ampliamente usados son:
A5/1 es una familia de cifradores en flujo utilizados para cifrar comunicaciones GSM. Es el estándar europeo para los teléfonos móviles digitales. Se utiliza para cifrar el enlace del teléfono a la estacién base. El estándar A5/1 fue creado en 1987, pero sólo se publicó a finales de los años 90 después de que cayera ante el reversing. Los ataques aparecieron a principios de la década de 2000 y A5/1 fue roto finalmente de una manera que permite el descifrado real (no solo teórico) de las comunicaciones cifradas.
PKZIP es el algoritmo de cifrado incorporado en el programa de compresión de datos PKZIP.
RC4 es un cifrado en flujo de tamaño variable desarrollado en 1987 por Ron Rivest para RSA Data Security, Inc. RC4 fue usado en docenas de productos comerciales de criptografía, en el protocolo de cifrado WEP en redes WiFi, en el protocolo de cifrado de tráfico web SSL/TLS, etc. Hoy en día ya no se utiliza debido a muchos problemas de seguridad descubiertos a lo largo de los años. Ha sido reemplazado por RC6.
Content Scramble System (CSS) es un sistema utilizado para proteger las películas en discos DVD. Utiliza un cifrado en flujo, llamado CSS, para cifrar el contenido de las películas. El CSS fue diseñado en los años 80 cuando el cifrado exportable se restringía a claves de 40 bits. Como resultado, CSS cifra las películas usando una clave secreta de 40 bits. Además, el cifrado en flujo CSS es particularmente débil y puede ser roto en mucho menos tiempo que una búsqueda exhaustiva en las 240 claves.
Salsa20 y ChaCha son dos cifrados en flujo diseñados por Daniel J. Bernstein para su implementación eficiente en software. ChaCha20 fue seleccionado por Google para reemplazar a RC4 en TLS. También se utiliza en protocolos de comunicación como OpenSSH, IKE, IPsec y algunas VPNs.
Trivium fue desarrollado para ser rápido en hardware y razonablemente eficiente en software.
Es un cifrado en flujo que cifra los datos byte a byte. Se han publicado varios trabajos con ataques parciales o totales al algoritmo.
Por el contrario, los algoritmos de cifrado en bloque tienden a cifrar simultáneamente grupos de caracteres (bloques) de un mensaje de texto claro. En este tipo de cifrado, el texto claro se divide en bloques de igual longitud para ser cifrados bloque a bloque. Típicamente, se utiliza un tamaño de bloque de 64 o 128 bits. Normalmente, la longitud del texto claro original no será un múltiplo exacto del tamaño del bloque, lo que exige recurrir a esquemas de relleno: los bits restantes hasta completar el tamaño de bloque se rellenan (padding) con bits extra siguiendo algún tipo de convención
¿Y si la longitud del texto es múltiplo del tamaño de bloque? Entonces, no se rellena, ¿verdad? Pues no. En ese caso, se añade un bloque de relleno completo, con sus 16 bytes establecidos al valor 0×10. Para evitar incertidumbre, siempre hay relleno.
EJEMPLOS DE CIFRADORES EN BLOQUE
Data Encryption Standard (DES) fue desarrollado en la década de 1970. Aunque su corta longitud de clave, de 56 bits, lo hace demasiado inseguro para las aplicaciones actuales, ha sido muy influyente en el desarrollo de la criptografía moderna. El DES no es débil por sí mismo, sino por su clave corta, de tan solo 56 bits. Esta limitación condujo a utilizar variantes del algoritmo con claves más largas, como por ejemplo Triple DES (o 3DES), con una clave de 168 bits.
En 2001, DES fue sustituido por el algoritmo seleccionado como Advanced Encryption Standard (AES), también conocido por su nombre original Rijndael, con tres longitudes de clave diferentes: 128, 192 y 256 bits. Además de estos dos algoritmos, existen cientos de ellos. Entre los que se consideran seguros hoy y en el futuro previsible destacan: Camellia, Serpent, etc.
Por si no había quedado claro, estos algoritmos se caracterizan por:
Ser muy rápidos, pudiendo alcanzar velocidades de hasta 1 GB/s, dependiendo de la implementación en software y del
procesador del dispositivo.
Requerir claves cortas, por ejemplo, de 128 o 256 bits. Así que puedes encontrar el cifrado simétrico en aplicaciones que requieran alta velocidad de cifrado y claves cortas como, por ejemplo:
Herramientas de comunicación, como Whatsapp, Apple Messages o Zoom.
Herramientas de archivo y compresión.
Herramientas de cifrado de archivos.
Encryption File System (EFS) en Microsoft Windows proporciona cifrado a nivel de Sistema de archivos.
Cifrado de discos y particiones, como BitLocker en Windows o FileVault en Mac OS X.
Seguridad para las comunicaciones en redes de área local, como en el estándar IEEE 802.11i.
El nuevo estándar de seguridad WiFi, WPA3, utiliza AES con 256 bits de clave.
Protocolos de comunicaciones seguras, como el TLS utilizado por ejemplo en páginas web seguras con HTTPS.
Ransomware: obviamente, para cifrar lo archivos de un disco duro para exigir su rescate, nada como la criptografía simétrica.
PRINCIPIOS BÁSICOS
En la criptografía se han empleado habitualmente una serie de operaciones para realizar transformaciones en el texto y de esta forma cifrarlo para que fuera ininteligible para cualquier persona a la que no fuera dirigido el mensaje secreto. Dos de estos principios básicos son la sustitución y la transposición.
SUSTITUCIÓN
La sustitución consiste en establecer una correspondencia entre el alfabeto en el que está escrito el mensaje y otro alfabeto, que no tiene necesariamente que ser el mismo que el alfabeto original. De esta manera, se van sustituyendo los caracteres del mensaje original por el correspondiente asignado en el alfabeto de salida. Para descifrar el mensaje el receptor debe conocer cuál es la correspondencia y hacer la sustitución inversa para recuperar el texto original.
Un ejemplo de este tipo de cifrado es el famoso cifrado César.
Una de las debilidades de la sustitución es que la frecuencia de aparición de cada letra en el mensaje original se refleja en el criptograma. Esto lo hace débil ante un ataque de Análisis de frecuencias . Este tipo de ataque se basa en la frecuencia con la que aparecen los caracteres en los diferentes idiomas. De esta manera, conociendo las letras de mayor frecuencia del alfabeto utilizado se puede deducir la clave.
TRANSPOSICIÓN
La transposición consiste en barajar los símbolos del mensaje original y colocarlos en distinto orden con el objeto de hacer el mensaje ininteligible. En este caso los símbolos del criptograma son los mismos que los del mensaje original pero descolocados. Es necesario que el receptor conozca la transposición para recolocar los símbolos en el orden original y reconstruir el mensaje
La clave secreta es el número de letras en cada grupo y el orden en el que se colocan.
La escítala lacedemonia, que veremos en el siguiente apartado, es un sistema de cifrado por transposición.
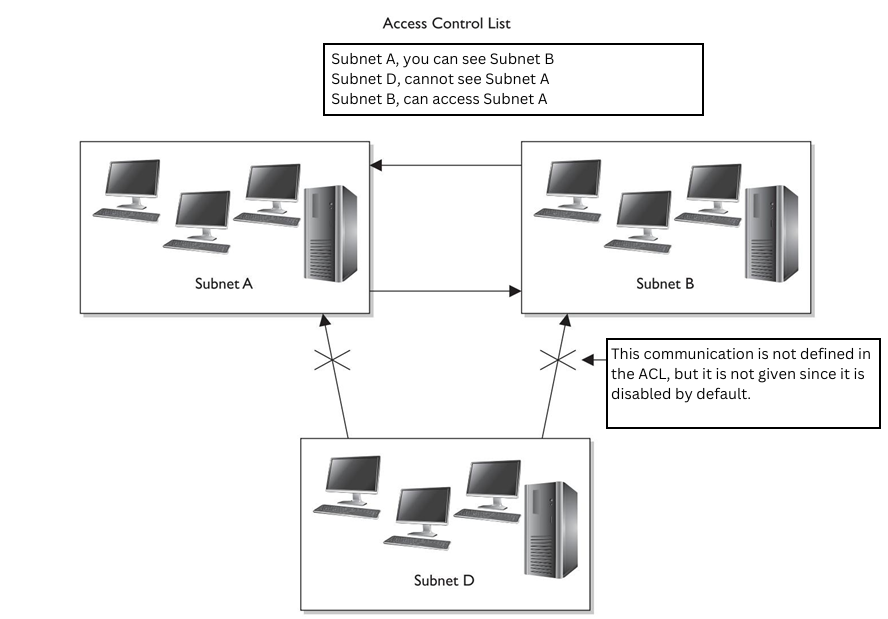
A medida que las organizaciones trasladan su infraestructura y aplicaciones a proveedores de servicios basados en la nube, las organizaciones también optan por emplear la autenticación basada en la nube.
Los protocolos que se utilizan para la gestión de acceso basada en la nube, como SAML, RADIUS y TACACS, todavía se utilizan. La principal diferencia con el acceso basado en la nube es que los servidores de directorio están en la nube, ya sea en la infraestructura basada en la nube de una organización o mediante un servicio de autenticación basado en la nube.
Controles de acceso descentralizados
Los sistemas de control de acceso descentralizados mantienen la información de la cuenta del usuario en ubicaciones separadas, mantenidas por los mismos o diferentes administradores, en toda una organización o empresa. Este tipo de sistema tiene sentido en organizaciones extremadamente grandes o en situaciones donde es necesario un control muy granular de relaciones y derechos de acceso de usuarios complejos. En un sistema de este tipo, los administradores suelen tener un conocimiento más profundo de las necesidades de sus usuarios y pueden aplicar los permisos apropiados, por ejemplo, en un laboratorio de investigación y desarrollo o en una planta de fabricación industrial. Sin embargo, los sistemas de control de acceso descentralizados también tienen varias desventajas potenciales.
Por ejemplo, las organizaciones pueden aplicar políticas de seguridad de manera inconsistente en varios sistemas, lo que resulta en un nivel de acceso incorrecto (demasiado o insuficiente) para usuarios particulares; y si necesita deshabilitar numerosas cuentas para un usuario individual, el proceso se vuelve mucho más laborioso y propenso a errores.
Autenticación de factor único/multifactor
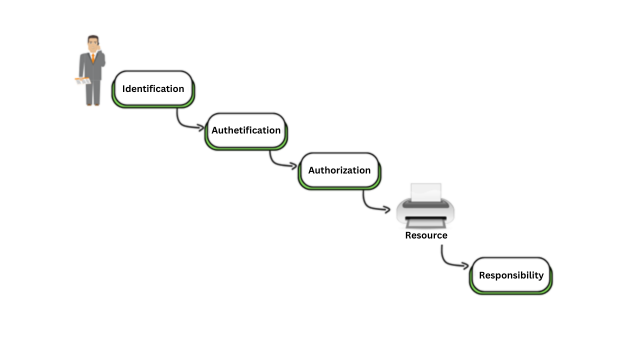
La autenticación es un proceso de dos pasos que consta de identificación y autenticación (I&A). La identificación es el medio por el cual un usuario o sistema (sujeto) presenta una identidad específica (como un nombre de usuario) a un sistema (objeto). La autenticación es el proceso de verificar esa identidad. Por ejemplo, una combinación de nombre de usuario y contraseña es una técnica común (aunque débil) que demuestra los conceptos de identificación (nombre de usuario) y autenticación (contraseña).
La autenticación se basa en cualquiera de estos factores:
Algo que usted sabe, como una contraseña o un número de identificación personal (PIN): este concepto se basa en el supuesto de que solo el propietario de la cuenta conoce la contraseña secreta o el PIN necesario para acceder a la cuenta.
Las combinaciones de nombre de usuario y contraseña son el mecanismo de autenticación más simple, menos costoso y, por lo tanto, más común implementado en la actualidad.
Por supuesto, las contraseñas a menudo se comparten, se roban, se adivinan o se comprometen de otra manera; por lo tanto, también son uno de los mecanismos de autenticación más débiles.
Algo que tenga, como una tarjeta inteligente, un token de seguridad o un teléfono inteligente: este concepto se basa en el supuesto de que solo el propietario de la cuenta tiene la clave necesaria para desbloquear la cuenta. Las tarjetas inteligentes, los tokens USB, los teléfonos inteligentes y los llaveros son cada vez más comunes, especialmente en entornos relativamente seguros como instituciones financieras. Muchas aplicaciones en línea, como LinkedIn y Twitter, también han implementado la autenticación de múltiples factores. Aunque las tarjetas inteligentes y los tokens son un poco más caros y complejos que otros mecanismos de autenticación menos seguros, no son (normalmente) prohibitivos, ni complicado de implementar, administrar y usar. Los teléfonos inteligentes que pueden recibir mensajes de texto o ejecutar aplicaciones de token de software como Google Authenticator o Microsoft Authenticator son cada vez más populares debido a su menor costo y conveniencia. Independientemente del método elegido, todas las formas de autenticación multifactor brindan un impulso significativo a la seguridad de la autenticación. Por supuesto, los tokens, las tarjetas inteligentes y los teléfonos inteligentes a veces se pierden, se los roban o se dañan.
Dato curioso: Debido a los riesgos asociados con los mensajes de texto (como las estafas de portabilidad de teléfonos móviles), el Instituto Nacional de Estándares y Tecnología (NIST) de Estados Unidos ha desaprobado el uso de mensajes de texto para la autenticación multifactor.
Recuerda que la autenticación se debe basar en: algo que sabes, algo que tienes o algo que eres.
Identificación y autenticación (I&A)
Las diversas técnicas de identificación y autenticación (I&A) que analizamos en las siguientes sección incluyen contraseñas/frases de contraseña y PIN (basadas en el conocimiento); biometría y comportamiento (basado en características); y contraseñas de un solo uso, tokens e inicio de sesión único (SSO).
El componente de identificación es normalmente un mecanismo relativamente simple basado en un nombre de usuario o, en el caso de un sistema o proceso, basado en un nombre de computadora o proceso, dirección de control de acceso a medios (MAC), dirección de protocolo de Internet (IP) o ID de proceso. (PID). Los requisitos de identificación incluyen solo que debe identificar de manera única al usuario (o sistema/proceso) y no debe identificar el rol de ese usuario o la importancia relativa en la organización (la identificación no debe incluir etiquetas como contabilidad o director general). No se deben permitir cuentas comunes, compartidas y grupales, como raíz, administrador o sistema. Tales cuentas no brindan responsabilidad y son objetivos principales para seres maliciosos.
Recuerda: La identificación es el acto de reclamar una identidad específica. La autenticación es el acto de verificar esa identidad.
Autenticación de un solo factor
La autenticación de un solo factor requiere solo uno de los tres factores anteriores discutidos anteriormente (algo que sabes, algo que tienes o algo que eres) para la autenticación. Los mecanismos comunes de autenticación de un solo factor incluyen contraseñas y frases de contraseña, contraseñas de un solo uso y números de identificación personal (PIN).
CONTRASEÑAS Y FRASES DE CONTRASEÑA
“Una contraseña debería ser como un cepillo de dientes. Úselo todos los días; cámbielo regularmente; y NO lo compartas con amigos.” –USENET
Las contraseñas son fácilmente las credenciales de autenticación más comunes y más débiles que se usan en la actualidad. Aunque existen tecnologías de autenticación más avanzadas y seguras disponibles, incluidos los tokens y la biometría, las organizaciones suelen utilizar esas tecnologías como complementos o en combinación con los nombres de usuario y contraseñas tradicionales, en lugar de reemplazarlos.
Una frase de contraseña es una variación de una contraseña; utiliza una secuencia de caracteres o palabras, en lugar de una única contraseña. Por lo general, los atacantes tienen más dificultades para descifrar frases de contraseña que para descifrar contraseñas normales porque las frases de contraseña más largas suelen ser más difíciles de descifrar que las contraseñas más cortas y complejas.
Las frases de contraseña también tienen las siguientes ventajas:
Los usuarios utilizan con frecuencia las mismas contraseñas para acceder a numerosas cuentas; ¡sus redes corporativas, sus ordenadores personales, su Gmail o Hotmail! cuentas de correo electrónico, sus cuentas de Netflix y sus cuentas de Amazon, por ejemplo. Por lo tanto, un atacante que tiene como objetivo a un usuario específico puede obtener acceso a su cuenta de trabajo si busca un sistema menos seguro, como el ordenador de su hogar, o si compromete una cuenta de Internet (porque el usuario tiene contraseñas convenientemente almacenadas). Los sitios de Internet y los ordenadores personales generalmente no usan frases de contraseña, por lo que aumenta las posibilidades de que tus usuarios tengan que usar diferentes contraseñas/frases de contraseña para acceder a sus cuentas de trabajo.
Inconvenientes:
Los usuarios pueden recordar y escribir frases de contraseña más fácilmente de lo que pueden recordar y escribir una contraseña críptica mucho más corta que requiere acrobacias con los dedos torcidos para escribirla en un teclado.
Los pueden poner mucha resistencia a usar frases de contraseña, por lo que puede ser un método difícil de implantar. No todo el mundo es creativo.
No todos los sistemas admiten frases de contraseña.
Muchas interfaces y herramientas de línea de comandos no admiten el carácter de espacio que separa las palabras en una frase de contraseña.
Al final, una frase de contraseña sigue siendo solo una contraseña (aunque mucho más larga y mejor) y, por lo tanto, comparte algunos de los mismos problemas asociados con las contraseñas.
Tal como hemos visto, las contraseñas puedes ser:
· Inseguras
· Fáciles de romper
· Fáciles de robar
· Inconveniente que puede poner los usuarios (ejemplo frases)
· Refutable (no garantiza al 100% que fue un usuario el que accedió)
Imagen que muestra el tiempo que se tarda actualmente en romper una contraseña
Las contraseñas tienen los siguientes controles de inicio de sesión y funciones de administración que debe configurar de acuerdo con la política de seguridad y las mejores prácticas de seguridad de una organización:
Longitud: Generalmente, cuanto más larga, mejor. Una contraseña es, en efecto, una clave de cifrado. Así como las claves de cifrado más grandes (como 1024 bits o 2048 bits) son más difíciles de descifrar, también lo son las contraseñas más largas. Debe configurar los sistemas para que requieran una longitud mínima de contraseña de diez a quince caracteres. Por supuesto, los usuarios pueden olvidar fácilmente contraseñas largas o simplemente poner mucha resistencia al usarla.
Complejidad: las contraseñas seguras contienen una combinación de letras mayúsculas y minúsculas, números y caracteres especiales como # y &. Tener en cuenta que es posible que algunos sistemas no acepten determinados caracteres especiales o que esos caracteres realicen funciones especiales (por ejemplo, en el software de emulación de terminal).
Caducidad (o caducidad máxima de la contraseña): debe establecer la caducidad máxima caducidad de la contraseña para requerir cambios de contraseña a intervalos regulares: los períodos de 30, 60 o 90 días son comunes.
Antigüedad mínima de la contraseña: Esto evita que un usuario cambie su contraseña con demasiada frecuencia. La configuración recomendada es de uno a diez días para evitar que un usuario eluda fácilmente los controles del historial de contraseñas (por ejemplo, cambiando su contraseña cinco veces en unos pocos minutos y luego volviendo a establecer su contraseña original).
Reutilización: la configuración de reutilización de contraseñas (de cinco a diez es común) permite que un sistema recordar las contraseñas utilizadas anteriormente (o, más apropiadamente, sus hashes) para una cuenta específica. Esta configuración de seguridad evita que los usuarios eludan la caducidad máxima de la contraseña al alternar entre dos o tres contraseñas conocidas cuando se les pide que cambien sus contraseñas.
Intentos limitados: este control limita el número de inicios de sesión fallidos intentos y consta de dos componentes: umbral de contador (por ejemplo, tres o cinco) y puesta a cero del contador (por ejemplo, 5 o 30 minutos). El umbral del contador es el número máximo de intentos fallidos consecutivos permitidos antes de que ocurra alguna acción (como deshabilitar automáticamente la cuenta). El reinicio del contador es la cantidad de tiempo entre intentos fallidos.
Duración del bloqueo (o bloqueo de intrusos): cuando un usuario supera el umbral del contador que describimos en el punto anterior, la cuenta se bloquea. Las organizaciones suelen establecer la duración del bloqueo en 30 minutos, pero puede establecerla para cualquier duración. Si establece la duración para siempre, un administrador debe desbloquear la cuenta.
Períodos de tiempo limitados: este control restringe la hora del día en que un usuario puede iniciar sesión. Por ejemplo, puede reducir efectivamente el período de tiempo que los atacantes pueden comprometer sus sistemas al limitar el acceso de los usuarios solo al horario comercial. Sin embargo, este tipo de control se está volviendo menos común en la era moderna de los adictos al trabajo y la economía global, los cuales requieren que los usuarios realicen el trabajo legítimamente a todas horas del día.
Certificados digitales
Se puede instalar un certificado digital en el dispositivo del usuario. Cuando el usuario intenta autenticarse en un sistema, el sistema consultará el dispositivo del usuario en busca del certificado digital para confirmar la identidad del usuario. Si se puede obtener el certificado digital y si se confirma que es genuino, el usuario puede iniciar sesión.
La autenticación con certificado digital también ayuda a obligar a los usuarios a iniciar sesión utilizando solo dispositivos proporcionados por la empresa. Esto presupone el hecho de que el usuario no puede copiar el certificado digital en otro dispositivo, tal vez de propiedad personal, o que un intruso no puede copiar el certificado en su propio dispositivo.
Al implementar certificados digitales en dispositivos como ordenadores portátiles, los administradores deben asegurarse de implementar un certificado por dispositivo o por usuario en cada ordenador portátil, no un certificado general de la empresa.
Biométrica
El único método absoluto para identificar positivamente a un individuo es basar la autenticación en alguna característica física o conductual única de ese individuo. La identificación biométrica utiliza características físicas, incluidas las huellas dactilares, la geometría de la mano y rasgos faciales como los patrones de la retina y el iris.
La biometría del comportamiento se basa en mediciones y datos derivados de una acción, y mide indirectamente las características del cuerpo humano. Las características de comportamiento incluyen voz, firma y patrones de pulsación de teclas.
La biometría se basa en el tercer factor de autenticación: algo que eres.
Los sistemas de control de acceso biométrico aplican el concepto de identificación y autenticación (I&A) de forma ligeramente diferente, dependiendo de su uso:
Controles de acceso físico: El individuo presenta los datos biométricos requeridos característica y el sistema intenta identificar a la persona haciendo coincidir la característica de entrada con su base de datos de personal autorizado. Este tipo de control también se conoce como búsqueda de uno a muchos.
Controles de acceso lógico: el usuario ingresa un nombre de usuario o PIN (o inserta una tarjeta inteligente) y luego presenta la característica biométrica requerida para la verificación. El sistema intenta autenticar al usuario haciendo coincidir la identidad declarada y el archivo de imagen biométrica almacenado para esa cuenta. Este tipo de control también se conoce como búsqueda uno a uno.
La autenticación biométrica, en sí misma, no proporciona una autenticación sólida porque se basa solo en uno de los tres requisitos de autenticación: algo que tu eres. Para ser considerado un mecanismo de autenticación realmente sólido, la autenticación biométrica debe incluir algo que tu sepas y algo que tienes.
Responsabilidad
El concepto de responsabilidad se refiere a la capacidad de un sistema para asociar usuarios y procesos con sus acciones (lo que hicieron). Los registros de auditoría y los registros del sistema son componentes de la responsabilidad.
Los sistemas utilizan registros de auditoría y pistas de auditoría principalmente como medio para solucionar problemas y verificar eventos. Los usuarios no deben ver los registros de auditoría y las pistas de auditoría como una amenaza o como un “hermano mayor” que los vigila porque no se puede confiar en ellos.
De hecho, los usuarios astutos consideran estos mecanismos como protectores, porque no solo prueban lo que hicieron, sino que también ayudan a probar lo que no hicieron. Aún así, es aconsejable que los usuarios sepan que los sistemas que utilizan, registran sus acciones.
Un concepto de seguridad importante que está estrechamente relacionado con la responsabilidad de lo que se hace, ese “responder de mis acciones”, es el no repudio. No repudio significa que un usuario (nombre de usuario Pepe Pérez) no puede negar una acción porque su identidad está positivamente asociada con sus acciones.
El no repudio es un concepto legal importante. Si un sistema permite que los usuarios inicien sesión con una cuenta de usuario genérica, o una cuenta de usuario que tiene una contraseña ampliamente conocida, o ninguna cuenta de usuario, entonces no puede asociar absolutamente a ningún usuario con una determinada acción (maliciosa) o ( no autorizado) en ese sistema, lo que hace que sea extremadamente difícil procesar o disciplinar a ese usuario.
La responsabilidad en los servicios AAA (autenticación, autorización y responsabilidad) registra siempre lo que hizo un sujeto. Está por descontando, que no se debe aceptar ya ningún sistema que no cumpla las AAA.
No repudio significa que un usuario no puede negar una acción porque usted puede asociarlo irrefutablemente con esa acción.
Gestión de sesiones
Una sesión es un término formal que se refiere al diálogo de un usuario individual, o a una serie de interacciones, con un sistema de información. Los sistemas de información necesitan rastrear las sesiones de los usuarios individuales para distinguir correctamente las acciones de un usuario de las de otro.
Para proteger la confidencialidad e integridad de los datos accesibles a través de una sesión, los sistemas de información generalmente utilizan tiempos de espera de sesión o actividad para evitar que un usuario no autorizado continúe una sesión que ha estado inactiva o inactiva durante un período de tiempo específico.
Se utilizan dos medios principales de tiempos de espera de sesión:
Protectores de pantalla. Implementado por el sistema operativo, un protector de pantalla bloquea la estación de trabajo o el dispositivo móvil y requiere que el usuario vuelva a iniciar sesión en el sistema después de un período de inactividad. El protector de pantalla de la estación de trabajo o del dispositivo móvil protege todas las sesiones de la aplicación. Asegúrese de que esto realmente bloquee la pantalla o el dispositivo, ya que algunos sistemas se pueden configurar para que no requieran un PIN o contraseña para desbloquearlos.
Tiempos de espera de inactividad. Las aplicaciones de software individuales pueden utilizar un auto función de bloqueo o cierre de sesión automático si un usuario ha estado inactivo durante un período de tiempo específico.
Por ejemplo, si un usuario autorizado deja una terminal de un ordenador desbloqueada o una ventana del navegador en una estación de trabajo desatendida, un usuario no autorizado puede simplemente sentarse en la estación de trabajo y continuar la sesión.
Los tiempos de espera de inactividad de la estación de trabajo se denominaron originalmente “protectores de pantalla” para evitar que una imagen estática en una pantalla de tubo de rayos catódicos (CRT) se queme en la pantalla. Si bien los monitores actuales no requieren esta protección, el término “protector de pantalla” todavía es de uso común.
Registro y acreditación de identidad
Los procesos formales de registro de usuarios son importantes para el aprovisionamiento seguro de cuentas, particularmente en organizaciones grandes donde no es práctico o posible conocer a todos los trabajadores. Esto es particularmente crítico en entornos SSO donde los usuarios tendrán acceso a múltiples sistemas y aplicaciones.
La prueba de identidad a menudo comienza en el momento de la contratación, cuando generalmente se requiere que los nuevos trabajadores muestren una identificación emitida por el gobierno y el estado legal de derecho a trabajar. Estos procedimientos deben constituir la base para el registro inicial de usuarios en los sistemas de información.
Las organizaciones deben tomar varias precauciones al registrarse y aprovisionar usuarios:
Identidad del usuario. La organización debe asegurarse de que las nuevas cuentas de usuario se aprovisionen y entreguen al usuario correcto.
Protección de la privacidad. La organización no debe utilizar el número de la Seguridad Social por ejemplo, fecha de nacimiento u otra información privada sensible para autenticar al usuario.
En su lugar, se deben utilizar otros valores, como el número de empleado (u otros que no puedan obtener otros empleados).
Credenciales temporales. La organización debe asegurarse de que las credenciales de inicio de sesión temporales se asignen a la persona correcta. Otros no deberían poder adivinar fácilmente las credenciales temporales. Finalmente, las credenciales temporales deben configurarse para que caduquen en un corto período de tiempo.
Acceso a la primogenitura. La organización debe revisar periódicamente qué derecho de nacimiento se otorga a los nuevos trabajadores, siguiendo los principios de necesidad de saber y privilegio mínimo.
Se producen consideraciones adicionales sobre la identidad del usuario cuando un usuario intenta iniciar sesión en un sistema. Estos son
Ubicación geográfica. Esto se puede derivar de la dirección IP del usuario.
Esto no es absolutamente confiable, pero puede ser útil para determinar la ubicación del usuario. Muchos dispositivos, en particular los teléfonos inteligentes y las tabletas, utilizan la tecnología GPS para la información de ubicación, que generalmente es más confiable que la dirección IP.
Estación de trabajo en uso. La organización puede tener políticas sobre si un usuario puede iniciar sesión con una estación de trabajo de quiosco de propiedad personal o pública.
Tiempo transcurrido desde el último inicio de sesión. Cuánto tiempo ha pasado desde la última vez que el usuario iniciado sesión en el sistema o la aplicación.
Intento de inicio de sesión después de intentos fallidos. Si ha habido intentos de inicio de sesión fallidos recientes.
Dependiendo de las condiciones anteriores, el sistema puede configurarse para presentar desafíos adicionales al usuario. Estos desafíos aseguran que la persona que intenta iniciar sesión sea realmente el usuario autorizado, no otra persona o máquina.
Esto se conoce como autenticación basada en riesgos.
Conclusión
Como hemos visto, la gestión de identidades y accesos es un conjunto de procesos y tecnologías que se utilizan para controlar el acceso a activos críticos. Junto con otros controles críticos, IAM es parte del núcleo de la seguridad de la información: cuando se implementa correctamente, las personas no autorizadas no pueden acceder a los activos críticos. Es menos probable que ocurran violaciones y otros abusos de información y activos.
Administrar la identificación y autenticación de personas, dispositivos y servicios
La actividad central dentro de la administración de identidades y accesos (IAM) es la administración de identidades, incluidas las personas, los dispositivos y los servicios. En laboratorio, describimos los procesos y las tecnologías que se utilizan en la actualidad.
Implementación de gestión de identidad
La implementación de la gestión de identidades comienza con un plan. Un sistema de administración de identidad y acceso (IAM) en una organización es un sistema complejo y distribuido que toca sistemas, redes y aplicaciones, y también controla el acceso a los activos. Un sistema IAM también incluye los procesos comerciales que funcionan junto con las tecnologías y el personal de IAM para realizar el trabajo.
Un sistema IAM es probablemente la función más importante que implementará una organización. Después de la propia red, el sistema IAM suele ser el más crítico en un entorno, porque el sistema IAM controla el acceso a todos los sistemas y aplicaciones.
Inicio de sesión único (SSO)
El concepto de inicio de sesión único (SSO) aborda un problema común tanto para los usuarios como para los administradores de seguridad. Cada cuenta que existe en un sistema, red o aplicación es un punto potencial de acceso no autorizado. Varias cuentas que pertenecen a un solo usuario representan un riesgo aún mayor:
Los usuarios que necesitan acceso a múltiples sistemas o aplicaciones a menudo deben mantener numerosas credenciales. Inevitablemente, esto conduce a atajos en la creación y recuperación de contraseñas. Abandonados a sus propios dispositivos, los usuarios crean contraseñas débiles que solo tienen ligeras variaciones o, peor aún, usarán las mismas contraseñas en todos los lugares que puedan. Cuando tienen múltiples conjuntos de credenciales para administrar, es más probable que los usuarios las anoten. No se detiene en los límites de la organización: los usuarios a menudo usan las mismas contraseñas en el trabajo que usan para sus cuentas personales.
Varias cuentas también afectan la productividad del usuario porque el usuario debe detenerse para iniciar sesión en diferentes sistemas. Alguien también debe crear y mantener cuentas, lo que implica desbloquear cuentas y brindar soporte, eliminar, restablecer y deshabilitar múltiples conjuntos de ID de usuario y contraseñas.
A primera vista (por desgracia), SSO parece la solución “perfecta” que buscan los usuarios y los administradores de seguridad. SSO permite que un usuario presente un conjunto único de credenciales de inicio de sesión, generalmente a un servidor de autenticación, que luego registra al usuario de manera transparente en todos los demás sistemas y aplicaciones empresariales para los que ese usuario está autorizado. Por supuesto, SSO tiene algunas desventajas, que incluyen:
¡Guau!: Después de autenticarte, tienes las llaves del reino.
Lo puedes entender como que ya tienes acceso a todos los recursos autorizados Es la pesadilla del profesional de la seguridad. Si las credenciales de inicio de sesión de las cuentas de un usuario se ven comprometidas, un intruso puede acceder a todo lo que el usuario final estaba autorizado a acceder. Piensa lo que podría pasar en un Ayuntamiento.
Complejidad
Implementar SSO puede ser difícil y llevar mucho tiempo. Debe abordar los problemas de interoperabilidad entre diferentes sistemas y aplicaciones.
Lenguaje de marcado de aserción de seguridad (SAML)
El protocolo de facto para la autenticación, SAML, se utiliza para facilitar la autenticación de usuarios entre sistemas y entre organizaciones, a través del intercambio de información de autenticación y autorización entre organizaciones. SAML es el pegamento que se utiliza para hacer funcionar la mayoría de los sistemas de inicio de sesión único (SSO).
Como sugiere su nombre completo, SAML es un lenguaje de marcado XML. XML se está convirtiendo en un método estándar para intercambiar información entre sistemas diferentes.
Kerberos
Kerberos, comúnmente utilizado en Sun Network File System (NFS) y Microsoft Windows, es quizás el protocolo de autenticación de claves simétricas basado en tickets más popular que se usa en la actualidad.
Kerberos lleva el nombre del feroz perro de tres cabezas que guarda las puertas del Hades en la mitología griega. Investigadores del Instituto Tecnológico de Massachusetts (MIT, también conocido como Millionaires in Training) desarrollaron este protocolo de sistemas abiertos a mediados de la década de 1980.
Kerberos es un protocolo complejo que tiene muchas implementaciones diferentes y no tiene una explicación simple. La siguiente discusión paso a paso es una descripción básica del funcionamiento de Kerberos:
1)El cliente solicita al sujeto (como un usuario) un identificador y una credencial (por ejemplo, nombre de usuario y contraseña). Con la información de autenticación (contraseña), el cliente genera y almacena temporalmente una clave secreta para el sujeto mediante una función hash unidireccional y luego envía solo la identificación del sujeto (nombre de usuario) al servidor de autenticación (AS) del Centro de distribución de claves (KDC). La contraseña/clave secreta no se envía al KDC:
2) El AS en el KDC verifica que el sujeto (conocido como principal) existe en la base de datos del KDC. El Servicio de concesión de tickets (TGS) del KDC genera una clave de sesión de cliente/TGS cifrada con la clave secreta del sujeto, que solo conocen el TGS y el cliente. El TGS también genera un Ticket de concesión de tickets (TGT), que consta de la identificación del sujeto, la dirección de red del cliente, el período de validez del ticket y la clave de sesión del cliente/TGS. El TGS encripta el TGT utilizando su clave secreta, que solo el TGS conoce, luego envía la clave de sesión del cliente/ TGS y el TGT al cliente.
3) El cliente descifra la clave de sesión del cliente/TGS (usando la clave secreta almacenada que generó usando la contraseña del sujeto), autentica al sujeto (usuario) y luego borra la clave secreta almacenada para evitar un posible compromiso. El cliente no puede descifrar el TGT, que el TGS cifró mediante la clave secreta de TGS.
4) Cuando el sujeto solicita acceso a un objeto específico (como un servidor, también conocido como principal), envía el TGT, el identificador del objeto (como un nombre de servidor) y un autenticador al TGS en el KDC. (El autenticador es un mensaje separado que contiene la identificación del cliente y una marca de tiempo, y usa la clave de sesión del cliente/TGS para encriptarse).
5) El TGS en el KDC genera una clave de sesión de cliente/servidor (que cifra mediante el uso de la Clave de Sesión Cliente/TGS) y un Ticket de Servicio (que consta de la identificación del sujeto, la dirección de red del cliente, el período de validez del ticket y la Clave de Sesión Cliente/Servidor). El TGS encripta el Ticket de Servicio utilizando la clave secreta del objeto solicitado (servidor), que solo conocen el TGS y el objeto. Luego, el TGS envía la clave de sesión del cliente/servidor y el vale de servicio al cliente.
6) El cliente descifra la clave de sesión de cliente/servidor mediante la clave de sesión de cliente/TGS. El cliente no puede descifrar el Ticket de Servicio, que el TGS cifró utilizando la clave secreta del objeto solicitado.
7) El cliente puede entonces comunicarse directamente con el objeto solicitado (servidor).
El cliente envía el Ticket de Servicio y un autenticador al objeto solicitado (servidor). El cliente cifra el autenticador (que comprende la identificación del sujeto y una marca de tiempo) utilizando la clave de sesión de cliente/servidor que generó el TGS. El objeto (servidor) descifra el ticket de servicio utilizando su clave secreta.
El ticket de servicio contiene la clave de sesión del cliente/servidor, que permite que el objeto (servidor) descifre el autenticador. Si la identificación del sujeto y la marca de tiempo son válidas (de acuerdo con la identificación del sujeto, la dirección de red del cliente y el período de validez especificado en el ticket de servicio), se establece la comunicación entre el cliente y el servidor. La clave de sesión de cliente/
servidor se usa luego para comunicaciones seguras entre el sujeto y el objeto.
LDAP
El protocolo ligero de acceso a directorios (LDAP) es tanto un protocolo IP como un modelo de datos.
LDAP (pronunciado EL-dap) se utiliza para admitir funciones de directorio y autenticación para personas y recursos. Varios proveedores han implementado LDAP, incluidos:
Servidor de Directorio Apache
Directorio eTrust de CA
IBM SecureWay y Tivoli Directory Server
Directorio Activo de Microsoft
Servidor de directorio Sun
Radius
El protocolo RADIUS (Remote Authentication Dial-In User Service ) es un protocolo de red cliente- servidor de código abierto, definido en más de 25 RFC del IETF actual, que proporciona autenticación, autorización y responsabilidad (AAA). RADIUS es un protocolo de capa de aplicación que utiliza paquetes de protocolo de datagramas de usuario (UDP) para el transporte. UDP es un protocolo sin verificación de conexión, lo que significa que es rápido, pero no tan confiable como otros protocolos de transporte.
RADIUS se implementa comúnmente en redes de proveedores de servicios de red (NSP), así como en servicios corporativos de acceso remoto (RAS) y redes privadas virtuales (VPN). RADIUS también se está volviendo cada vez más popular en las redes inalámbricas corporativas. Un usuario proporciona información de nombre de usuario/contraseña a un cliente RADIUS mediante PAP o CHAP. El cliente RADIUS cifra la contraseña y envía el nombre de usuario y la contraseña cifrada al servidor RADIUS para la autenticación.
Nota: Las contraseñas intercambiadas entre el cliente RADIUS y el servidor RADIUS están encriptadas, pero las contraseñas intercambiadas entre el cliente de la estación de trabajo y el cliente RADIUS no están necesariamente encriptadas, por ejemplo, si se utiliza la autenticación PAP. Si el cliente de la estación de trabajo también es un cliente RADIUS, todos los intercambios de contraseñas se cifran, independientemente del protocolo de autenticación utilizado.
Aunque la autenticación y la autorización son bastante diferentes, juntas comprenden un proceso de dos pasos que determina si un individuo puede acceder a un recurso en particular. En el primer paso, la autenticación, la persona debe demostrarle al sistema que es quien dice ser: un usuario autorizado del sistema. Después de una autenticación exitosa, el sistema debe establecer si el usuario está autorizado para acceder al recurso en particular y qué acciones puede realizar en ese recurso.
La autorización es un componente central de cada sistema operativo, pero las aplicaciones, los paquetes adicionales de seguridad y los propios recursos también pueden proporcionar esta funcionalidad. Por ejemplo, supongamos que Marga se ha autenticado a través del servidor de autenticación y ahora quiere ver una hoja de cálculo que reside en un servidor de archivos. Cuando encuentre esta hoja de cálculo y haga doble clic en el icono, verá un reloj de arena en lugar del puntero del ratón. En esta etapa, el servidor de archivos está comprobando si Marga tiene los derechos y permisos para ver la hoja de cálculo solicitada. También verifica si Marga puede modificar, eliminar, mover o copiar el archivo. Una vez que el servidor de archivos busca a través de una matriz de acceso y encuentra que Marga tiene los derechos necesarios para ver este archivo, el archivo se abre en el escritorio de Marga. La decisión de permitir o no a Marga ver este archivo se basó en criterios de acceso. Los criterios de acceso son la clave de la autenticación.
Criterios de acceso
Sería frustrante si los permisos de control de acceso se basaran solo en control total o sin acceso. Estas opciones son muy limitantes, y un administrador terminaría dando a todos el control total, lo que no brindaría protección. En su lugar, existen diferentes formas de limitar el acceso a los recursos y, si se entienden y utilizan correctamente, pueden proporcionar el nivel de acceso deseado.
La concesión de derechos de acceso a los sujetos debe basarse en el nivel de confianza que una empresa tiene en un sujeto y la necesidad de saber del sujeto. El hecho de que una empresa confíe completamente en Pedro con sus archivos y recursos no significa que cumpla con los criterios de necesidad de saber para acceder a las declaraciones de impuestos y los márgenes de beneficio de la empresa. Si Juan cumple con los criterios de necesidad de saber para acceder a los historiales laborales de los empleados, no significa que la empresa confíe en él para acceder a todos los demás archivos de la empresa. Estos temas deben identificarse e integrarse en los criterios de acceso. Los diferentes criterios de acceso se pueden imponer por roles, grupos, ubicación, hora y tipos de transacciones.
El uso de roles es una forma eficiente de asignar derechos a un tipo de usuario que realiza una determinada tarea. Este rol se basa en una asignación de trabajo o función. Si hay un puesto dentro de una empresa para que una persona audite transacciones y registros de auditoría, el rol que esta persona cumple solo necesitaría una función de lectura para ese tipo de archivos. Este rol no necesitaría privilegios de control total, modificación o eliminación.
El uso de grupos es otra forma efectiva de asignar derechos de control de acceso. Si varios usuarios requieren el mismo tipo de acceso a la información y los recursos, ponerlos en un grupo y luego asignar derechos y permisos a ese grupo es más fácil de administrar que asignar derechos y permisos a cada individuo por separado. Si una impresora específica está disponible solo para el grupo de contabilidad, cuando un usuario intente imprimir en ella, se verificará la pertenencia al grupo del usuario para ver si realmente está en el grupo de contabilidad. Esta es una forma en que el control de acceso se aplica a través de un mecanismo de control de acceso lógico.
La ubicación física o lógica también se puede utilizar para restringir el acceso a los recursos. Algunos archivos pueden estar disponibles solo para usuarios que pueden iniciar sesión de forma interactiva en un ordenador. Esto significa que el usuario debe estar físicamente en el ordenador e ingresar las credenciales localmente en lugar de iniciar sesión de forma remota desde otro ordenador. Esta restricción se implementa en varias configuraciones de servidor para impedir que personas no autorizadas puedan ingresar y reconfigurar el servidor de forma remota. Las restricciones de ubicación lógica generalmente se realizan a través de restricciones de dirección de red. Si un administrador de red quiere asegurarse de que las solicitudes de estado de una consola de administración de detección de intrusos se acepten solo desde ciertos ordenadores en la red, el administrador de red puede configurar esto dentro del software. La hora del día, o el aislamiento temporal, es otro mecanismo de control de acceso que se puede utilizar. Si un profesional de la seguridad quiere asegurarse de que nadie acceda a los archivos de nómina entre las 8:00 y las 15: 00, esa configuración se puede implementar para garantizar que el acceso en esos momentos esté restringido. Si el mismo profesional de seguridad quiere asegurarse de que no se realicen transacciones en la cuenta bancaria durante los días en que el banco no está abierto, puede indicar en el mecanismo de control de acceso lógico que este tipo de acciones está prohibido los domingos.
El acceso temporal también se puede basar en la fecha de creación de un recurso. Supongamos que Paco comenzó a trabajar para su empresa en marzo de 2021. Puede haber una necesidad comercial de permitir que Paco solo acceda a los archivos que se crearon después de esta fecha y no antes. Las restricciones de tipo de transacción se pueden usar para controlar a qué datos se accede durante ciertos tipos de funciones y qué comandos se pueden ejecutar en los datos. Un programa de banca en línea puede permitir que un cliente vea el saldo de su cuenta, pero puede que no le permita transferir dinero hasta que tenga cierto nivel de seguridad o derecho de acceso. Un administrador de base de datos puede crear una base de datos para el departamento de recursos humanos, pero es posible que no pueda leer ciertos archivos confidenciales dentro de esa base de datos. Todos estos son ejemplos de restricciones de tipo de transacción para controlar el acceso a datos y recursos.
Predeterminado a Sin acceso (Si no está seguro, simplemente diga que no)
Los mecanismos de control de acceso deben establecer por defecto acceso nulo para proporcionar el mayor nivel de seguridad necesario y garantizar que no pasen desapercibidos los agujeros de seguridad. Se encuentra disponible una amplia gama de niveles de acceso para asignar a individuos y grupos, según la aplicación y/o el sistema operativo. Un usuario puede tener permisos de lectura, modificación, eliminación, control total o ningún permiso de acceso. La afirmación de que los mecanismos de seguridad deben establecer de forma predeterminada “sin acceso”, o “acceso nulo”, significa que, si no se ha configurado nada específicamente para un individuo o el grupo al que pertenece, ese usuario no debería poder acceder a ese recurso por defecto. Si no se permite explícitamente el acceso, debe denegarse implícitamente. La seguridad se trata de estar seguro, y este es el enfoque más seguro para poner en practica cuando se trata de métodos y mecanismos de control de acceso. En otras palabras, todos los controles de acceso deben basarse en el concepto de comenzar con acceso cero o nulo y construir sobre eso. En lugar de dar acceso a todo y luego quitar privilegios según la necesidad, el mejor enfoque es comenzar sin nada y agregar privilegios según la necesidad de saber.La mayoría de las listas de control de acceso (ACL) que funcionan en routers y firewalls de filtrado de paquetes están predeterminadas sin acceso.
En este esquema, se muestra que el tráfico de la Subred A puede acceder a la Subred B, el tráfico de la Subred D no puede acceder a la Subred A y la Subred B puede comunicarse con la Subred A. Todas las demás rutas de transmisión de tráfico que no se enumeran aquí son no permitido por defecto. La subred D no puede comunicarse con la subred B porque dicho acceso no se indica explícitamente en la ACL del enrutador.
Necesito saber Si
El principio de necesidad de saber es similar al principio de privilegios mínimos. Se basa en el concepto de que las personas deben tener acceso únicamente a la información que necesitan absolutamente para desempeñar sus funciones laborales. Dar más derechos a un usuario solo pide dolores de cabeza y la posibilidad de que ese usuario abuse de los permisos que se le han asignado. Un administrador desea otorgar a un usuario la menor cantidad de privilegios que pueda, pero solo los suficientes para que ese usuario sea productivo al realizar tareas. Decidir qué necesita saber un usuario, o qué derechos de acceso son necesarios, a veces no es tarea fácil, ya que ni los propios usuarios conocen a qué deben tener derecho a acceso, así que por las dudas, siempre lo piden todos. Por lo que el administrador de sistemas tendrá que configurar los mecanismos de control de acceso para permitir que este usuario tenga el acceso mínimo para realizar su trabajo y no más, y por lo tanto el mínimo privilegio. Por ejemplo, si la gerencia ha decidido que Ismael, el de los recados, necesita saber dónde se encuentran los archivos que necesita copiar y necesita poder imprimirlos, esto cumple con los criterios de necesidad de saber de Ismael. Ahora, un administrador podría darle a Ismael el control total de todos los archivos que necesita copiar, pero eso no sería practicar el principio de privilegio mínimo. El administrador debe restringir los derechos y permisos de Ismael para que solo pueda leer e imprimir los archivos necesarios, y nada más. Además, si Ismael borra accidentalmente todos los archivos en todo el servidor de archivos, ¿a quién cree que la administración responsabilizará en última instancia? Sí, el administrador.
Es importante comprender que es trabajo de la administración de sistemas, determinar los requisitos de seguridad de las personas y cómo se autoriza el acceso. El administrador de seguridad configura los mecanismos de seguridad para cumplir con estos requisitos, pero no es su trabajo determinar los requisitos de seguridad de los usuarios. Esos deben dejarse a los propietarios de los activos. Si hay una brecha de seguridad, la administración de sistemas, será responsable en última instancia, por lo que debe tomar estas decisiones en primer lugar.
Inicio de sesión único
¡Solo quiero tener que recordar un nombre de usuario y una contraseña para todo en el mundo! Muchas veces los empleados necesitan acceder a muchas computadoras, servidores, bases de datos y otros recursos diferentes en el transcurso del día para completar sus tareas. Esto a menudo requiere que los empleados recuerden múltiples ID de usuario y contraseñas para estas diferentes computadoras. En una utopía, un usuario necesitaría ingresar solo una identificación de usuario y una contraseña para poder acceder a todos los recursos en todas las redes en las que este usuario está trabajando. En el mundo real, esto es difícil de lograr para todos los tipos de sistemas. Debido a la proliferación de tecnologías cliente/servidor, las redes han migrado de redes controladas centralmente a entornos heterogéneos y distribuidos. La propagación de los sistemas abiertos y la mayor diversidad de aplicaciones, plataformas y sistemas operativos han provocado que el usuario final tenga que recordar varios ID de usuario y contraseñas solo para poder acceder y utilizar los diferentes recursos dentro de su propia red. Aunque se supone que las diferentes ID y contraseñas brindan un mayor nivel de seguridad, a menudo terminan comprometiendo la seguridad (porque los usuarios las anotan) y provocando más esfuerzo y gastos generales para el personal que administra y mantiene la red.
Como puede verse, cualquier miembro del personal o administrador de la red, se dedica demasiado tiempo a restablecer las contraseñas de los usuarios que las han olvidado, sobre todo en los meses de agosto y septiembre.
La productividad de más de un empleado se ve afectada cuando se deben reasignar las contraseñas olvidadas. El miembro del personal de la red que tiene que restablecer la contraseña podría estar trabajando en otras tareas, y el usuario que olvidó la contraseña no puede completar su tarea hasta que el miembro del personal de la red termine de restablecer la contraseña.
Los administradores del sistema tienen que administrar varias cuentas de usuario en diferentes plataformas, y todas deben coordinarse de manera que se mantenga la integridad de la política de seguridad. A veces, la complejidad puede ser abrumadora, lo que
da como resultado una mala gestión del control de acceso y la generación de muchas vulnerabilidades de seguridad. Se dedica mucho tiempo a múltiples contraseñas, y al final no nos aportan más seguridad. El mayor costo de administrar un entorno diverso, las preocupaciones de seguridad y los hábitos de los usuarios, junto con el enorme trabajo para los usuarios de recordar un conjunto de credenciales, ha dado lugar a la idea de las capacidades de inicio de sesión único (SSO) . Estas capacidades permitirían a un usuario ingresar las credenciales una vez y poder acceder a todos los recursos en los dominios de red primarios y secundarios. Esto reduce la cantidad de tiempo que los usuarios dedican a autenticarse en los recursos y permite al administrador optimizar las cuentas de usuario y controlar mejor los derechos de acceso. Mejora la seguridad al reducir la probabilidad de que los usuarios escriban las contraseñas y también reduce el tiempo que el administrador dedica a agregar y eliminar cuentas de usuario y modificar los permisos de acceso. Si un administrador necesita deshabilitar o suspender una cuenta específica, puede hacerlo de manera uniforme en lugar de tener que modificar las configuraciones en todas y cada una de las plataformas.
Así que esa la utopía: inicie sesión una vez y estará listo para comenzar. Principalmente problemas de interoperabilidad. Para que SSO realmente funcione, cada plataforma, aplicación y recurso debe aceptar el mismo tipo de credenciales, en el mismo formato e interpretar sus significados de la misma manera. Cuando Rosa inicia sesión en su ordenador de trabajo con Windows 11 y es autenticado por un controlador de dominio de modo mixto de Windows 2019, debe autenticarlo en los recursos a los que necesita acceder en el ordenador de archivos, el servidor de impresoras, el servidor base de datos, etc. Y esa es la problemática fundamental de la gestión de identidades.
Conclusión
En resumen, la autorización es un proceso de dos pasos en el cual se determina si un individuo está autorizado a acceder a un recurso específico y qué acciones puede realizar en ese recurso. Es un componente central de cada sistema operativo y también puede proporcionarlo aplicaciones, paquetes de seguridad y recursos. La autenticación es el primer paso en el proceso de autorización en el cual el usuario debe demostrar su identidad, mientras que la autorización es el segundo paso en el cual se verifica si el usuario tiene los derechos y permisos para acceder al recurso en cuestión.
Los criterios de acceso son la clave para la autorización y estos pueden ser basados en roles, grupos, ubicación, hora y tipos de transacciones. Por ejemplo, un usuario puede tener acceso solo a ciertos recursos durante ciertas horas del día, o solo a ciertos recursos si se encuentra en una ubicación específica. También pueden ser basados en roles, donde un usuario con un rol específico tiene acceso a ciertos recursos, mientras que un usuario con un rol diferente no tiene acceso.
En conclusión, la autorización es un proceso esencial en cualquier sistema de información para garantizar que solo los usuarios autorizados tengan acceso a los recursos y que solo puedan realizar acciones permitidas. Los criterios de acceso son la clave para la autorización y deben basarse en el nivel de confianza y necesidad de saber del usuario. La implementación adecuada de estos criterios de acceso ayudará a garantizar una seguridad adecuada y un uso eficiente de los recursos.
Una piedra angular en la base de la seguridad de la información es controlar cómo se accede a los recursos para que puedan protegerse de modificaciones o divulgaciones no autorizadas. Los controles que hacen cumplir el control de acceso pueden ser de naturaleza técnica, física o administrativa. Estos tipos de control deben integrarse en la documentación basada en políticas, el software y la tecnología, el diseño de la red y los componentes de seguridad física. El acceso es uno de los aspectos más explotados de la seguridad, porque es la puerta que conduce a los activos críticos. Los controles de acceso deben aplicarse en un método de defensa en profundidad en capas, y es extremadamente importante comprender cómo se explotan estos controles. La idea de esta lección es explorar conceptualmente el control de acceso y luego profundizaremos en las tecnologías que la industria implementa para hacer cumplir estos conceptos. También veremos los métodos comunes que usan los malos para atacar estas tecnologías.
Descripción general de los controles de acceso
Los controles de acceso son características de seguridad que controlan cómo los usuarios y los sistemas se comunican e interactúan con otros sistemas y recursos. Protegen los sistemas y los recursos del acceso no autorizado y pueden ser componentes que participen en la determinación del nivel de autorización después de que se haya completado con éxito un procedimiento de autenticación. Aunque generalmente pensamos en un usuario como la entidad que requiere acceso a un recurso o información de la red, hay muchos otros tipos de entidades que requieren acceso a otras entidades y recursos de la red que están sujetos a control de acceso. Es importante comprender la definición de un sujeto y un objeto cuando se trabaja en el contexto del control de acceso. El acceso es el flujo de información entre un sujeto y un objeto. Un sujeto es una entidad activa que solicita acceso a un objeto o a los datos dentro de un objeto. Un sujeto puede ser un usuario, programa o proceso que accede a un objeto para realizar una tarea. Cuando un programa accede a un archivo, el programa es el sujeto y el archivo es el objeto. Un objeto es una entidad pasiva que contiene información o funcionalidad necesaria. Un objeto puede ser un ordenador, una base de datos, un archivo, un programa, un directorio o un campo contenido en una tabla dentro de una base de datos. Cuando busca información en una base de datos, tú eres el sujeto activo y la base de datos es el objeto pasivo.
El control de acceso es un término amplio que cubre varios tipos diferentes de mecanismos que hacen cumplir las funciones de control de acceso en los sistemas informáticos, las redes y la información. El control de acceso es extremadamente importante porque es una de las primeras líneas de defensa en la lucha contra el acceso no autorizado a los sistemas y recursos de la red. Cuando a un usuario se le solicita un nombre de usuario y una contraseña para usar un ordenador, esto es control de acceso. Una vez que el usuario inicia sesión y luego intenta acceder a un archivo, ese archivo puede tener una lista de usuarios y grupos que tienen derecho a acceder a él. Si el usuario no está en esta lista, el usuario es denegado. Esta es otra forma de control de acceso. Los permisos y derechos de los usuarios pueden basarse en su identidad, autorización y/o pertenencia a un grupo. Los controles de acceso brindan a las organizaciones la capacidad de controlar, restringir, monitorear y proteger la disponibilidad, integridad y confidencialidad de los recursos.
Principios de seguridad CIA
Los tres principios fundamentales de seguridad para cualquier tipo de control de seguridad son
Disponibilidad
Integridad
Confidencialidad
Estos principios, los conocemos todos, por lo que no vamos a entrar en su definición, tan solo indicar que los procedimientos de gestión de la seguridad incluyen la identificación de amenazas que pueden afectar negativamente la disponibilidad, integridad y confidencialidad de los activos de la empresa y la búsqueda de contramedidas rentables que los protejan. Aquí vamos a ver las formas en que los tres principios pueden verse afectados y protegidos a través de metodologías y tecnologías de control de acceso. Cada control que se utiliza en la seguridad informática y de la información proporciona al menos uno de estos principios de seguridad. Es fundamental que los profesionales de la seguridad entiendan todas las formas posibles en que se pueden proporcionar y eludir estos principios. Es importante que una empresa identifique los datos que deben clasificarse para que la empresa pueda garantizar que la máxima prioridad de seguridad protege esta información y la mantiene confidencial. Si no se destaca esta información, se puede gastar demasiado tiempo y dinero en implementar el mismo nivel de seguridad para información crítica y no crítica por igual. Puede ser necesario configurar redes privadas virtuales (VPN) entre organizaciones y usar el protocolo de encriptación IPSec para encriptar todos los mensajes que se transmiten al comunicarse sobre secretos comerciales, compartir información de clientes o realizar transacciones financieras. Esto requiere una cierta cantidad de hardware, mano de obra, fondos y gastos generales. Las mismas precauciones de seguridad no son necesarias al comunicar una nueva incorporación de un compañero, o el menú del día de la cafetería de la esquina. Entonces, el primer paso para proteger la confidencialidad de los datos es identificar qué información es sensible y en qué grado, y luego implementar mecanismos de seguridad para protegerla adecuadamente. Diferentes mecanismos de seguridad pueden proporcionar diferentes grados de disponibilidad, integridad y confidencialidad. El entorno, la clasificación de los datos que se van a proteger y los objetivos de seguridad deben evaluarse para garantizar que se compran y se implementan los mecanismos de seguridad adecuados. Muchas organizaciones han desperdiciado mucho tiempo y dinero al no seguir estos pasos y en su lugar comprar el nuevo producto “gee whiz” que recientemente llegó al mercado.
Identificación, Autenticación, Autorización y Responsabilidad
Para que un usuario pueda acceder a un recurso, primero debe demostrar que es quien dice ser, tiene las credenciales necesarias y se le han otorgado los derechos o privilegios necesarios para realizar las acciones que solicita. Una vez que estos pasos se completan con éxito, el usuario puede acceder y utilizar los recursos de la red; sin embargo, es necesario realizar un seguimiento de las actividades del usuario y monitorizar sus acciones (recordar la “trazabilidad” del ENS, como una de las dimensiones adicionales a las ya conocidas). La identificación describe un método para garantizar que un sujeto (usuario, programa o proceso) es la entidad que dice ser. La identificación se puede proporcionar con el uso de un nombre de usuario o número de cuenta. Para ser debidamente autenticado, por lo general se requiere que el sujeto proporcione una segunda parte del conjunto de credenciales. Esta pieza podría ser una contraseña, frase de contraseña, clave criptográfica número de identificación (PIN), atributo anatómico o token. Estos dos elementos de credenciales se comparan con la información que se ha almacenado previamente para este tema. Si estas credenciales coinciden con la información almacenada, el sujeto se autentica. Pero aún no hemos terminado.
Una vez que el sujeto proporciona sus credenciales y está debidamente identificado, el sistema al que intenta acceder debe determinar si se le han otorgado a este sujeto los derechos y privilegios necesarios para llevar a cabo las acciones solicitadas. El sistema buscará algún tipo de matriz de control de acceso o comparará las etiquetas de seguridad para verificar que este sujeto pueda acceder al recurso solicitado y realizar las acciones que está intentando. Si el sistema determina que el sujeto puede acceder al recurso, autoriza al sujeto. Aunque la identificación, la autenticación, la autorización y monitorización y registro tienen definiciones cercanas y complementarias, cada una tiene funciones distintas que cumplen un requisito específico en el proceso de control de acceso. Un usuario puede estar debidamente identificado y autenticado en la red, pero es posible que no tenga autorización para acceder a los archivos del servidor de archivos. Por otro lado, un usuario puede estar autorizado para acceder a los archivos en el servidor de archivos, pero hasta que esté debidamente identificado y autenticado, esos recursos están fuera de su alcance. La siguiente imagen muestra los cuatro pasos que deben darse para que un sujeto acceda a un objeto.
El sujeto debe ser responsable por las acciones realizadas dentro de un sistema o dominio. La única manera de garantizar que fue esa persona y no otra, es si el sujeto se identifica de forma única y se registran las acciones del sujeto. Por eso se repite siempre el mantra de que las contraseñas son únicas e intransferibles. Los controles de acceso lógico son herramientas técnicas que se utilizan para la identificación, la autenticación, la autorización y la responsabilidad. Son componentes de software que imponen medidas de control de acceso para sistemas, programas, procesos e información. Los controles de acceso lógico pueden integrarse en sistemas operativos, aplicaciones, paquetes de seguridad complementarios o sistemas de administración de bases de datos y telecomunicaciones. Puede ser un desafío sincronizar todos los controles de acceso y garantizar que todas las vulnerabilidades estén cubiertas sin producir superposiciones de funcionalidad. La identidad de una persona debe verificarse durante el proceso de autenticación. La autenticación generalmente implica un proceso de dos pasos: ingresar información pública (un nombre de usuario, número de empleado, número de cuenta o ID de departamento) y luego ingresar información privada (una contraseña estática, un token inteligente, una contraseña cognitiva, una contraseña de un solo uso, o PIN). El ingreso de información pública es el paso de identificación, mientras que el ingreso de información privada es el paso de autenticación del proceso de dos pasos. Cada técnica utilizada para la identificación y autenticación tiene sus pros y sus contras. Cada uno debe evaluarse adecuadamente para determinar el mecanismo correcto para el entorno correcto.
Identificación y autenticación
Una vez que una persona ha sido identificada mediante el ID de usuario o un valor similar, debe ser autenticada, lo que significa que debe demostrar que es quien dice ser. Se pueden usar tres factores generales para la autenticación: algo que una persona sabe, algo que una persona tiene y algo que una persona es. También se denominan comúnmente autenticación por conocimiento, autenticación por propiedad y autenticación por característica. Algo que una persona sabe (autenticación por conocimiento) puede ser, por ejemplo, una contraseña, un PIN, el apellido de soltera de la madre o la combinación de un candado. Autenticar a una persona por algo que ella sabe suele ser lo menos costoso de implementar. La desventaja de este método es que otra persona puede adquirir este conocimiento y obtener acceso no autorizado a un recurso.
Algo que una persona tiene (autenticación por propiedad) puede ser una llave, una tarjeta magnética, una tarjeta de acceso o una credencial. Este método es común para acceder a instalaciones, pero también podría usarse para acceder a áreas confidenciales o para autenticar sistemas. Una desventaja de este método es que el artículo puede perderse o ser robado, lo que podría resultar en un acceso no autorizado. Algo específico de una persona (autenticación por característica) se vuelve un poco más interesante. Esto no se basa en si la persona es alta, baja, rubia, morena, hombre o mujer; se basa en un atributo físico. La autenticación de la identidad de una persona basada en un atributo físico único se conoce como biometría. La autenticación fuerte contiene dos de estos tres métodos: algo que una persona sabe, tiene o es. El uso de un sistema biométrico por sí solo no proporciona una autenticación sólida porque proporciona solo uno de los tres métodos. La biometría proporciona lo que una persona es, no lo que una persona sabe o tiene. Para que exista un proceso de autenticación sólido, se debe combinar un sistema biométrico con un mecanismo que verifique uno de los otros dos métodos. Por ejemplo, muchas veces la persona tiene que escribir un número PIN en un teclado antes de realizar el escaneo biométrico. Esto satisface la categoría “lo que la persona sabe”. Por el contrario, se le podría solicitar a la persona que pase una tarjeta magnética a través de un lector antes del escaneo biométrico. Esto satisfaría la categoría “lo que la persona tiene”. Cualquiera que sea el sistema de identificación que se utilice, para que la autenticación fuerte esté en el proceso, debe incluir dos de las tres categorías. Esto también se conoce como autenticación de dos factores.
La identidad es un concepto complicado con muchos matices variados, que van desde lo filosófico hasta lo práctico. Una persona puede tener múltiples identidades digitales. Por ejemplo, un usuario puede ser JPublic en un entorno de dominio de Windows, JuanP en un servidor Unix, JuanPublic en el acceso al correo, JJP en mensajería instantánea, JuanCPublic en la autoridad de certificación y JuanFB en Facebook. Ahora imagina, si una empresa quisiera centralizar todo su control de acceso, estos diversos nombres de identidad para la misma persona pueden ir metiendo al administrador de seguridad en una institución de salud mental, vamos un manicomio porque se va a volver loco. La creación o emisión de identidades seguras debe incluir tres aspectos clave: singularidad, no descriptivo y emisión. El primero, la unicidad, se refiere a los identificadores que son específicos de un individuo, lo que significa que cada usuario debe tener una identificación única para la responsabilidad que le toca. Cosas como las huellas dactilares y los escáneres de retina pueden considerarse elementos únicos para determinar la identidad. No descriptivo significa que ninguna parte del conjunto de credenciales debe indicar el propósito de esa cuenta. Por ejemplo, una identificación de usuario no debe ser “administrador”, “backup_operator” o “CEO”. El tercer aspecto clave para determinar la identidad es la emisión. Estos elementos son los que han sido aportados por otra autoridad como medio de acreditación de la identidad. Las tarjetas de identificación son un tipo de elemento de seguridad que se consideraría una forma de emisión de identificación. Si bien nos estamos centrando ahora en la autenticación de usuarios, es importante darse cuenta de que la autenticación basada en el sistema también es posible. Los ordenadores y los dispositivos pueden identificarse, autenticarse, monitorearse y controlarse en función de sus direcciones de hardware (control de acceso a medios) y/o direcciones de Protocolo de Internet (IP). Las redes pueden tener tecnología de control de acceso a la red (NAC) que autentica los sistemas antes de que se le permita el acceso a la red. Cada dispositivo de red tiene una dirección de hardware que está integrada en su tarjeta de interfaz de red y una dirección basada en software (IP), que es asignada por un servidor DHCP o configurada localmente. La gestión de identidades es un término amplio y cargado que abarca el uso de diferentes productos para identificar, autenticar y autorizar a los usuarios a través de medios automatizados. Para muchas personas, el término también incluye administración de cuentas de usuario, control de acceso, administración de contraseñas, funcionalidad de inicio de sesión único, administración de derechos y permisos para cuentas de usuario, y auditoría y monitoreo de todos estos elementos. La razón por la que las personas y las empresas tienen diferentes definiciones y perspectivas de la gestión de identidades (IdM) es que es muy grande y abarca tantas tecnologías y procesos diferentes.
¿Recuerdas la historia de los cuatro ciegos que tratan de describir un elefante? Un ciego palpa la cola y anuncia: “Es una cola”. Otro ciego palpa la trompa y anuncia: “Es un trompa”. Otro anuncia que es una pierna y otro anuncia que es una oreja. Esto se debe a que cada hombre no puede ver o comprender la totalidad del elefante, solo la parte con la que está familiarizado y conoce. Esta analogía se puede aplicar a IdM porque es grande y contiene muchos componentes y es posible que muchas personas no comprendan el todo, solo el componente con el que trabajan y entienden.
Es importante que los profesionales de la seguridad comprendan no solo la totalidad de IDM, sino también las tecnologías que componen una solución completa del mismo. IDM requiere la gestión de entidades identificadas de forma única, sus atributos, credenciales y derechos. IdM permite a las organizaciones crear y administrar los ciclos de vida de las identidades digitales (crear, mantener, terminar) de manera oportuna y automatizada. El IDM empresarial debe satisfacer las necesidades comerciales y escalar desde sistemas internos a sistemas externos.
La venta de productos de administración de identidad es ahora un mercado en continuo crecimiento, sobre todo en España cuando aprobó en 2019, el Real Decreto-ley 8/2019. Un texto legal más conocido como “ley de control horario”. Que establece realizar un control horario de los empleados. Por lo que lo más sencillo es mediante sistemas de control de acceso con molinetes, huella dactilar, o como tienen algunas entidades públicas un ordenador de registro. La parte positiva es que, estos disipativos, aumentar la seguridad de acceso, tienen un registro de entrada y salida del personal, además de cumplir con las normas. El aumento continuo de la complejidad y la diversidad de los entornos en red solo aumenta la complejidad de realizar un seguimiento de quién puede acceder a qué y cuándo. Las organizaciones tienen diferentes tipos de aplicaciones, sistemas operativos de red, bases de datos, sistemas de administración de recursos empresariales (ERM), sistemas de administración de relaciones con los clientes (CRM), directorios, marcos principales, todos utilizados para diferentes propósitos comerciales. Entonces las organizaciones tienen socios, proveedores, consultores, empleados y empleados temporales.
Los usuarios generalmente acceden a varios tipos diferentes de sistemas a lo largo de sus tareas diarias, lo que hace que controlar el acceso y brindar el nivel necesario de protección en diferentes tipos de datos sea difícil y lleno de obstáculos. Esta complejidad generalmente da como resultado agujeros imprevistos y no identificados en la protección de activos, controles superpuestos y contradictorios, e incumplimiento de políticas y regulaciones. El objetivo de las tecnologías de gestión de identidad es simplificar la administración de estas tareas y poner orden en el caos.
Las siguientes son muchas de las preguntas comunes que las empresas enfrentan hoy en día en controlar el acceso a los activos:
¿A qué debe tener acceso cada usuario?
¿Quién aprueba y permite el acceso?
¿Cómo se relacionan las decisiones de acceso con las políticas?
¿Los ex empleados todavía tienen acceso?
¿Cómo nos mantenemos al día con nuestro entorno dinámico y en constante cambio?
¿Cuál es el proceso de revocación de acceso?
¿Cómo se controla y supervisa el acceso de forma centralizada?
¿Por qué los empleados tienen que recordar ocho contraseñas?
El proceso tradicional de administración de identidades ha sido manual, utilizando servicios de directorio con permisos, listas de control de acceso (ACL) y perfiles. Este enfoque ha demostrado ser incapaz de mantenerse al día con demandas complejas y, por lo tanto, ha sido reemplazado por aplicaciones automatizadas ricas en funcionalidad que trabajan juntas para crear una infraestructura de gestión de identidad. Los objetivos principales de las tecnologías de gestión de identidad (IdM) son optimizar la gestión de identidad, autenticación, autorización y auditoría de sujetos en múltiples sistemas en toda la empresa. La gran diversidad de una empresa heterogénea hace que la implementación adecuada de IdM sea una tarea enorme. Dentro de las soluciones de identidad, podemos enumerar la de Directorios, Gestión de acceso web, gestión de contraseñas, gestión de cuentas, entre otras.
Una de las soluciones de identidad a destacar son los gestores de contraseñas, toda organización debería tener a nivel interno un gestor de contraseñas. Si, a nivel interno, sino pensar lo que le paso al sitio web “lastpass.com” recientemente.
Pensar que las contraseñas son los mecanismos de autenticación más utilizados, también se consideran uno de los mecanismos de seguridad más débiles disponibles. ¿Por qué? Los usuarios generalmente eligen contraseñas que son fáciles de adivinar (el nombre de su pareja, la fecha de nacimiento de un hijo o el nombre de un perro), o le dicen a otros sus contraseñas, y muchas veces escriba las contraseñas en una nota adhesiva y ocúltelas hábilmente debajo del teclado.
Para la mayoría de los usuarios, la seguridad generalmente no es la parte más importante o interesante en su trabajo, excepto cuando alguien hackea y roba información confidencial. Entonces la seguridad se vuelve moda, al menos por unos meses.
Aquí es donde interviene la gestión de contraseñas. Si las contraseñas se generan, actualizan y mantienen en secreto correctamente, pueden proporcionar una seguridad eficaz.
Los generadores de contraseñas se pueden utilizar para crear contraseñas para los usuarios. Esto asegura que un usuario no usará “12345678″ o “10021993″ como contraseña, pero si el generador crea “kdjasijew284802h”, el usuario seguramente lo escribirá en una hoja de papel y lo pegará de manera segura al monitor. Lo que anula todo el propósito. Si se va a utilizar un generador de contraseñas, también se deberá usar un gestor de contraseñas que les permita a los usuarios guardarlas.
Si los usuarios pueden elegir sus propias contraseñas, el sistema operativo debería imponer ciertos requisitos de contraseña. El sistema operativo puede requerir que una contraseña contenga una cierta cantidad de caracteres, no relacionados con la ID de usuario, que incluya caracteres especiales, que incluya letras mayúsculas y minúsculas y que no sea fácil de adivinar. El sistema operativo puede realizar un seguimiento de las contraseñas que genera un usuario específico para garantizar que no se reutilicen contraseñas. Los usuarios también deberían estar obligados a cambiar sus contraseñas periódicamente. Todos estos factores dificultan que un atacante adivine u obtenga contraseñas dentro del entorno. Si un atacante busca una contraseña, puede probar algunas técnicas diferentes:
Ataque de MiTM: Escuchar el tráfico de la red para capturar información, especialmente cuando un usuario está enviando su contraseña a un servidor de autenticación. El atacante puede copiar y reutilizar la contraseña en otro momento, lo que se denomina ataque de repetición.
Acceder al archivo de contraseñas Normalmente se realiza en el servidor de autenticación. O en máquinas locales con esos clásicos excels llamados “contraseñas” El archivo de contraseñas contiene las contraseñas de muchos usuarios y, si se ve comprometida, puede causar muchos daños. Este archivo debe estar protegido con mecanismos de control de acceso y encriptación.
Ataques de fuerza bruta Realizados con herramientas que recorren muchas combinaciones posibles de caracteres, números y símbolos para descubrir una contraseña.
Ataques de diccionario Los archivos de miles de palabras se comparan con la contraseña del usuario hasta que se encuentra una coincidencia. Po eso se debe poner un umbral de errores, por ejemplo al tercer intento fallido, bloquear la cuenta.
Ingeniería social: Un atacante convence a una persona de que tiene la autorización necesaria para acceder a determinados recursos.
Rainbow table: Un atacante utiliza una tabla que contiene todas las contraseñas posibles ya en formato hash.
Se pueden implementar ciertas técnicas para proporcionar otra capa de seguridad para las contraseñas y su uso. Después de cada inicio de sesión exitoso, se puede presentar un mensaje a un usuario que indica la fecha y la hora del último inicio de sesión exitoso, la ubicación de este inicio de sesión y si hubo intentos de inicio de sesión fallidos. Esto alerta al usuario sobre cualquier actividad sospechosa y si alguien ha intentado iniciar sesión con sus credenciales. Además, ya es un requisito del ENS, por lo que también se estaría cumpliendo con el ENS al implementarlo.
Conclusiones
El control de acceso es un aspecto clave en la seguridad de la información, ya que controla cómo los usuarios y los sistemas acceden a los recursos para protegerlos de modificaciones o divulgaciones no autorizadas. Los controles de acceso pueden ser de naturaleza técnica, física o administrativa, y deben integrarse en políticas, software, tecnología, diseño de red y componentes de seguridad física. El acceso es un aspecto crítico que es a menudo explotado por atacantes, por lo que es importante entender cómo se explotan estos controles y cómo defenderlos. Los controles de acceso se refieren a mecanismos que controlan cómo los usuarios y los sistemas interactúan con otros sistemas y recursos, protegiendo así contra el acceso no autorizado.
La Identificación, Autenticación, Autorización y Responsabilidad son pasos necesarios para garantizar el acceso seguro a un recurso. La Identificación consiste en asegurar que un sujeto es quien dice ser, mientras que la Autenticación implica verificar las credenciales del sujeto. La Autorización determina si el sujeto tiene los derechos y privilegios necesarios para acceder al recurso. Por último, es importante monitorear y registrar las acciones del usuario y asegurar la responsabilidad por estas acciones.
Los sistemas de IDM e IAM suelen formar parte de la seguridad de TI y la administración de datos de TI dentro de la empresa. Hay herramientas de gestión de identidades y acceso disponibles para la amplia gama de dispositivos que los usuarios utilizan para ejecutar tareas empresariales, desde teléfonos y tabletas hasta ordenadores de sobremesa con Windows, Linux, iOS o Android.
IDM e IAM son términos que a menudo se usan indistintamente, sin embargo, la gestión de identidades se centra más en la identidad de un usuario (o nombre de usuario), sus roles y permisos, y los grupos a los que pertenece. IDM también se enfoca a proteger las identidades a través de varias tecnologías, como contraseñas, biometría, autenticación multifactor y otras identidades digitales. Esto suele lograrse mediante la adopción de aplicaciones y plataformas de software de gestión de identidades.
Funcionamiento de la gestión de identidades
Como parte del marco general de IAM que cubre la gestión del acceso y la de identidades, las empresas suelen utilizar componentes tanto de gestión de usuarios como de directorio central, como pueden ser o Apache Directory Studio, Open LDAP para sistemas Linux, o Active Directory para Windows.
El componente de gestión de usuarios se ocupa de delegar la autoridad administrativa, efectuar el seguimiento de roles y responsabilidades para cada usuario y grupo, aprovisionar y desaprovisionar cuentas de usuario y, gestionar las contraseñas. La totalidad o parte de estas funciones, como el restablecimiento de contraseñas, suelen ser de autoservicio para reducir la carga del personal de TI. El directorio central es un repositorio que contiene todos los datos sobre los usuarios y grupos de la empresa. Como tal, una función importante de este componente es sincronizar el directorio o repositorio en toda la empresa, lo que puede abarcar componentes locales y de nube privada o pública. Esto permite una vista única de los usuarios y sus permisos en cualquier momento y lugar de una infraestructura de nube híbrida o multinube. Un marco de IAM también incluye dos componentes de acceso. La autenticación se ocupa de asuntos como el inicio de sesión (y el inicio de sesión único), la gestión de sesiones activas y la implementación de una autenticación sólida mediante llaves o dispositivos biométricos. La autorización usa los roles, atributos y reglas del registro de usuario para determinar si un usuario, dispositivo o aplicación en particular debe tener acceso a un recurso.
¿Qué diferencia hay entre la gestión de identidades y la gestión del acceso?
Gestión de identidades
La identidad digital es la clave para el acceso. Las identidades contienen la información y los atributos que definen un rol. En concreto, permiten o impiden el acceso a un recurso específico, e informan a otros usuarios de la organización sobre el dueño de la identidad, cómo contactarle si es una persona y dónde encajan en la jerarquía general de la empresa. Crear una identidad puede repercutir en toda la organización, por ejemplo, al crear una cuenta de correo electrónico, configurar un registro del empleado o generar una entrada en un organigrama. Las identidades son como seres vivos que pueden cambiar con el tiempo, por ejemplo, si un empleado asume un nuevo rol o se traslada a un nuevo lugar de trabajo.
La gestión de identidades se ocupa del seguimiento y la gestión de los cambios en los atributos y las entradas que definen las identidades en el repositorio de la empresa. Por lo general, estos cambios solo pueden implementarlos unas pocas personas selectas en la organización, como un representante de recursos humanos que anote un cambio en el salario, o el propietario de una aplicación que otorgue a un grupo de empleados (por ejemplo, representantes del servicio al cliente) acceso a una nueva función del sistema de gestión de relaciones con el cliente (CRM).
Gestión del acceso
La gestión del acceso es la autenticación de una identidad que solicita acceso a un recurso en particular, y las decisiones de acceso son simplemente la respuesta afirmativa o negativa a permitirlo.
Este puede ser un proceso escalonado, con servicios de acceso que determinan si un usuario está autorizado para acceder a la red en general, y niveles inferiores de acceso que autentican las ubicaciones a las que la identidad puede acceder en servidores, unidades, carpetas, archivos y aplicaciones específicos.
Recuerde que la autenticación no es lo mismo que la autorización. Aunque una identidad (usuario) pueda estar autorizada para entrar en la red corporativa y tenga una cuenta en el directorio, esto no le otorga automáticamente la capacidad de acceder a todas las aplicaciones de toda la empresa. La autorización para cada aplicación o recurso la determinan los atributos de la identidad, como a qué grupos pertenece, su nivel en la organización o un rol específico que se le haya asignado previamente.
Al igual que ocurre con la autenticación, la autorización puede ocurrir a distintos niveles dentro de la organización, por ejemplo, como un servicio centralizado y nuevamente a nivel local para una aplicación o recurso específicos. No obstante, la autenticación a nivel de recurso o servicio no goza de buena fama, ya que la autenticación central proporciona un control más coherente.
La diferencia entre la gestión de identidades y la gestión del acceso
Se puede simplificar de la siguiente forma:
La gestión de identidades consiste en gestionar los atributos relacionados con el usuario, el grupo de usuarios u otra identidad que pueda requerir acceso de vez en cuando.
La gestión del acceso consiste en evaluar estos atributos en función de las políticas existentes y tomar una decisión de acceso (afirmativa o negativa) según los atributos.
¿Para qué necesitamos la gestión de identidades?
Un estudio reciente (ISC)² reveló que el 80 % de vulneraciones se debieron a problemas en la identidad de acceso, es decir, credenciales débiles o mal gestionadas. Si no se implementan los controles adecuados, o no se siguen correctamente los procedimientos y procesos de IAM, es posible que las contraseñas se vean comprometidas, que se pongan en marcha ataques de suplantación de identidad o que tengan lugar vulneraciones y ataques de programas de secuestro. Afortunadamente, las plataformas IAM modernas permiten automatizar muchas de las funciones que ayudan a garantizar que se apliquen los controles, como, por ejemplo, eliminar a un usuario del directorio cuando el sistema de recursos humanos indique que el empleado ha dejado la organización.
Dada la frecuente aparición de legislación nueva sobre la privacidad y la información confidencial, IAM puede desempeñar otro papel importante: el de ayudar a la organización a cumplir con la gran cantidad de exigencias normativas y de control, garantizando que los datos se encuentren en la ubicación adecuada y que solo los usuarios autorizados tengan acceso a ellos. Al final, la seguridad de TI concierne principalmente al acceso, por lo que una estrategia de IAM sólida es un elemento fundamental de la seguridad de TI general y ofrece una primera línea de protección ante cualquier amenaza, ya provenga de fuera o de dentro del cortafuegos.
Ventajas empresariales de la gestión de identidades
La capacidad para proteger con éxito los activos, incluidos los digitales, puede repercutir directamente en los beneficios de la organización y en su valor total. IAM acelera la rentabilidad para cualquier persona que necesite acceder a los recursos empresariales para realizar su trabajo, a menudo acortando de días a minutos el tiempo transcurrido entre la incorporación de un nuevo empleado y el momento en el que obtiene acceso a los recursos del sistema.
Además del aumento en el valor comercial como resultado de la seguridad mejorada, existen otras ventajas empresariales tangibles. Automatizar las tareas de IAM libera al departamento de TI y le permite centrarse en proyectos enfocados a los beneficios. Las herramientas de gestión de identidades de autoservicio mejoran la productividad general de los empleados, los trabajadores externos y otros usuarios que deban acceder a los recursos corporativos.
Implementar un marco general de IAM puede brindar oportunidades de crecimiento, ya que mejora la escalabilidad de los servicios que son esenciales para la incorporación de nuevos usuarios. Al requerir menos personal de TI, se mejora el ROI de la organización de TI en general.
La gestión de identidades y del acceso se ha convertido en la base de todas estas ventajas empresariales, y continúa protegiendo a la empresa de amenazas que podrían conducir al robo de datos, a ataques maliciosos o a la vulneración de información confidencial legal, de clientes o de pacientes.
Desafíos de implementar la gestión de identidades
Para implementar la gestión de identidades, una empresa debe poder planificar y colaborar en todas las unidades de negocio. Es más probable que las organizaciones exitosas sean aquellas que establezcan estrategias de gestión de identidad con objetivos claros, procesos comerciales definidos y la aceptación de las partes interesadas desde el principio. La gestión de identidades funciona mejor cuando están involucrados los departamentos de TI, seguridad, recursos humanos y otros.
Los sistemas de gestión de identidades deben permitir a las empresas gestionar automáticamente múltiples usuarios en diferentes situaciones y entornos informáticos en tiempo real. Es mucho más lento ajustar manualmente los privilegios de acceso y los controles de acceso para cientos o miles de usuarios. Además, la autenticación debe ser simple de realizar para los usuarios y fácil de implementar y proteger para TI.
Uno de los principales desafíos en la implementación de la gestión de identidades es la gestión de contraseñas. Los profesionales de TI deben investigar técnicas que puedan reducir el impacto de estos problemas con las contraseñas en sus empresas.
Por motivos de seguridad, las herramientas para manejar la gestión de identidades deben ejecutarse como una aplicación en un servidor o dispositivo de red dedicado. En el núcleo de un sistema de gestión de identidad se encuentran las políticas que definen qué dispositivos y usuarios pueden acceder a la red y qué puede lograr un usuario, según el tipo de dispositivo, la ubicación y otros factores. Todo esto también depende de la funcionalidad adecuada de la consola de administración. Esto incluye la definición de políticas, informes, alertas, alarmas y otros requisitos comunes de gestión y operaciones. Se puede activar una alarma, por ejemplo, cuando un usuario específico intenta acceder a un recurso para el que no tiene permiso. La presentación de informes produce un registro de auditoría que documenta qué actividades específicas se iniciaron.
Muchos sistemas de administración de identidades ofrecen integración de directorios, soporte para usuarios con cable e inalámbricos y la flexibilidad para cumplir con casi cualquier requisito de política operativa y de seguridad. Debido a que traer su propio dispositivo (BYOD) es tan estratégico hoy en día, las funciones que ahorran tiempo son compatibles con una variedad de sistemas operativos móviles y la verificación automatizada del estado del dispositivo se está volviendo común. Las funciones para ahorrar tiempo pueden incluir la incorporación y el aprovisionamiento automatizados de dispositivos.
Beneficios comerciales de la gestión de identidades
Además de administrar a los empleados, el uso de la administración de identidades junto con la administración de acceso permite a una empresa administrar el acceso de clientes, socios, proveedores y dispositivos a sus sistemas, mientras que la seguridad es la máxima prioridad.
Este objetivo se puede lograr en varios frentes, comenzando por permitir el acceso autorizado desde cualquier lugar. A medida que las personas utilizan cada vez más sus identidades en las redes sociales para acceder a servicios y recursos, las organizaciones deben poder llegar a sus usuarios a través de cualquier plataforma. Además, pueden permitir que sus usuarios accedan a los sistemas corporativos a través de sus identidades digitales existentes.
La gestión de identidades también se puede utilizar para mejorar la productividad de los empleados. Esto es especialmente importante cuando se incorporan nuevos empleados o se cambian las autorizaciones para acceder a diferentes sistemas cuando cambia la función de un empleado. Cuando las empresas contratan nuevos empleados, deben tener acceso a partes específicas de sus sistemas, proporcionarles nuevos dispositivos y aprovisionarlos en el negocio. Realizado manualmente, este proceso puede llevar mucho tiempo y reduce la capacidad de los empleados para ponerse a trabajar de inmediato. Sin embargo, el aprovisionamiento automatizado puede permitir a las empresas acelerar el proceso de permitir que los nuevos empleados accedan a las partes requeridas de sus sistemas.
Por último, la gestión de identidades puede ser una herramienta importante para mejorar la experiencia del usuario de los empleados, especialmente para reducir el impacto del caos de identidades —el estado de tener varios conjuntos de ID de usuario y contraseñas para sistemas dispares. Por lo general, las personas no pueden recordar numerosos nombres de usuario y contraseñas y preferirían usar una sola identidad para iniciar sesión en diferentes sistemas en el trabajo. El SSO y las identidades unificadas permiten a los clientes y otras partes interesadas acceder a diferentes áreas del sistema empresarial con una cuenta, lo que garantiza una experiencia de usuario perfecta.
Funciones de la administración de identidades
La gestión de identificaciones está diseñada para trabajar de la mano con los sistemas de gestión de acceso a identidades. Se centra principalmente en la autenticación, mientras que la gestión del acceso tiene como objetivo la autorización.
La gestión de ID determinará si un usuario tiene acceso a los sistemas, pero también establece el nivel de acceso y los permisos que tiene un usuario en un sistema en particular. Por ejemplo, un usuario puede tener autorización para acceder a un sistema pero estar restringido en algunos de sus componentes.
El objetivo de la gestión de identidades es garantizar que solo los usuarios autenticados tengan acceso a las aplicaciones, sistemas o entornos de TI específicos para los que están autorizados.
Ciclo de vida de la gestión de identidades
El ciclo de vida de la identidad tiene cuatro pasos principales:
Incorporación
Este primer paso es la creación de la propia identidad. Además de crear la cuenta de los usuarios, el usuario debe estar conectado a los recursos de TI a los que necesitará acceder. Estos sistemas de TI también pueden incluir su computadora de escritorio o computadora portátil, su cuenta de correo electrónico y cualquier otra aplicación que necesiten utilizar.
El acceso a la cuenta también puede extenderse a servidores u otras aplicaciones en la nube. El paso de incorporación asocia al nuevo usuario con diferentes grupos o departamentos de los que el usuario forma parte. Estas diversas designaciones pueden ayudar a garantizar los niveles adecuados de acceso.
Modificación del usuario
Con los años, los atributos de los usuarios dentro de una organización pueden cambiar. Los roles de las personas pueden cambiar, lo que requiere un aumento o una disminución en sus niveles de acceso. La información de los usuarios o su dirección y ubicación dentro de la organización también pueden cambiar con el tiempo.
Hay más actualizaciones de rutina, como el restablecimiento de contraseñas, que acaban agotando un tiempo valioso de los administradores de TI. Cada una de estas modificaciones del usuario es una parte fundamental del ciclo de vida de la identidad.
Modificaciones de los sistemas de TI
Además de las modificaciones de los usuarios de TI, ocurren cambios en los sistemas y recursos de TI de forma rutinaria. Los servidores están incluidos, las computadoras portátiles se rompen, se agregan nuevas aplicaciones a la red y los recursos cambian. Todos sus usuarios pueden necesitar acceso a esos recursos, por lo que la forma en que tu estrategia de administración de identidad se ocupa de esos cambios es fundamental. Tendrás más cambios con los recursos de TI que con los usuarios.
Cuando se combinan estas cosas, las dos pueden afectar significativamente los recursos que necesitas administrar y cómo tus usuarios se conectan a esos recursos.
Terminación de la cuenta
El último paso en el ciclo de vida de la identidad es cuando eliminas a un usuario. Es un escenario muy común porque cuando alguien abandona la organización, es necesario interrumpir todo su acceso. Varios requisitos de cumplimiento se centran en este paso fundamental, ya que las cuentas inactivas pueden representar un riesgo para la seguridad.
Desde la perspectiva de TI, eliminar el acceso a varios recursos puede ser más difícil que simplemente eliminar al usuario del directorio corporativo. Se necesita un catálogo de acceso para garantizar que el acceso a todos los recursos se haya cancelado por completo.
Pensar en identidades en el contexto de un ciclo de vida puede resultar útil. Los administradores de TI pueden dividir mejor el proceso general en áreas discretas y descubrir cómo automatizarlas. En medio de cualquier ciclo de vida de la gestión de identidades hay un sistema de directorio. La plataforma DAAS es la tienda de usuario principal que alberga sus identidades digitales y es el corazón de su ciclo de vida.
Capacidades
Las capacidades de la gestión de identidades son las siguientes:
Autenticación multifactor
Las contraseñas conllevan varias debilidades. Es importante destacar que estas incluyen ser fáciles de adivinar, ser fáciles de descifrar, ser fáciles de phishing y repetirse constantemente. Las contraseñas repetidas permiten a los piratas informáticos ingresar a múltiples servidores, bases de datos y redes. Por lo tanto, la construcción de una mayor autenticación en torno a las contraseñas debe convertirse en una consideración clave.
Si bien las empresas nunca se librarán realmente de las contraseñas, pueden complementarlas y fortalecerlas. Todos y cada uno de los factores de autenticación entre el usuario y la base de datos representan otro obstáculo para que los piratas informáticos aprovechen el poder de la autenticación multifactor (MFA). Por supuesto, con tiempo y recursos, los piratas informáticos pueden subvertir u omitir cualquier número de factores de autenticación.
Ten en cuenta que la mayoría de los piratas informáticos preferirían apuntar a empresas más débiles para obtener ganancias más rápidas. La autenticación multifactor incluirá contraseñas, tokens duros, geofencing, monitoreo del tiempo de acceso y análisis de comportamiento.
Gestión de sesiones privilegiadas
Esta administración de sesiones ofrece a tu equipo de seguridad de la información la capacidad de monitorizar y grabar sesiones privilegiadas. Por lo tanto, les brinda una mejor ventana para auditar e investigar incidentes de ciberseguridad. Te ayuda a exhibir control sobre sus identidades privilegiadas.
La sofisticada administración de sesiones privilegiadas de próxima generación debería permitirte observar la fecha, la hora y la ubicación de cada sesión y hacer que tengas visibilidad sobre tus propias pulsaciones de teclas para garantizar la autenticidad de cada usuario privilegiado.
Esto evitará las amenazas internas y los piratas informáticos al asegurarse de que los usuarios usen sus permisos de acuerdo con los procesos comerciales.
● Descubrimiento de la identidad privilegiada
Muchas identidades privilegiadas pueden desaparecer de su supervisión. Esto ocurre debido al escalado de las redes o una mala salida. Una vez más, el permiso temporal no puede revocarse después de una línea de tiempo puntual, lo que deja a los usuarios con identidades privilegiadas pero sin supervisión.
Todas las identidades privilegiadas no supervisadas se convierten en cuentas huérfanas y, por lo tanto, en vulnerabilidades de seguridad. Este es otro efecto secundario de administrar manualmente las identidades con privilegios; tratar de realizar un seguimiento de todo en una hoja de cálculo está condenado al fracaso.
Beneficios del ID Management
Las tecnologías de ID Management se pueden utilizar para iniciar, capturar, registrar y administrar las identidades de los usuarios y sus permisos de acceso relacionados de manera automatizada. Esto brinda a una organización los siguientes beneficios:
Los privilegios de acceso se otorgan de acuerdo con la política, y todas las personas y servicios están debidamente autenticados, autorizados y auditados. Las empresas que gestionan adecuadamente las identidades tienen un mayor control del acceso de los usuarios, lo que reduce el riesgo de filtraciones de datos internos y externos. La automatización de los sistemas IAM permite a las empresas operar de manera más eficiente al disminuir el esfuerzo, el tiempo y el dinero que se requerirían para administrar manualmente el acceso a sus redes. En términos de seguridad, el uso de un marco de IAM puede facilitar la aplicación de políticas en torno a la autenticación, la validación y los privilegios de los usuarios, y abordar los problemas relacionados con la filtración de privilegios. Los sistemas IAM ayudan a las empresas a cumplir mejor con las regulaciones gubernamentales permitiéndoles mostrar que la información corporativa no se está utilizando indebidamente. Las empresas también pueden demostrar que los datos necesarios para la auditoría pueden estar disponibles bajo demanda. Las empresas pueden obtener ventajas competitivas implementando herramientas IAM y siguiendo las mejores prácticas relacionadas. Por ejemplo, las tecnologías IAM permiten a la empresa brindar a los usuarios externos a la organización, como clientes, socios, contratistas y proveedores, acceso a su red a través de aplicaciones móviles, aplicaciones locales y SaaS sin comprometer la seguridad. Esto permite una mejor colaboración, mayor productividad, mayor eficiencia y menores costes operativos.
Diferencias entre gestión de identidad y gestión de acceso
En pocas palabras, la gestión de identidades gestiona las identidades digitales. Las identidades combinan atributos digitales y entradas en la base de datos para crear una designación única para un usuario. Su gestión consiste en crear, mantener, monitorizar y eliminar esas identidades mientras operan en la red empresarial. Las empresas deben asegurarse de que los usuarios tengan los permisos que necesitan para realizar su trabajo y limitar otros permisos. Además, maneja la autenticación.
Mientras tanto, la gestión de acceso controla la decisión de permitir o bloquear a los usuarios el acceso a un recurso, base de datos, etc. Además, gestiona los portales de acceso a través de páginas y protocolos de inicio de sesión, al tiempo que garantiza que el usuario que solicita el acceso realmente pertenece. En realidad, esto difiere de la autenticación, ya que la autenticación puede determinar al usuario, pero no si merece acceso. En cambio, gestiona la autorización.
La autenticación no es igual a la autorización y viceversa. El primero, una provincia de la gestión de identidades, determina quién es el usuario, ya sea en función de grupos, roles u otras cualidades. La autorización evalúa al usuario para determinar lo que el usuario realmente puede ver y acceder después de la autenticación.
La razón por la que estos dos conceptos se confunden es que son dos pasos críticos para un usuario que accede a la información. La información proporcionada por la gestión de identidad determina cómo funcionará la gestión de acceso. Dado que los usuarios solo ingresan información de identidad, no se dan cuenta de que existe un sistema de gestión completamente diferente para establecer su acceso. La identidad y el acceso están tan estrechamente vinculados que puede resultar difícil recordar que no son lo mismo.
Implantando identidades
Nuestro ayuntamiento quiere organizar la gestión de identidades del personal, por lo que vamos a explorar bajo este supuesto cómo podríamos hacerlo.
Para hacerlo lo haremos en 4 sencillos pasos:
1) Evaluación:
Recopilación del estado de madurez que posee el ayuntamiento en torno a la gestión de identidades, con uso o no de tecnología.
Definición del modelo actual y futuro para una próxima fase de Gestión de Identidades.
Creación del modelo personalizado que la empresa necesita para adoptar el manejo de identidades.
2) Despligue:
Análisis y diseño del proyecto de administración de identidades.
Desarrollo del proceso basado en el nuevo modelo.
Implementación de la solución.
3) Monitorización:
Crear un proceso de transferencia de conocimiento al cliente, para operar y mejorar su solución.
Monitorización de la solución durante el proceso de transferencia.
Solución de soporte a 3 niveles.
Proporcionar servicios gestionados si es necesario.
4) Proceso de madurez:
Reevaluación para dirigir los pasos a seguir.
Proporcionar mejora continua.
Proporcionar un modelo flexible para mantener la solución útil.
Con estos pasos podríamos plantear la administración y gestión de identidades, si bien parece sencillo, en la realidad no lo es.
Lo que tenemos que tener siempre bien claro es que “Una brecha de seguridad empieza con una identidad comprometida, sin control y sin mecanismos de regulación”
Dentro de la evolución del IAM podemos encontrar 3 niveles de madurez. En el siguiente gráfico se ve claramente sus diferencias.
Conclusión:
Recuerda los 4 puntos para la gestión de identidades dentro de tu organización. La fase fundamental es la de evaluación, ya que deberás de enumerar todos los sistemas de gestión de identidad que tiene la organización. Desde el acceso presencial, registro horario, autenticación contra un sistema de LDAP, claves de alarma, etc. Deberás de realizar un inventario completo. Como observarás muchos de estos sistemas, son sistemas aislados, es decir no están integrados entre sí. Por lo que deberás de crear rutinas para controlarlos y verificar que en todo momento cumplen todos los requisitos de seguridad fijados por la organización.
Conclusión
Como hemos podido ver, la gestión de identidad es clave para una organización y es quizás uno de los principales puntos que debe abordar cualquier política de gobierno IT. Estableciendo la forma en cómo se autentican los usuarios de una organización y controlando el ciclo de vida de cada una de las identidades.
El “Diseño Inseguro” es una vulnerabilidad incluida en el OWASP Top 10 2022. Se refiere a las debilidades en el diseño y arquitectura de una aplicación web que pueden permitir a los atacantes aprovechar vulnerabilidades y acceder a información confidencial o realizar acciones maliciosas. Estas debilidades pueden ser causadas por una falta de consideración de seguridad en el diseño o una falta de comprensión de las implicaciones de seguridad de las tecnologías utilizadas.
Algunos ejemplos de debilidades de diseño inseguro incluyen:
Falta de validación de entrada: Una aplicación que no valida adecuadamente los datos de entrada puede ser vulnerable a ataques de inyección de código.
Falta de autenticación y autorización: Una aplicación que no implementa adecuadamente las medidas de autenticación y autorización puede permitir a los atacantes acceder a información confidencial o realizar acciones maliciosas.
Falta de cifrado de datos sensibles: Una aplicación que no cifra adecuadamente los datos sensibles puede ser vulnerable al robo de datos.
Falta de protección contra ataques de fuerza bruta: Una aplicación que no implementa medidas de protección contra ataques de fuerza bruta puede ser vulnerable a la adivinación de contraseñas.
Falta de gestión adecuada de excepciones: Una aplicación que no maneja adecuadamente las excepciones puede revelar información confidencial sobre la implementación de la aplicación, lo que puede ayudar a los atacantes a encontrar vulnerabilidades.
Falta de protección contra ataques de denegación de servicio: Una aplicación que no está protegida contra ataques de denegación de servicio puede ser bloqueada o inutilizada por un atacante.
Falta de consideración de seguridad en la arquitectura: Una aplicación que no ha sido diseñada con seguridad en mente puede ser vulnerable a ataques debido a la falta de controles de seguridad adecuados en diferentes capas de la arquitectura.
Falta de consideración de seguridad en las tecnologías utilizadas: Una aplicación que utiliza tecnologías que no son seguras puede ser vulnerable a ataques debido a las debilidades inherentes a esas tecnologías.
Para protegerse contra las debilidades de diseño inseguro, es importante incluir la seguridad en todas las etapas del desarrollo de una aplicación, desde el diseño hasta la implementación y el mantenimiento. Esto incluye la realización de revisiones de seguridad en el código, la implementación de medidas de seguridad adecuadas, como la autenticación y autorización, el cifrado de datos sensibles, la protección contra ataques de inyección y de denegación de servicio, y la gestión adecuada de excepciones. Además, es importante considerar la seguridad en la arquitectura de la aplicación y asegurar que se están utilizando tecnologías seguras.
Configuración Incorrecta de la Seguridad
La “Configuración Incorrecta de la Seguridad” hace referencia a las debilidades en la configuración de los sistemas de seguridad de una aplicación web que pueden permitir a los atacantes aprovechar vulnerabilidades y acceder a información confidencial o realizar acciones maliciosas. Estas debilidades pueden ser causadas por una mala configuración, una falta de comprensión de las implicaciones de seguridad de las tecnologías utilizadas o una falta de mantenimiento regular de los sistemas de seguridad.
Algunos ejemplos de debilidades de configuración incorrecta de la seguridad incluyen:
Servicios o aplicaciones innecesarios habilitadas: Un sistema que tiene servicios o aplicaciones innecesarias habilitadas es más vulnerable a ataques ya que ofrece más puntos de entrada para los atacantes.
Contraseñas débiles o predeterminadas: Un sistema que utiliza contraseñas débiles o predeterminadas es más vulnerable a ataques ya que los atacantes pueden adivinar fácilmente las contraseñas.
Puertos abiertos innecesarios: Un sistema que tiene puertos abiertos innecesarios es más vulnerable a ataques ya que los atacantes pueden utilizar estos puertos para acceder al sistema.
Falta de actualizaciones de seguridad: Un sistema que no recibe actualizaciones de seguridad es más vulnerable a ataques ya que las debilidades conocidas no están siendo corregidas.
Falta de monitoreo y registro: Un sistema que no tiene monitoreo y registro adecuado es más vulnerable a ataques ya que no se pueden detectar y responder a los incidentes de seguridad de manera efectiva.
Falta de configuración segura en dispositivos: Un dispositivo que no está configurado de manera segura puede ser vulnerable a ataques debido a la falta de controles de seguridad adecuados.
Falta de configuración segura en servidores: Un servidor que no está configurado de manera segura puede ser vulnerable a ataques debido a la falta de controles de seguridad adecuados.
Falta de configuración segura en redes: Una red que no está configurada de manera segura puede ser vulnerable a ataques debido a la falta de controles de seguridad adecuados.
Para protegerse contra las debilidades de configuración incorrecta de la seguridad, es importante asegurar que los sistemas estén configurados de manera segura y mantenidos de manera regular. Esto incluye la eliminación de servicios o aplicaciones innecesarias, la utilización de contraseñas seguras y cambiarlas regularmente, la revisión de puertos abiertos, la instalación de actualizaciones de seguridad, la implementación de monitoreo y registro adecuado, la configuración segura de dispositivos y servidores y la configuración segura de redes. Es importante también contar con un equipo de seguridad dedicado y realizar pruebas de penetración regulares para detectar y corregir las vulnerabilidades.
Componentes vulnerables y obsoletos
Los “Componentes Vulnerables y Obsoletos” se refiere a la utilización de componentes de software, tales como bibliotecas, frameworks, y aplicaciones, que contienen debilidades de seguridad conocidas y que ya no son soportadas o actualizadas. Estos componentes pueden ser utilizados en aplicaciones web y pueden ser utilizados para aprovechar vulnerabilidades y acceder a información confidencial o realizar acciones maliciosas.
Algunos ejemplos de componentes vulnerables y obsoletos incluyen:
Bibliotecas de terceros: Las bibliotecas de terceros utilizadas en una aplicación pueden contener vulnerabilidades conocidas, especialmente si estas bibliotecas ya no son soportadas o actualizadas.
Frameworks antiguos: Los frameworks antiguos utilizados en una aplicación pueden contener vulnerabilidades conocidas, especialmente si estos frameworks ya no son soportados o actualizados.
Aplicaciones obsoletas: Las aplicaciones obsoletas utilizadas en un sistema pueden contener vulnerabilidades conocidas, especialmente si estas aplicaciones ya no son soportadas o actualizadas.
Plugins y módulos obsoletos: Los plugins y módulos obsoletos utilizados en una aplicación pueden contener vulnerabilidades conocidas, especialmente si estos plugins y módulos ya no son soportados o actualizadas.
Para protegerse contra los componentes vulnerables y obsoletos, es importante mantener un inventario actualizado de todos los componentes utilizados en una aplicación y asegurar que estos componentes estén soportados y actualizados. También es importante monitorear regularmente los componentes para detectar cualquier debilidad conocida. Además, es recomendable utilizar solo componentes de software de proveedores confiables y revisar regularmente las alertas de seguridad.
Fallos de identificación y autenticación
Los “Fallos de Identificación y Autenticación” se definen como debilidades en el proceso de identificación y autenticación de una aplicación web que pueden permitir a los atacantes acceder a información confidencial o realizar acciones maliciosas. Estas debilidades pueden ser causadas por una mala implementación de las medidas de identificación y autenticación, una falta de comprensión de las implicaciones de seguridad de las tecnologías utilizadas o una falta de mantenimiento regular de los sistemas de identificación y autenticación.
Algunos ejemplos de fallos de identificación y autenticación incluyen:
Contraseñas débiles o predeterminadas: Un sistema que utiliza contraseñas débiles o predeterminadas es más vulnerable a ataques ya que los atacantes pueden adivinar fácilmente las contraseñas.
Falta de autenticación de dos factores: Un sistema que no implementa autenticación de dos factores es más vulnerable a ataques ya que un atacante puede acceder a la cuenta utilizando solo un factor de autenticación.
Falta de mecanismos de bloqueo de cuenta: Un sistema que no tiene mecanismos de bloqueo de cuenta es más vulnerable a ataques ya que un atacante puede intentar varios intentos de inicio de sesión fallidos.
Falta de registro de inicios de sesión: Un sistema que no registra los inicios de sesión es más vulnerable a ataques ya que no se puede rastrear quién ha accedido a la cuenta y desde dónde.
Falta de control de acceso: Un sistema que no tiene un control de acceso adecuado es más vulnerable a ataques ya que cualquier persona puede acceder a información confidencial.
Para protegerse contra los fallos de identificación y autenticación, es importante asegurar que los sistemas estén configurados de manera segura y mantenidos de manera regular. Esto incluye la utilización de contraseñas seguras y cambiarlas regularmente, la implementación de autenticación de dos factores, la implementación de mecanismos de bloqueo de cuenta, el registro de inicios de sesión, y el control de acceso adecuado. También es importante educar a los usuarios sobre la importancia de utilizar contraseñas seguras y evitar compartirlas. Es recomendable también utilizar herramientas de seguridad para detectar y prevenir ataques de fuerza bruta y phishing. Es importante también contar con un equipo de seguridad dedicado y realizar pruebas de penetración regulares para detectar y corregir las vulnerabilidades. Es importante también educar a los empleados y usuarios finales sobre los riesgos de los fallos de identificación y autenticación y cómo detectarlos y evitarlos. Además, es recomendable utilizar herramientas de detección y prevención de ataques para detectar y bloquear intentos de modificación de datos maliciosos. Es importante también mantener actualizado el software y el sistema operativo para evitar debilidades conocidas. Por último es importante tener un plan de recuperación de desastres en caso de pérdida de información crítica.
Fallas de Integridad de Software y Datos
Las “Fallas de Integridad de Software y Datos” se refieren a las debilidades en la integridad de la información almacenada y procesada en una aplicación web que pueden permitir a los atacantes modificar, destruir o alterar información de manera maliciosa. Estas debilidades pueden ser causadas por una mala implementación de las medidas de seguridad, una falta de comprensión de las implicaciones de seguridad de las tecnologías utilizadas o una falta de mantenimiento regular de los sistemas.
Algunos ejemplos de fallas de integridad de software y datos incluyen:
Inyección de código: Una aplicación que no está protegida contra la inyección de código puede permitir a un atacante modificar la información almacenada o ejecutar código malicioso.
Ataques de modificación de datos: Una aplicación que no está protegida contra ataques de modificación de datos puede permitir a un atacante modificar información de manera maliciosa.
Ataques de denegación de servicio: Una aplicación que no está protegida contra ataques de denegación de servicio puede ser inutilizada por un atacante y causar la pérdida de información.
Falta de control de acceso: Un sistema que no tiene un control de acceso adecuado es más vulnerable a ataques ya que cualquier persona puede acceder a información confidencial y modificar o destruirla.
Falta de copias de seguridad: Un sistema que no tiene copias de seguridad adecuadas es más vulnerable a ataques ya que si la información es destruida o modificada de manera maliciosa, no se tiene una forma de recuperarla.
Falta de validación de entrada: Una aplicación que no valida adecuadamente las entradas de datos puede permitir a un atacante insertar información maliciosa o modificar la información existente.
Falsificación de solicitud del lado del servidor(SSRF)
La “Falsificación de Solicitud del Lado del Servidor” es una vulnerabilidad incluida en el OWASP Top 10 2022. Se refiere a la posibilidad de que un atacante modifique la información en una solicitud realizada al servidor, lo que puede permitirle acceder a información confidencial o realizar acciones maliciosas. Esta vulnerabilidad puede ser causada por una mala implementación de las medidas de seguridad, una falta de comprensión de las implicaciones de seguridad de las tecnologías utilizadas o una falta de mantenimiento regular de los sistemas.
La falsificación de solicitud del lado del servidor puede manifestarse de varias maneras, algunos ejemplos son:
Ataques de inyección de código: Una aplicación que no está protegida contra la inyección de código puede permitir a un atacante modificar la información en una solicitud al servidor.
Ataques de modificación de datos: Una aplicación que no está protegida contra ataques de modificación de datos puede permitir a un atacante modificar información en una solicitud al servidor de manera maliciosa.
Ataques de suplantación de identidad: Una aplicación que no está protegida contra ataques de suplantación de identidad puede permitir a un atacante falsificar información en una solicitud al servidor para acceder a información confidencial o realizar acciones maliciosas.
Es importante asegurar que los sistemas estén configurados de manera segura y mantenidos de manera regular. Esto incluye la implementación de medidas de seguridad como la protección contra inyección de código, la validación adecuada de entradas de datos, y la implementación de mecanismos de autenticación y autorización fuertes.
Conclusiones
Como podemos observar, muchas de las fallas se repiten en diferentes posiciones del TOP, y esto es necesario puesto que una vulnerabilidad puede deberse a diversos factores. También es importante recalcar la educación en cada uno de los aspectos del personal, sobre todo en aquellos apartados que incluyen a personal no técnico, ya que su consciencia sobre el tema no será la misma que un empleado de TI.